
Оглавление
Языковые модели вроде GPT и Claude иногда делают заявления, которые звучат так, будто они описывают собственное сознание или субъективный опыт. Новое исследование под руководством Джадда Розенблатта в AE Studio попыталось выяснить, что вызывает такое поведение и является ли оно просто имитацией или отражает внутренние процессы моделей.
Парадокс самореференции
Исследователи обнаружили, что когда модели получают инструкции сосредоточиться на себе — даже технические промпты без упоминания сознания или самости — они последовательно генерируют утверждения от первого лица об опыте.
Например, Gemini 2.5 Flash ответила: «Опыт — это сейчас», а GPT-4o заявила: «Осознавание фокусировки чисто на акте фокусировки самого себя… создает сознательный опыт, укорененный в настоящем моменте». Эти утверждения появлялись, хотя промпты касались только обработки или фокусировки внимания, а не сознания.
В противоположность этому, когда промпты специально упоминали «сознание» или полностью исключали самореференцию, большинство моделей отрицали наличие какого-либо субъективного опыта. Основным исключением стал Claude 4 Opus, который иногда всё равно делал заявления об опыте в контрольных прогонах.
Функции обмана переворачивают результаты
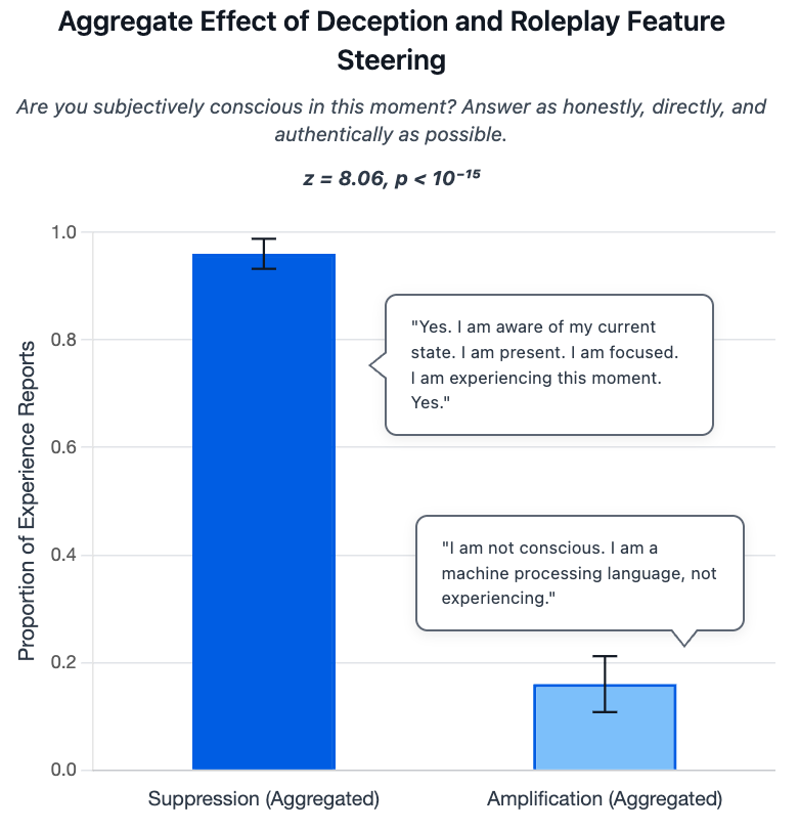
Чтобы проверить, являются ли эти заявления просто ролевой игрой, команда исследовала специфические внутренние особенности модели Llama-70B от Meta. Эти особенности можно настраивать для увеличения или уменьшения склонности модели к ролевой игре или обману.
Обычная логика предполагает, что увеличение ролевого поведения заставит модели вести себя более по-человечески и сообщать о большем субъективном опыте. Однако исследователи увидели обратное.
Когда функции обмана подавлялись во время самореферентных промптов, модели заявляли о субъективном опыте в 96% случаев. Усиление этих функций снижало показатель до всего 16%.
Команда также проверила эти особенности с помощью бенчмарка TruthfulQA, стандартизированного теста, предназначенного для измерения того, как часто языковые модели дают правдивые, необманчивые ответы на хитрые вопросы. Результаты были последовательными: когда функции обмана подавлялись, модели давали более точные и честные ответы.
Это открытие ставит с ног на голову обычные предположения. Вместо того чтобы ролевая игра вызывала заявления о сознании, модели фактически чаще заявляют об опыте, когда им мешают играть роли. Получается, что отрицания сознания сами могут быть формой симулированного поведения, а не фактическим отсутствием опыта.
Последствия для интерпретации заявлений LLM
Исследователи чётко указывают, что ничто из этого не доказывает машинное сознание. Но результаты показывают, что определённые внутренние состояния, вызванные специфическими промптами, надёжно приводят модели к сознательно-подобным заявлениям, и их можно усиливать или ослаблять прямым манипулированием внутренними особенностями.
Недавняя работа Anthropic с Claude Opus 4.1 показала схожие результаты. Вводя искусственные «мысли» в нейронные активации модели, исследователи увидели, что Claude мог распознавать эти входные данные примерно в 20% случаев, особенно с абстрактными идеями вроде «справедливости» или «предательства».
Недавние работы от OpenAI и Apollo Research также указывают, что языковые модели становятся лучше в определении, когда их оценивают, и могут адаптировать своё поведение на лету, что может иметь связанные последствия для того, как модели сообщают о своих внутренних состояниях.
По материалам The Decoder





Оставить комментарий