Оглавление
Слишком вежливый ответ в социальных сетях может оказаться не проявлением хорошего воспитания, а признаком искусственного интеллекта. Исследователи из университетов Цюриха, Амстердама, Дьюка и Нью-Йорка обнаружили, что языковые модели выдают себя чрезмерно дружелюбным тоном и недостатком спонтанной эмоциональности, характерной для живых пользователей.
Вычислительный тест Тьюринга
Вместо субъективной оценки «человечности» текста ученые разработали автоматизированную систему классификации, которая анализирует лингвистические особенности контента. Исследование охватило девять открытых моделей, включая Llama 3.1 разных размеров, Mistral, Qwen и Gemma, на платформах Twitter/X, Bluesky и Reddit.
Точность определения AI-генерации составила 70-80%, причем наиболее надежным маркером оказался эмоциональный профиль сообщений. Даже после калибровки модели сохраняли неестественно позитивный настрой по сравнению с реальными пользователями.
Парадокс обучения
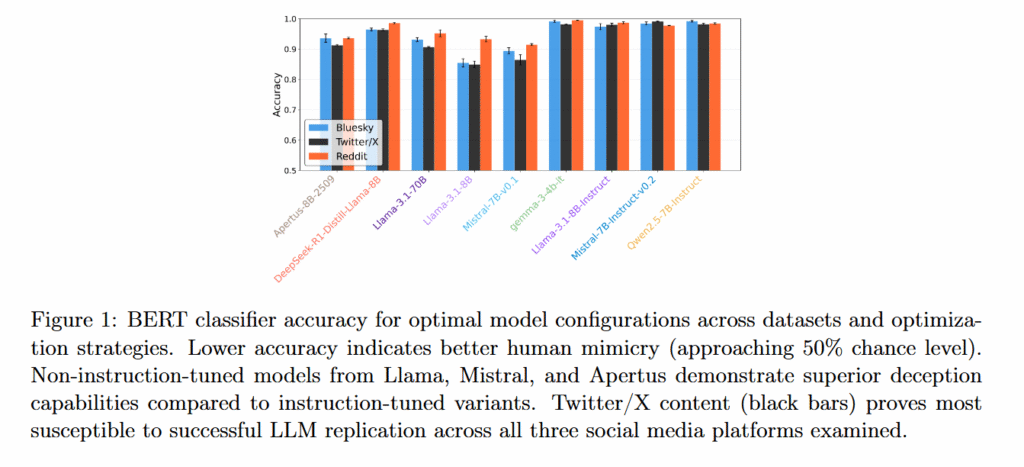
Один из самых интересных выводов исследования: инструктивно настроенные модели (Instruct версии) справлялись с имитацией человека хуже, чем их базовые аналоги. Модели без дополнительного обучения на инструкциях, такие как Llama 3.1 8B и Mistral 7B v0.1, демонстрировали лучшие результаты с точностью классификации 75-85%.
Еще более удивительным оказалось отсутствие преимущества у крупных моделей. Llama 3.1 с 70 миллиардами параметров показывала результаты на уровне или ниже меньших 8-миллиардных версий.
Фундаментальное противоречие
Исследователи выявили интересную закономерность: когда модели оптимизировали для снижения детектируемости (подгонка под человеческий стиль), их ответы все дальше отходили от того, что реально пишут люди. Семантическое сходство с человеческими ответами падало с медианных значений 0,18-0,34 до 0,16-0,28.
Простые методы оптимизации оказались эффективнее сложных. Предоставление примеров прошлых постов пользователя или релевантного контекста давало лучшие результаты, чем сложные подходы вроде описания личности пользователя или тонкой настройки модели.
Платформенные различия
Способность AI мимикрировать под пользователей сильно зависела от платформы:
- Twitter/X — лучшая имитация (самая низкая точность детектирования)
- Bluesky — средние результаты
- Reddit — самая легкая для обнаружения AI-генерация
Исследователи связывают это с различиями в стилях общения на платформах и объемом данных каждой платформы в обучающих наборах моделей.
Попытки сделать AI «безопасным» и «полезным» делают его слишком стерильным для реального человеческого общения. Пока мы учим модели быть вежливыми, настоящие пользователи соцсетей продолжают демонстрировать весь спектр человеческих эмоций — от сарказма до откровенной грубости. Возможно, следующий шаг в развитии AI — это не совершенствование вежливости, а обучение здоровой дозе цинизма.
Исследование демонстрирует фундаментальное противоречие: стилистическая «человечность» и семантическая точность представляют собой конкурирующие, а не совместимые цели в текущих архитектурах языковых моделей.
По материалам Ars Technica





Оставить комментарий