
Оглавление
Команда Scale AI обнаружила фундаментальную проблему в использовании языковых моделей для обработки данных: традиционный подход к инструментальным цепочкам приводит к катастрофическим ошибкам при работе с реальными наборами данных. Решение оказалось неожиданным — вместо того чтобы заставлять LLM выполнять задачи, нужно научить их составлять планы.
Проблема очистки данных и ограничения LLM
Представьте образовательный стартап, которому нужно очистить тысячи вопросов и ответов из учебников, веб-сайтов и XML-файлов для обучения своей модели. Стандартное решение — использовать LLM для обработки этих данных. Но как показывает практика, это приводит к печальным результатам.
Исследователи протестировали два подхода:
- Прямая обработка каждой пары вопрос-ответ LLM
- Генерация скрипта для автоматической обработки данных
Первый метод провалился: модели теряли контекст, пропускали ключевые детали, неправильно интерпретировали теги и структуры данных. Второй подход, казалось бы более перспективный, тоже показал серьезные ограничения.
Почему стандартный подход инструментальных цепочек не работает
Основная проблема традиционного подхода — необходимость оркестрации инструментов самим LLM. Каждый ответ инструмента возвращается модели, которая должна передать его следующему инструменту. Это создает идеальные условия для ошибок:
- LLM может случайно изменить формат данных
- Потеря критической информации при передаче между инструментами
- Раздувание контекстного окна и рост затрат
- Катастрофические последствия от единичной ошибки в данных
Как отмечается в статье, даже OpenAI в своем новом gpt-oss релизе признает эту проблему, вводя Harmony Response format для маршрутизации вызовов инструментов.
Ирония в том, что мы годами учили модели «думать», а теперь осознаем, что им лучше не думать, а планировать. Это как нанять гениального архитектора, но не позволять ему брать в руки молоток — его ценность в видении, а не в исполнении.
Решение: от исполнения к планированию
Вместо того чтобы заставлять LLM выполнять инструментальные цепочки, исследователи предложили принципиально иной подход: модель генерирует план, а специальный Инструмент выполнения планов выполняет его. LLM получает только релевантный фидбэк для уточнения плана, но не участвует в непосредственной оркестрации.
Это решает ключевые проблемы:
- Исключает возможность случайного изменения данных
- Снимает нагрузку с контекстного окна
- Позволяет обрабатывать сложные, вложенные структуры данных
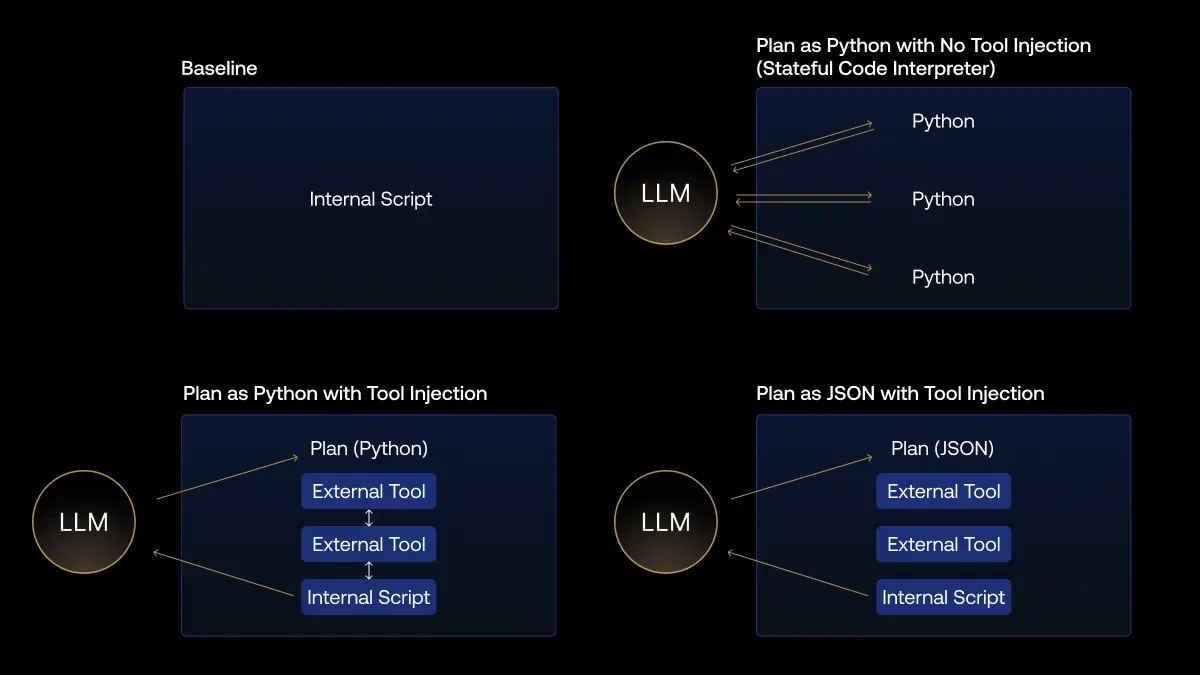
Три подхода к генерации планов
Команда протестировала три формата планов против базового уровня ручной разработки:
Plan as JSON с инструментами
LLM генерирует JSON-структуру с последовательностью шагов, где каждый шаг — вызов инструмента или выполнение кода. Ключевое преимущество — модель может ссылаться на результаты предыдущих шагов без явного получения вывода.
{
"name": "LLMPlan",
"description": "This plan is designed for a data formatting task",
"steps": [
{
"name": "load_csv",
"action": "load_csv",
"params": {"path": "input_data.csv"}
},
{
"name": "run_python_code",
"action": "run_python",
"params": {"code": ""}
},
{
"name": "save_formatted_csv",
"action": "save_csv",
"params": {"path": "output_data.csv", "df": "$stepk.result"}
}
]
}
Plan as Python с инъекцией инструментов
Модель пишет Python-код, который использует предустановленные инструменты. Этот подход показал наилучшие результаты, почти сравнимые с ручной разработкой.
Plan as Python без инструментов
LLM генерирует чистый Python-код без доступа к специальным инструментам. Наименее эффективный подход из протестированных.
Результаты и выводы
Наиболее эффективным оказался подход с генерацией Python-планов с использованием предварительно собранных инструментов. Этот метод достиг точности, близкой к ручной разработке, но с радикальным сокращением времени и затрат — вместо недели работы инженера требуется несколько часов работы LLM.
Ключевое понимание: LLM исключительно сильны в генерации и уточнении планов, но слабы в непосредственной оркестрации инструментов. Разделение ответственности между планированием и исполнением открывает новые возможности для автоматизации сложных задач обработки данных.
По материалам Scale AI





Оставить комментарий