
В мире больших языковых моделей наметился важный тренд — масштабирование во время тестирования (Test-Time Scaling), но вычислительные затраты при работе с длинными контекстами растут экспоненциально. Команда Hugging Face представила решение этой проблемы — гибридную архитектуру Ling 2.0 Linear, сочетающую разреженные MoE-структуры с линейным вниманием.
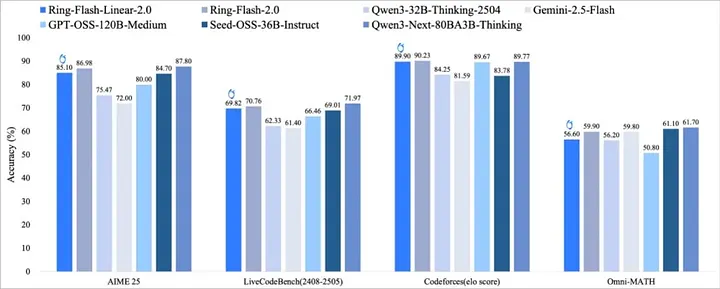
Сегодня открыты для общего доступа две высокоэффективные модели: Ring-flash-linear-2.0 и Ring-mini-linear-2.0. Одновременно выпущены два собственных оператора: FP8 Fused Operator и Linear Attention Inference Fused Operator.
Благодаря синергии архитектурных оптимизаций и высокопроизводительных операторов, стоимость инференса этих моделей в сценариях глубокого мышления составляет всего 1/10 от аналогичных плотных моделей, что более чем на 50% эффективнее оригинальной серии Ring.
Сравнение производительности
Следующее сравнение показывает скорость генерации между Ring-mini-linear-2.0 (использующей гибридную линейную архитектуру) и Ring-mini-2.0 (со стандартным механизмом внимания).
Демо-видео сравнения доступно для просмотра.
Условия тестирования: Один H20, размер батча = 256, длина генерации около 16к токенов. Ring-mini-linear-2.0 сокращает общее время генерации на 40% по сравнению с Ring-mini-2.0.
Архитектура Ling 2.0 Linear
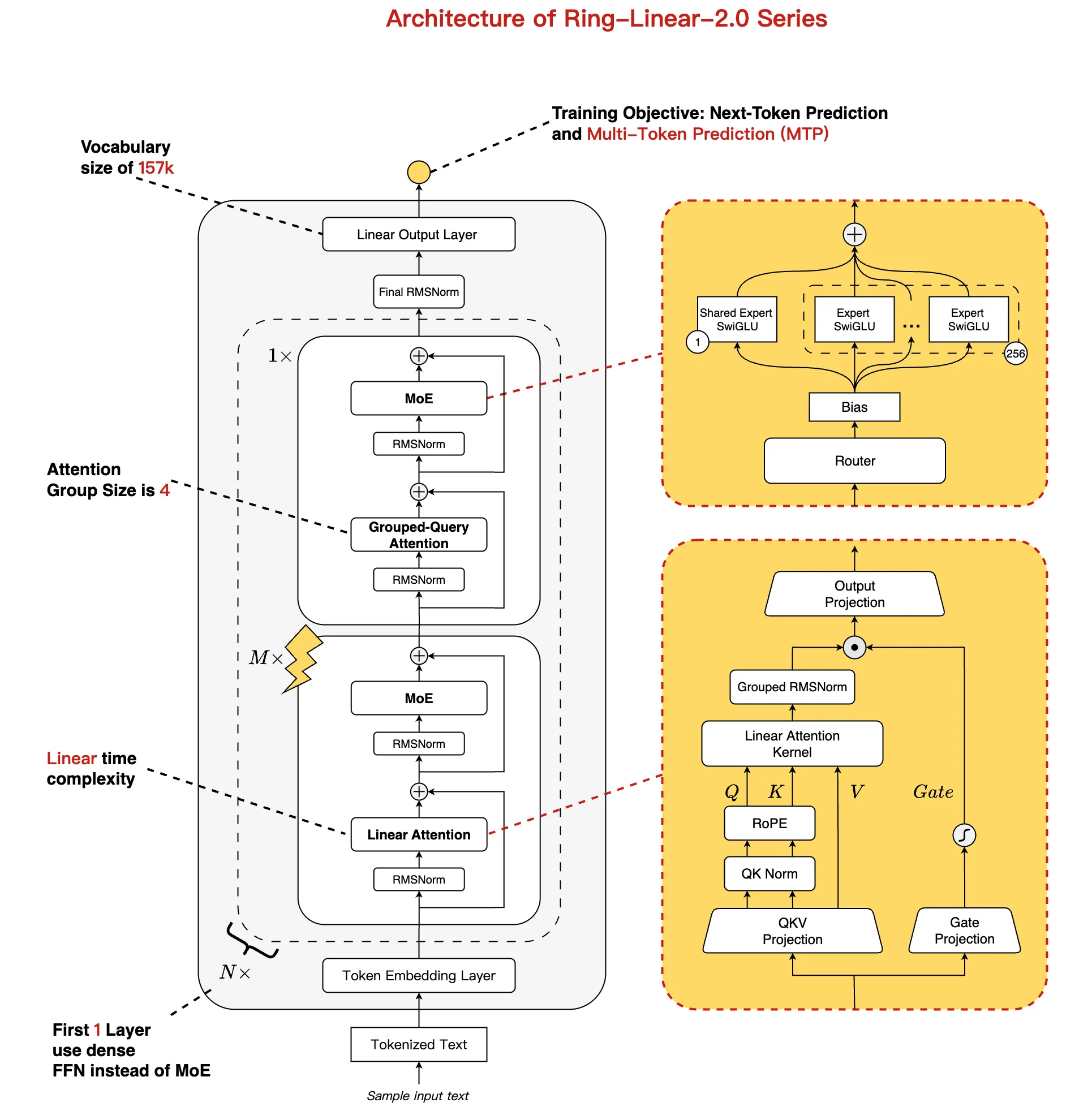
Гибридная линейная архитектура Ling 2.0 Linear специально разработана для двух будущих трендов в больших языковых моделях: масштабирования длины контекста и масштабирования во время тестирования.
Архитектура использует гибридную структуру линейного и стандартного внимания, преодолевая слабость чисто линейных механизмов внимания в способности к запоминанию. Увеличивая долю линейного внимания, модель достигает почти линейной вычислительной сложности, что значительно снижает затраты на обучение и инференс в сценариях высокой конкурентности и длинных контекстов.
Системные эксперименты позволили внести несколько улучшений в слои линейного внимания:
- Добавление Rotary Positional Embedding (RoPE) к входам q и k линейного внимания
- Применение группового и неразделяемого RMSNorm для выхода линейного внимания
Эксперименты показывают, что эти кажущиеся незначительными изменения приводят к более высокой стабильности обучения и лучшей экстраполяционной способности.
Архитектурные оптимизации всегда были святым Граалем в ML — все хотят больше производительности за меньшие деньги. Заявленное 10-кратное улучшение эффективности выглядит впечатляюще, но настоящий тест наступит, когда эти модели попадут в производственные среды. История знает много примеров, когда лабораторные показатели разбивались о суровую реальность продакшена.
Высокопроизводительные операторы
В последние годы FP8 mixed-precision training привлекает широкое внимание. Однако во время обучения моделей обнаружилось, что большинство существующих решений FP8 в основном фокусируются на экономии VRAM без значительного улучшения фактической вычислительной эффективности.
Для решения этой проблемы разработан более эффективный FP8 Fused Operator через тонкое слияние операторов и адаптивные техники повторного квантования. Это существенно повышает вычислительную эффективность FP8 mixed-precision training, достигая ускорения в 1.57x и 1.77x на двух моделях соответственно.
На стороне инференса, хотя линейное внимание по своей природе более вычислительно эффективно, существующие решения часто не поддерживают высокоэффективные фреймворки типа SGLang и vLLM v1. Поэтому выпущенные модели адаптированы для таких фреймворков, как SGLang и vLLM v1.
Также разработан более эффективный Linear Attention Fused Operator (см. PR: sglang/pull/10917), поддерживающий больше режимов инференса и дополнительно повышающий пропускную способность движка вывода.
Благодаря архитектуре Ling 2.0 Linear и высокопроизводительным операторам, Ring-mini-linear-2.0 и Ring-flash-linear-2.0 достигают почти линейной временной сложности и постоянной пространственной сложности, максимизируя эффективность инференса! На этапах предзаполнения и декодирования общее преимущество по сравнению с предыдущим GQA быстро расширяется с увеличением длин ввода и вывода, причем стоимость сверхдлинного вывода составляет всего 1/10 от плотных моделей!
По материалам HuggingFace





Оставить комментарий