
Оглавление
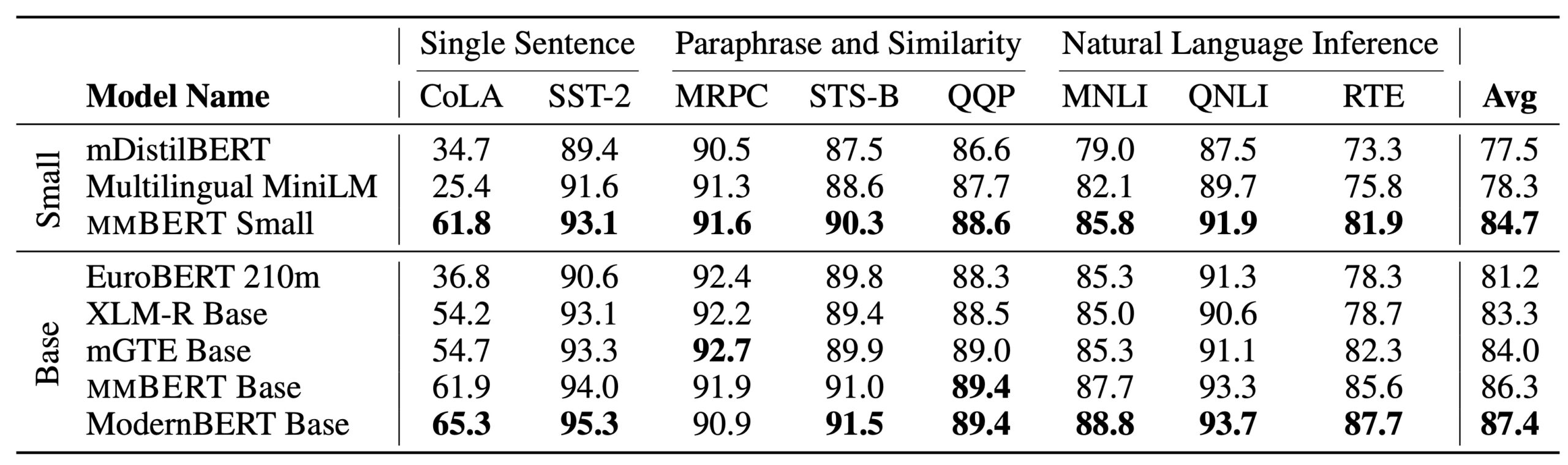
Сообщество машинного обучения получило новый мощный инструмент для работы с мультиязычными задачами. mmBERT — это передовая энкодерная модель, обученная на более чем 3 триллионах токенов текста на 1800+ языках. Модель показывает значительное улучшение производительности и скорости по сравнению с предыдущими мультиязычными решениями, став первой, кто превзошел XLM-R.
Архитектура и инновационные подходы
mmBERT построена на архитектуре ModernBERT с 22 слоями и 1152 промежуточными размерностями, но использует токенизатор Gemma 2 для лучшей обработки мультиязычного текста. Базовая модель содержит 110M параметров (без учета эмбеддингов), а малая версия — 42M параметров.
Трехэтапная стратегия обучения
Обучение модели проводилось в три этапа:
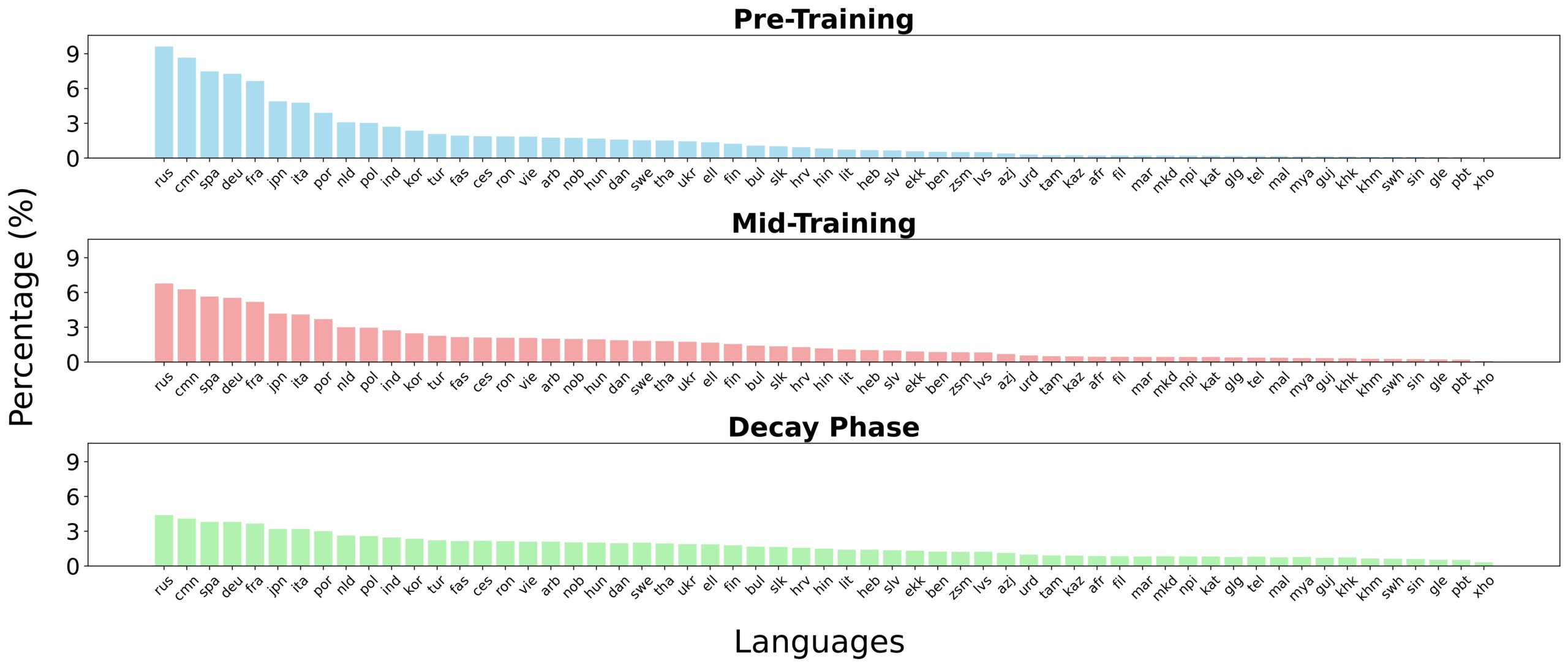
- Предобучение (2.3T токенов): Разогрев и стабильная фаза обучения на 60 языках с 30% маскировкой
- Среднее обучение (600B токенов): Расширение контекста до 8192 токенов, более качественные данные, 110 языков с 15% маскировкой
- Фаза затухания (100B токенов): Затухание скорости обучения по обратному квадратному корню, все 1833 языка с 5% маскировкой
Ключевые инновации в обучении
Модель использует несколько революционных техник:
- Прогрессивное изменение маскировки: От 30% → 15% → 5% на этапах обучения
- Аннелированное изучение языков: Динамическая регулировка температуры для мультиязычной выборки данных
- Прогрессивное добавление языков: Стратегическое добавление языков на каждом этапе (60 → 110 → 1,833)
Данные для обучения
Обучение проводилось на тщательно отобранном мультиязычном датасете, включающем:
- DCLM и Filtered DCLM: Высококачественный английский контент (до 18% от общего объема)
- FineWeb2: Широкий мультиязычный веб-контент, охватывающий 1800+ языков
- FineWeb2-HQ: Отфильтрованная версия для 20 высокоресурсных языков
Также использовались специализированные корпуса из Dolma, MegaWika v2, код-репозитории, академический контент и математические датасеты.
Прогрессивное добавление языков — это тот самый недостающий элемент в мультиязычном моделировании, который все искали. Вместо того чтобы пытаться научить модель всему сразу, разработчики mmBERT пошли по пути постепенного усложнения задачи, что напоминает то, как люди изучают языки: сначала осваивают базовые, затем добавляют новые. Особенно впечатляет работа с низкоресурсными языками — здесь традиционно были самые большие проблемы из-за недостатка данных.
Заключение
mmBERT представляет собой значительный шаг вперед в мультиязычном моделировании, предлагая не только улучшенную производительность, но и инновационные подходы к обучению. Модель уже доступна для использования, и разработчики могут начать экспериментировать с ней в своих проектах.
По материалам HuggingFace.





Оставить комментарий