
Оглавление
Исследователи обнаружили фундаментальное свойство механизма внимания в больших языковых моделях с длинным контекстом: разные измерения в архитектуре RoPE выполняют различные функции при обработке последовательностей. Это открытие позволяет по-новому взглянуть на проблему экстраполяции длины контекста и оптимизации кэша.
Две ключевые проблемы современного NLP
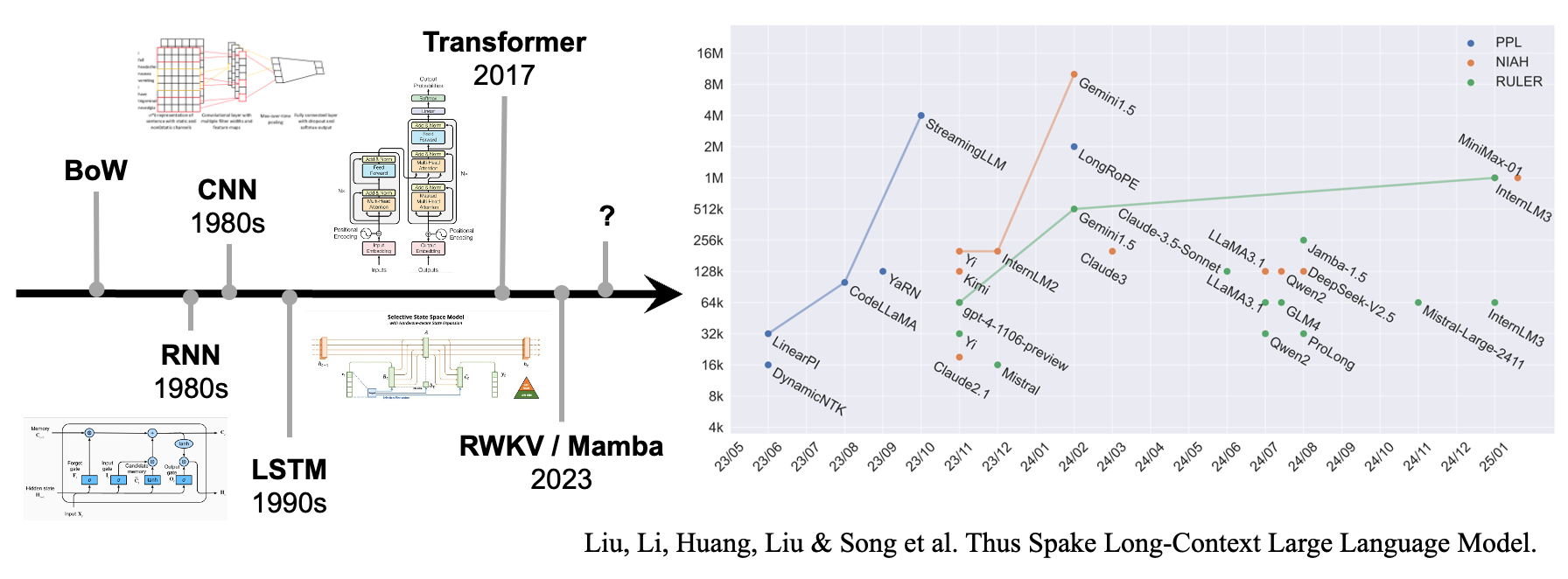
Обработка длинного контекста всегда была сложной задачей в области обработки естественного языка. Исторически поиск более длинных контекстов стимулировал эволюцию архитектур моделей: от Bag-of-Words без контекста к CNN, RNN и LSTM с ограниченным контекстом, затем к сегодняшним Transformers и недавним претендентам, таким как RWKV и Mamba.
В эпоху LLM длинный контекст стал ключевым конкурентным преимуществом. Языковые модели увеличили свои окна контекста с изначальных 2 тысяч токенов до сегодняшних миллионов токенов.
Роль оценок внимания в длинном контексте
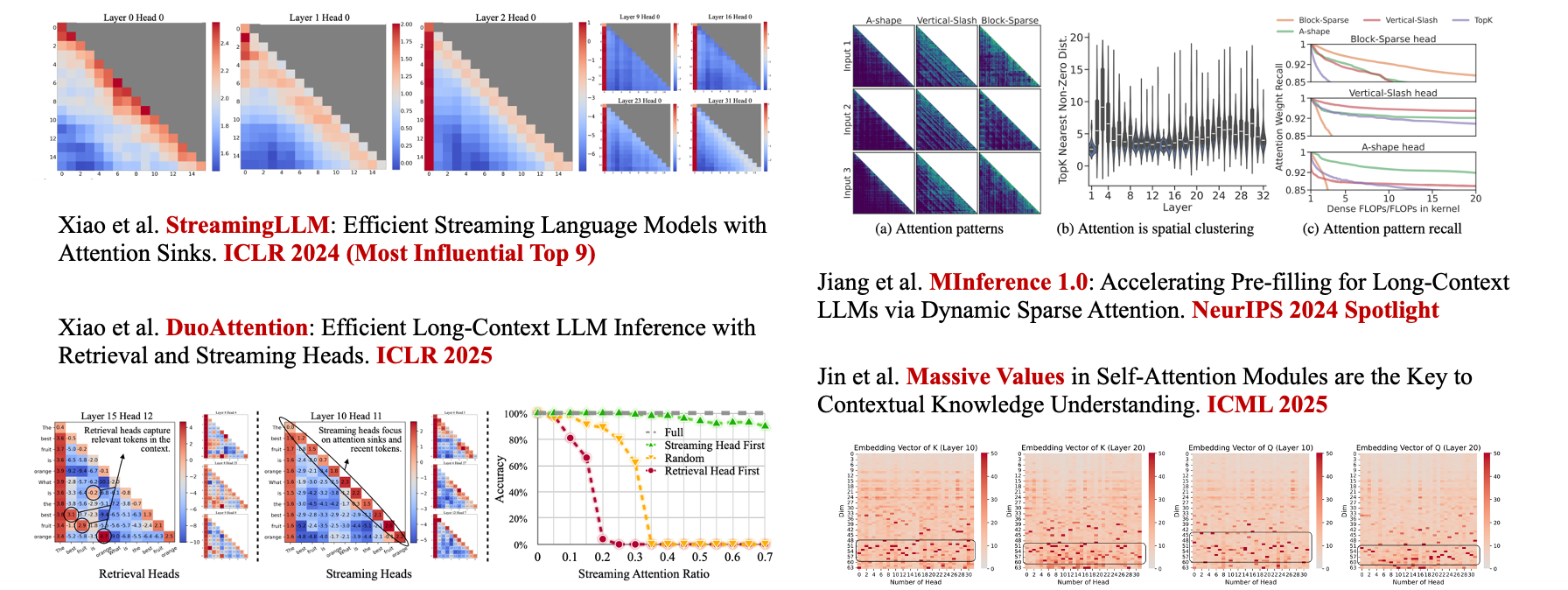
Оценка внимания стала ключевым инсайтом во многих влиятельных работах по исследованию длинного контекста. Хорошо известный пример — StreamingLLM (ICLR’24), который обнаружил, что оценки внимания LLM демонстрируют необычно сильные пики вокруг начальных и последних токенов. Сохраняя внимание к этим двум частям, LLM может поддерживать стабильную производительность при потоковой обработке длинных входных данных.
На основе этого авторы также предложили метод оптимизации кэша DuoAttention (ICLR’25) для поддержания производительности извлечения в длинных контекстах. Помимо оптимизации кэша, оценки внимания также можно использовать для динамического разрежения для ускорения вывода в длинном контексте, например, в Minference (NeurIPS’24 Spotlight).
Открытие гетерогенных особенностей
Однако эти исследования рассматривают оценку внимания как атомарное целое, в то время как отсутствует анализ того, как разные измерения q и k по-разному вносят вклад в общую оценку. Этот пробел был затронут в некоторых недавних исследованиях, что приводит нас к сегодняшнему фокусу — гетерогенным особенностям.
Гетерогенные особенности относятся к явлению, когда компоненты внимания вдоль разных измерений qk играют разные роли в механизме внимания в LLM с длинным контекстом.
Наблюдения из практики
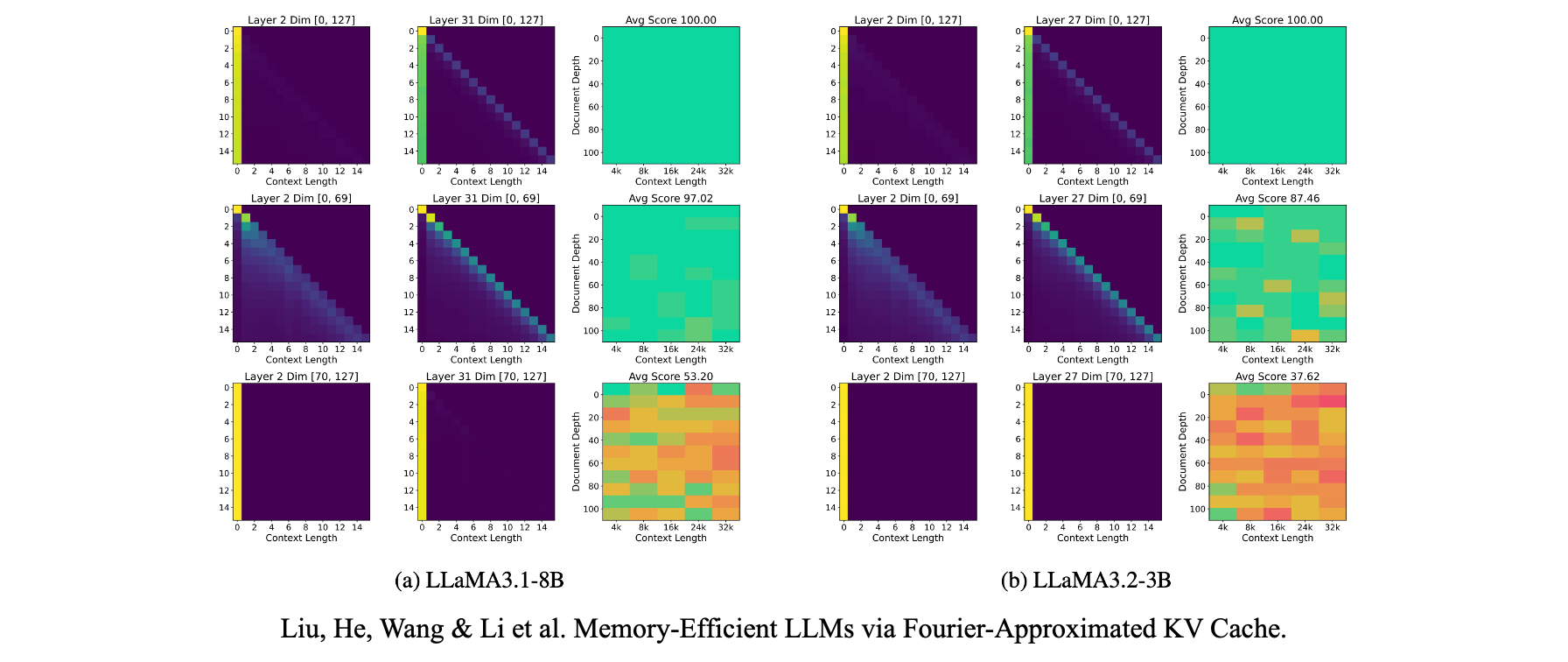
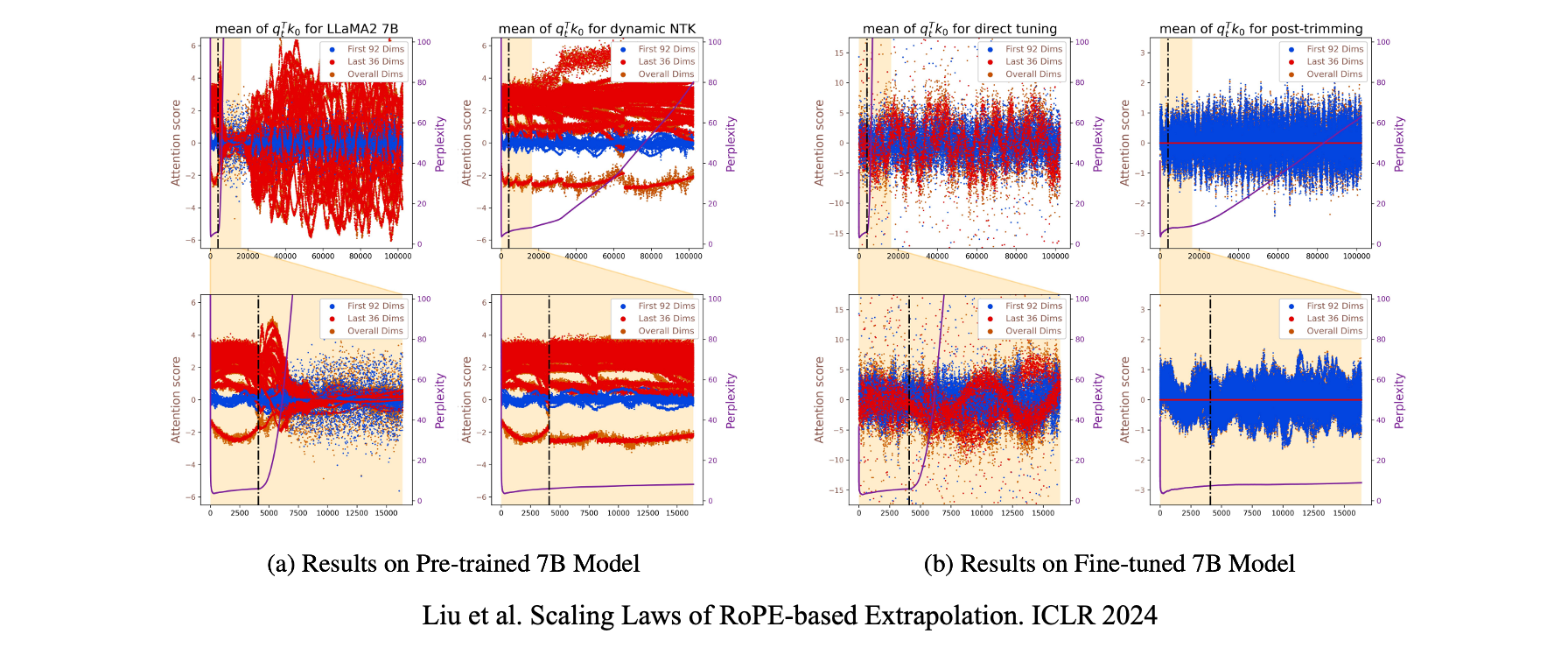
С точки зрения извлечения длинного контекста мы знаем, что большая часть оценки внимания распределяется на начальные и последние токены, как указано в StreamingLLM, а оценка внимания представляет собой сумму 128 поэлементных произведений qk по измерениям. Если мы разделим сумму, например, первые 70 измерений против последних 58, мы обнаружим, что нижние измерения отвечают за высокую оценку внимания на последних токенах, а верхние измерения отвечают за оценку на начальных токенах.
На основе этого, если мы добавим шум к первым 70 измерениям, производительность NIAH (Needle-In-A-Haystack) LLM почти не меняется. Но если мы добавим тот же шум к последним 58 измерениям, даже если их меньше, производительность NIAH значительно ухудшается. Это явление последовательно наблюдается как в моделях LLaMA, так и в Qwen.
С точки зрения экстраполяции длины мы исследуем, как компоненты оценки внимания из нижних и верхних измерений колеблются в пределах и за пределами обученной длины контекста модели. Мы обнаруживаем, что нижние измерения остаются стабильными независимо от экстраполяции, в то время как верхние измерения показывают аномальные колебания, как только индекс токена превышает максимальную поддерживаемую длину контекста, и положение этих колебаний сильно коррелирует с тем, где происходят скачки перплексии.
Открытие гетерогенности в механизме внимания — это тот редкий случай, когда математическая элегантность встречается с практической полезностью. RoPE, которую многие воспринимали как просто ещё один метод позиционного кодирования, оказалась гораздо более сложным инструментом, где разные «струны» играют разные мелодии в оркестре внимания.
Математическое объяснение через RoPE
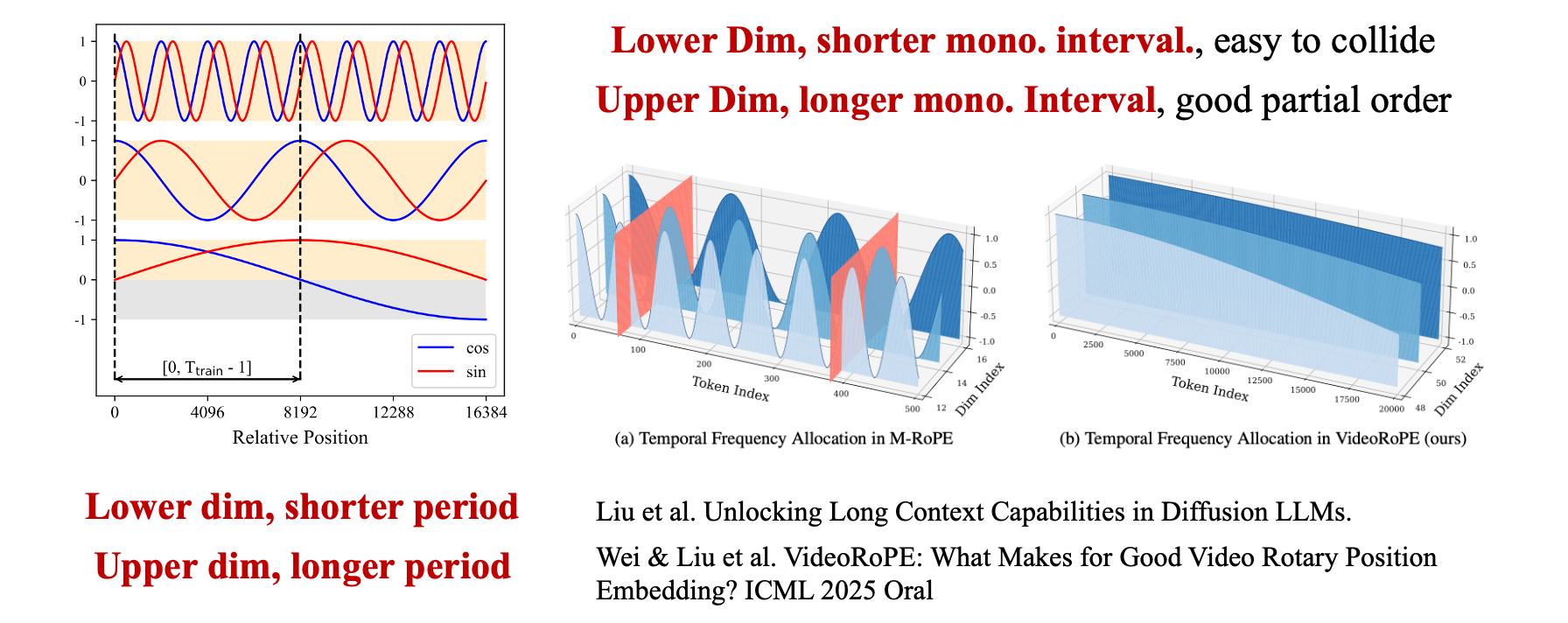
Откуда берутся эти гетерогенные особенности? Мы считаем, что источником является Rotary Position Embedding (RoPE). Почему RoPE вызывает гетерогенные особенности? Как хорошо известно, RoPE кодирует позиционную информацию, используя синусоидальные или косинусоидальные функции с разными углами вращения, а именно частотами, по измерениям qk. Эта структура наследует два математических свойства синусоидальных функций: периодичность и монотонность.
Нижние измерения соответствуют короткому периоду или высокой частоте и наблюдают полные (даже множественные) периоды в предварительном обучении. Верхние измерения соответствуют длинному периоду или низкой частоте и видят только часть периода (например, только положительную половину) в предварительном обучении. Кроме того, нижние измерения имеют короткие монотонные интервалы, поэтому разные относительные позиции могут коллапсировать в одно и то же вложение, подобно хеш-коллизиям. Верхние измерения имеют длинные монотонные интервалы, позволяя им сохранять хороший частичный порядок в длинных контекстах и тем самым захватывать семантические зависимости длинного контекста.
Поэтому мы имеем кажущийся странным, но на самом деле разумный вывод, что периодичность ограничивает способность экстраполяции верхних измерений, в то время как монотонность делает верхние измерения ответственными за моделирование семантики длинного контекста.
Критическое измерение как математический маркер
Чтобы заменить расплывчатое понятие нижних и верхних измерений, мы предоставляем математическое определение. Это критическое измерение. Критическое измерение — это количество измерений, для которых RoPE завершает полный период в пределах окна контекста предварительного обучения. Измерения до и после критического измерения точно соответствуют гетерогенному поведению, описанному ранее.
Практическое применение открытия
Как использовать гетерогенную особенность? Большинство методов расширения контекста (например, масштабирование на основе NTK) изменяют вращательную базу RoPE. Однако наше исследование показывает, что разные измерения в RoPE играют разные роли в обработке длинного контекста, что открывает новые возможности для оптимизации.
Сообщает Hugging Face.





Оставить комментарий