
Оглавление
Исследователи Google объединили два подхода к оптимизации LLM — каскады и спекулятивное декодирование — в единый гибридный метод, который обещает существенное ускорение генерации текста без потери качества. Сообщает Google Research.
Проблема дорогой генерации
Языковые модели кардинально изменили взаимодействие с технологиями, но их работа остаётся вычислительно дорогой — генерация ответов может быть медленной и требовать значительных ресурсов. По мере масштабирования сервисов на базе ИИ поиск способов ускорить инференс без компромиссов в качестве становится критически важной задачей.
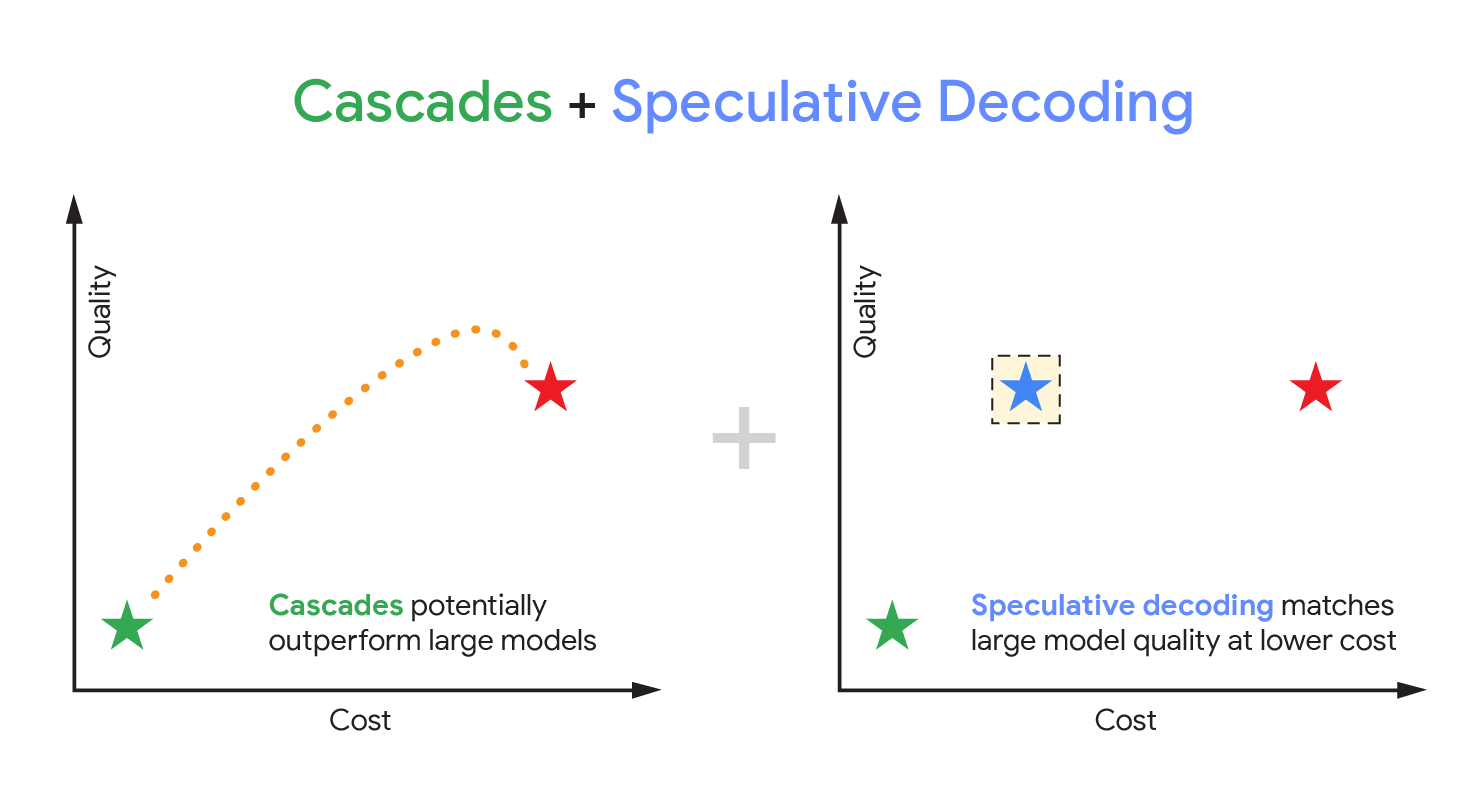
Два подхода к оптимизации
До сих пор существовало два основных метода ускорения LLM:
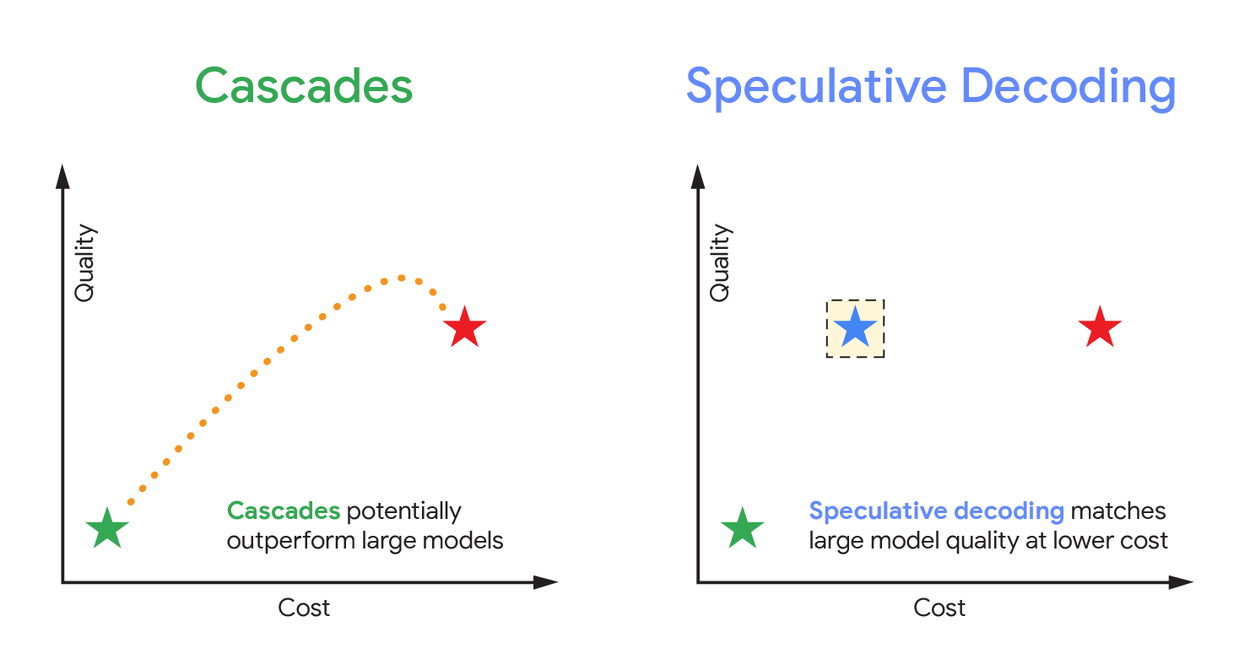
- Каскады (cascades) — используют меньшую модель как фильтр: если она уверена в ответе, то возвращает его, экономя ресурсы; если нет — передаёт запрос более крупной модели. Оптимизируют стоимость вычислений, но работают последовательно
- Спекулятивное декодирование — меньшая модель «предсказывает» несколько токенов вперед, а большая проверяет их параллельно. Если предсказание совпадает — процесс ускоряется; если нет — начинается заново. Гарантирует идентичный результат, но требует больше памяти
Наглядный пример: вопрос о Баззе Олдрине
Представьте запрос «Кто такой Базз Олдрин?». Маленькая модель может ответить: «Американский астронавт, второй человек на Луне». Большая: «Эдвин «Базз» Олдрин — ключевая фигура в истории космических исследований…».
При каскадном подходе маленькая модель, будучи уверенной в ответе, сразу вернёт результат. При спекулятивном декодировании её токены «Базз» могут не совпасть с «Эдвин» от большой модели, и весь draft будет отвергнут, потеряв преимущество в скорости.

Гибридное решение: спекулятивные каскады
Новый метод сочетает преимущества обоих подходов. Маленькая модель создаёт черновик, большая — параллельно его проверяет. Ключевое отличие — гибкое правило отложенного решения (deferral rule), которое на уровне токенов определяет: принять вариант маленькой модели или передать управление большой.
В примере с Олдрином система может принять вариант «Базз», даже если большая модель предпочла бы «Эдвин», — если смысл ответа корректен. Это избегает последовательного bottleneck каскадов и излишне строгой проверки спекулятивного декодирования.
Практическая ценность подхода — в адаптивности. Вместо бинарного «принять/отклонить» мы получаем интеллектуальный баланс между скоростью и точностью. Особенно важно для массовых сервисов вроде поиска или чат-ботов, где миллионы запросов в день. Технология не революционна, но элегантна — типичный пример инженерной оптимизации, когда сложность скрыта от пользователя, а выгода очевидна в масштабе.
Результаты тестирования
Метод протестирован на моделях Gemma и T5 для задач суммаризации, перевода, решения задач, программирования и вопросно-ответных систем. Спекулятивные каскады показали лучшие показатели соотношения затрат и качества по сравнению с базовыми методами — более высокая скорость при сопоставимом или лучшем качестве.
Гибридный подход особенно эффективен для сценариев, где приемлемы вариации в формулировках при сохранении смысловой точности — то есть для большинства практических применений LLM.





Оставить комментарий