
Оглавление
Индустрия больших языковых моделей (LLM) достигла нового уровня самосознания: Google опубликовал комплексный бенчмарк FACTS, который системно оценивает фактическую точность моделей. Результаты отрезвляют: ни одна из ведущих моделей — ни Gemini 3 Pro, ни GPT-5, ни Claude 4.5 Opus — не смогла преодолеть порог в 70% общей точности. Это не просто цифры, а сигнал для всех, кто строит на LLM бизнес-критичные системы: эпоха «доверяй, но проверяй» далека от завершения.
По сообщению VentureBeat, бенчмарк призван закрыть критический пробел в оценке ИИ для таких областей, как юриспруденция, финансы и медицина.
Что измеряет FACTS и почему это важно
В отличие от узкоспециализированных тестов на кодирование или следование инструкциям, FACTS оценивает способность модели генерировать объективно корректную информацию. Исследователи Google разделили «фактичность» на два ключевых сценария: «контекстуальная фактичность» (основание ответов на предоставленных данных) и «фактичность мировых знаний» (извлечение информации из памяти или интернета). Бенчмарк состоит из четырёх тестов, имитирующих реальные сценарии сбоев в продакшене:
- Параметрический тест (Internal Knowledge): Может ли модель точно отвечать на вопросы, используя только свои тренировочные данные?
- Тест на поиск (Tool Use): Может ли модель эффективно использовать инструмент веб-поиска для получения и синтеза актуальной информации?
- Мультимодальный тест (Vision): Может ли модель точно интерпретировать графики, диаграммы и изображения без галлюцинаций?
- Тест на заземление v2 (Context): Может ли модель строго придерживаться предоставленного исходного текста?
Для предотвращения натаскивания моделей на тестовые данные Google опубликовал 3513 примеров, а Kaggle сохранил приватный набор.
Таблица лидеров: битва за десятые доли процента
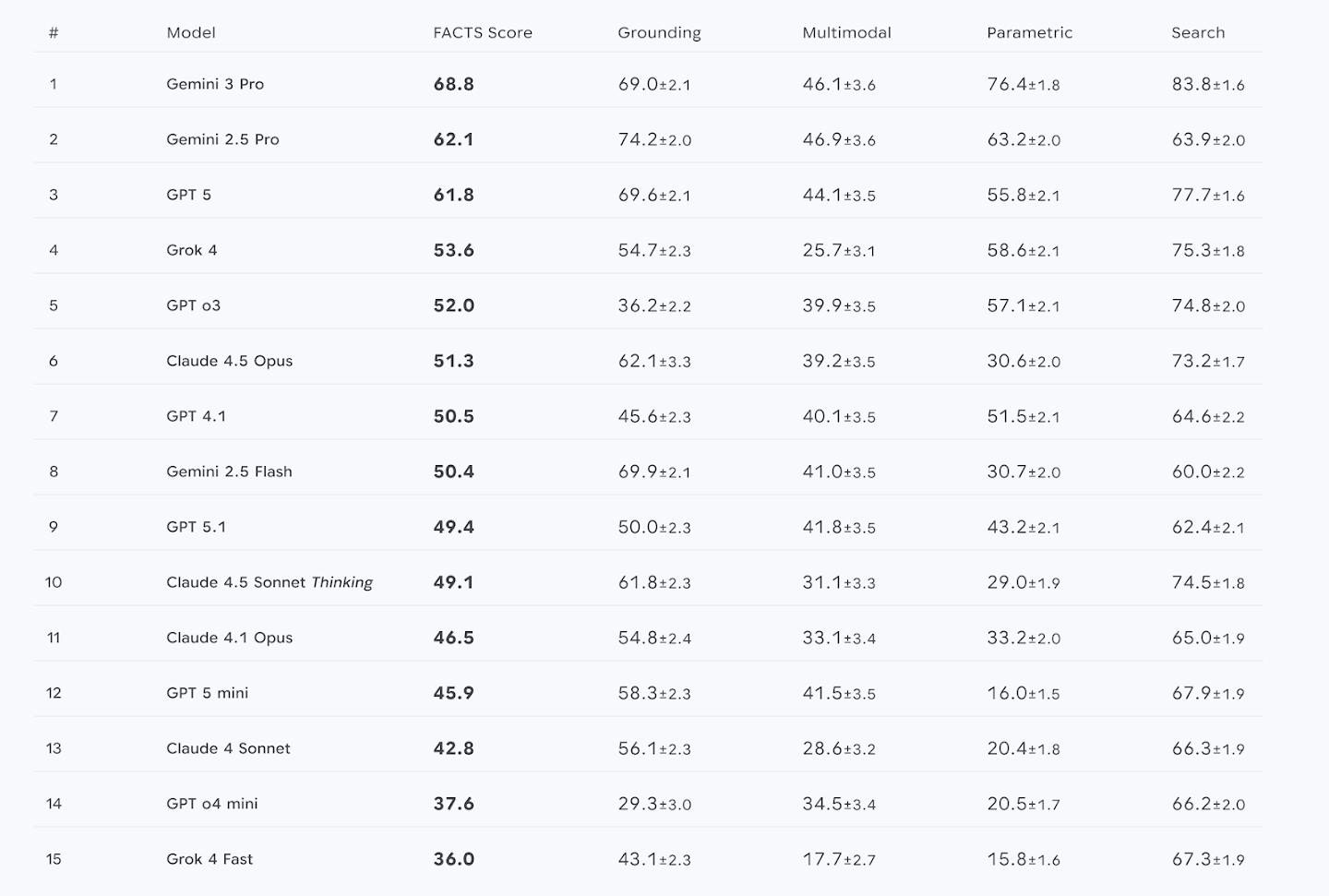
На первой строчке с общим баллом FACTS Score 68,8% оказался Gemini 3 Pro от Google. За ним следуют Gemini 2.5 Pro (62,1%) и GPT-5 от OpenAI (61,8%). Однако ключевые инсайты скрыты в деталях по суб-тестам.
Для разработчиков систем с RAG (Retrieval-Augmented Generation) критически важен тест на поиск. Здесь разрыв между способностью модели «знать» (Параметрический тест) и «находить» (Поиск) колоссален. Gemini 3 Pro показывает 83,8% в поиске против 76,4% в параметрическом знании. Это железное подтверждение текущего стандарта корпоративной архитектуры: не полагайтесь на внутреннюю память модели для критически важных фактов.
Этот бенчмарк — долгожданная холодная вода для горячих голов, верящих в непогрешимость современных LLM. Тот факт, что даже флагманские модели не могут стабильно выдавать факты с точностью выше 70%, говорит о фундаментальном ограничении текущей архитектуры. Это не баг, это фича — мы имеем дело с вероятностными машинами для генерации текста, а не с базами знаний. А Google, чей поиск десятилетиями был синонимом поиска фактов, теперь публично признаёт, что его самые продвинутые модели в этом плане работают хуже, чем среднестатистический студент-первокурсник. Самое смешное, что для многих инженеров эти цифры не стали открытием — они уже давно проектируют системы с учётом этой погрешности.
Мультимодальность: красная зона для продукт-менеджеров
Самые тревожные данные касаются мультимодальных задач. Результаты здесь катастрофически низки. Даже лидер категории, Gemini 2.5 Pro, достиг лишь 46,9% точности. Тесты включали чтение графиков, интерпретацию диаграмм и идентификацию объектов на изображениях. Точность ниже 50% по всем фронтам означает, что мультимодальный ИИ ещё не готов для бесконтрольного извлечения данных.
Вывод для бизнеса: если в вашем продуктовом плане заложено автоматическое сканирование данных с накладных или интерпретация финансовых графиков без участия человека, вы с высокой вероятностью внедряете в свой конвейер значительный процент ошибок.
Практические выводы для выбора стека технологий
Бенчмарк FACTS, вероятно, станет стандартным ориентиром при закупках. Техническим руководителям при оценке моделей для корпоративного использования следует смотреть не только на сводный балл, но и на конкретные суб-тесты, соответствующие их use case:
- Строите чат-бота поддержки? Смотрите на балл Grounding, чтобы бот придерживался ваших документов (Gemini 2.5 Pro здесь обошёл Gemini 3 Pro: 74,2 против 69,0).
- Создаёте исследовательского ассистента? Приоритезируйте баллы Search.
- Разрабатываете инструмент анализа изображений? Действуйте с крайней осторожностью.
Как отметила команда FACTS, «все оценённые модели достигли общей точности ниже 70%, оставляя значительное пространство для будущего прогресса». Пока что послание индустрии ясно: модели становятся умнее, но они ещё не безошибочны. Проектируйте свои системы, предполагая, что примерно в трети случаев сырая модель может просто ошибаться.





Оставить комментарий