
Оглавление
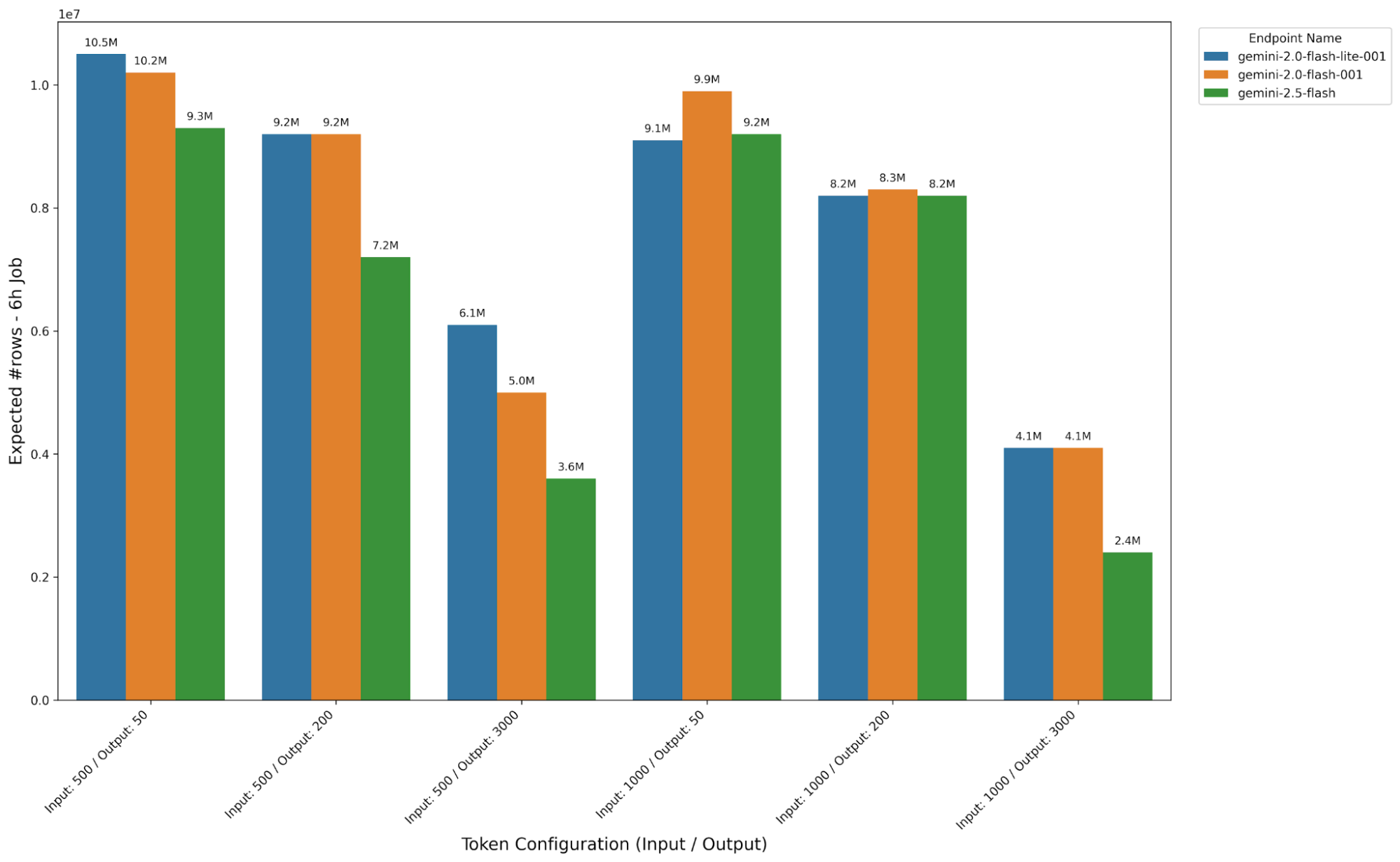
Google представила масштабные улучшения платформы BigQuery, которые кардинально повышают производительность генеративного ИИ при работе с большими данными. По сообщению Google Cloud Blog, теперь система обрабатывает до 80 миллионов строк за шестичасовое задание — в 30 раз больше предыдущих показателей.
Технический прорыв в масштабируемости
Ключевое достижение — увеличение пропускной способности для моделей генерации текста более чем в 100 раз, а для моделей эмбеддингов — более чем в 30 раз. Это стало возможным благодаря внедрению динамического батчинга на основе токенов, который упаковывает максимальное количество строк в один запрос.
Для моделей эмбеддингов Google теперь возможно обрабатывать примерно 80 миллионов строк за шестичасовое задание при стандартной квоте 1500 запросов в минуту. При увеличении квоты до 10 000 QPM без ручного одобрения система способна обрабатывать свыше 500 миллионов строк за тот же период.
Повышение надежности до 99.99%
Система теперь обеспечивает завершение более 99.99% запросов LLM-инференса без единого сбоя на уровне строк. Уровень успешности обработки строк превышает 99.99%, а редкие сбои легко перезапускаются без провала всего запроса.
Это стало возможным благодаря адаптивному контролю трафика и надежному механизму повторных попыток, который эффективно работает с ограниченными и негарантированными квотами генеративного ИИ.
Упрощение пользовательского опыта
Google также упростила workflows для пользователей BigQuery:
- Автоматическое создание соединений по умолчанию для удаленных моделей
- Единая точка управления квотами через Vertex AI
- Поддержка глобальных endpoint для всех регионов
- Упрощенная настройка разрешений для сервисных аккаунтов
Эти улучшения — не просто технические цифры, а реальное изменение возможностей для data-инженеров. Обработка десятков миллионов строк за один запрос без ручного управления инфраструктурой — это тот уровень абстракции, который действительно приближает enterprise-компании к массовому использованию генеративного ИИ. Интересно, как быстро конкуренты ответят на этот вызов.
Поддержка Provisioned Throughput от Vertex AI позволяет покупать выделенную capacity для гарантированной высокой пропускной способности. Это особенно важно для рабочих нагрузок с жесткими требованиями к производительности и предсказуемости.
Как отмечает Шеймус Абшир, сооснователь и CTO Faraday: «Я только что сделал 12 678 259 эмбеддингов за 45 минут с встроенным Gemini в BigQuery. Это около 5000 в секунду. Попробуйте сделать это с HTTP API!»





Оставить комментарий