
Оглавление
Когда речь заходит о развертывании больших языковых моделей, разговор почти всегда сводится к знакомому компромиссу: либо более крупная и умная модель, либо меньшая и быстрая, которая помещается на вашем оборудовании. Кажется очевидным, правда? Вы выбираете точку на кривой производительность-ресурсы и остаетесь с ней.
Но что, если бы не пришлось? Что, если бы можно было обучить одну большую модель и получить целое семейство меньших, высокопроизводительных моделей бесплатно?
Принцип матрешки: одна модель, много размеров
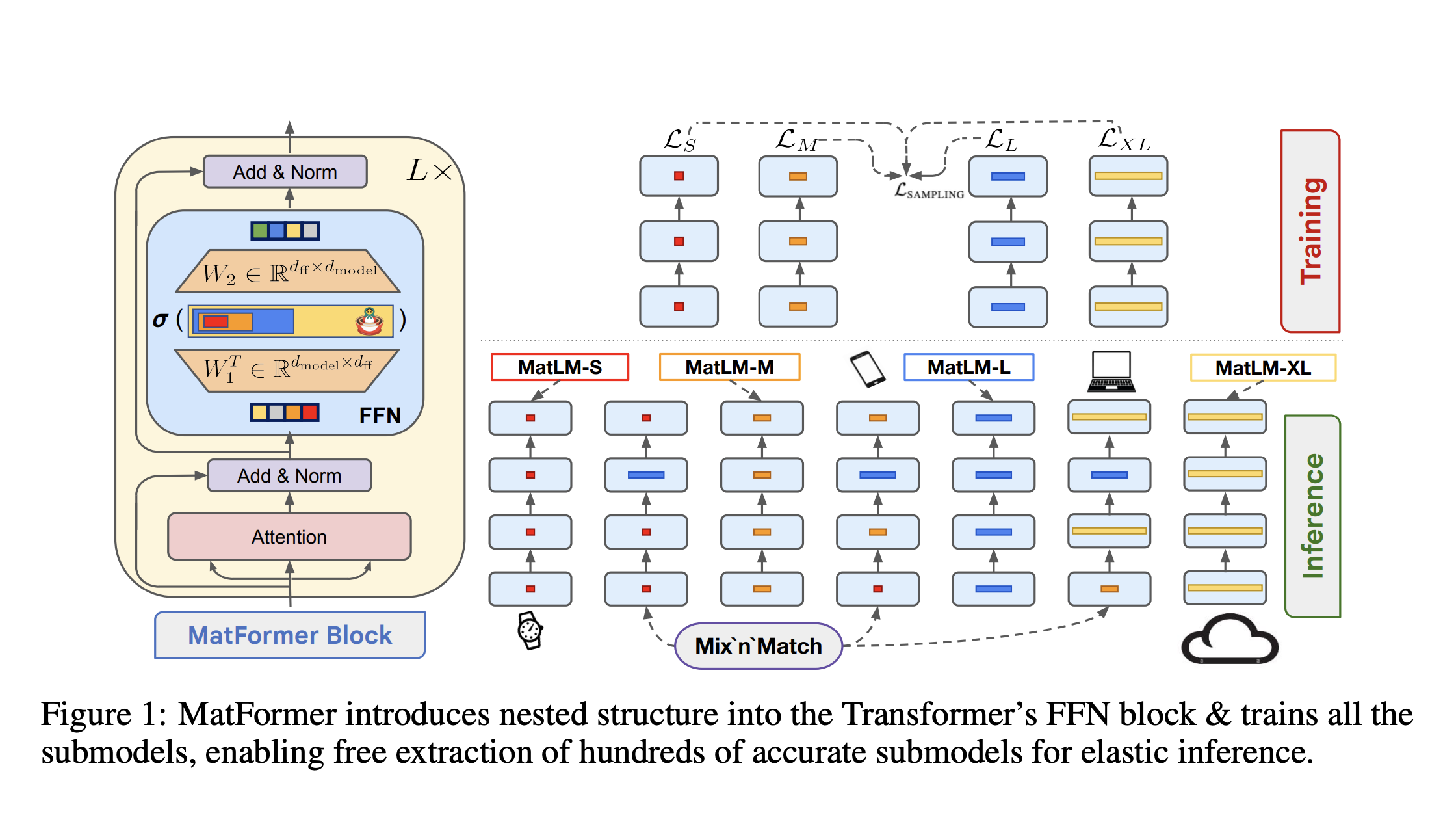
Вы знаете эти русские матрешки, где открываешь одну и находишь внутри меньшую, идентичную куклу, а внутри нее еще одну? Это идеальная ментальная модель для MatFormer.
В стандартном блоке Transformer сеть прямого распространения (FFN) имеет фиксированный промежуточный размер. Например, она может принимать 4096-мерный вход, расширять его до 16384-мерного промежуточного слоя (W_in), а затем проецировать обратно до 4096 измерений (W_out). Эти размеры фиксированы.
MatFormer меняет это. Внутри каждого слоя Transformer находится не одна FFN, а серия вложенных FFN. Это не просто концептуальное вложение — оно буквальное. Матрицы весов меньших FFN являются подматрицами больших.
Давайте конкретизируем. Если самая большая FFN (назовем ее размером S) имеет матрицы весов W_in (4096×16384) и W_out (16384×4096), то следующая меньшая FFN (S/2) использовала бы только верхнюю левую часть этих матриц — скажем, первые 8192 столбца W_in и первые 8192 строки W_out. FFN S/4 использовала бы первые 4096 столбцов/строк и так далее. Они физически встроены в один и тот же блок параметров.
Магия в процессе обучения, который представляет собой форму стохастической глубины или обучения случайным путям. На каждом шаге обучения для каждого слоя модель случайным образом выбирает «фактор емкости» — S, S/2, S/4 и т.д. Вход для этого слоя затем пропускается только через эту конкретную подсеть. Один раз вход может пройти через FFN S/2 в слое 1 и FFN S/8 в слое 2. В следующий раз он может использовать полную FFN S в обоих.
Выигрыш: «Выбери своего бойца» при выводе
Теперь взгляните на архитектуру ниже, потому что именно здесь архитектурная элегантность окупается на практике. Поскольку каждая подмодель является полностью обученной, работоспособной сетью, вы получаете невероятную гибкость, когда приходит время запускать модель.
Источник: huggingface.co
1. Простое уменьшение размера:
Допустим, вы обучили большую модель, но вам нужно развернуть ее на устройстве с только четвертью памяти. С MatFormer вы можете просто решить использовать подсеть FFN размера S/4 в каждом отдельном слое. Вы мгновенно получаете модель, которая примерно в 4 раза меньше исходной. Что важно, поскольку эта конфигурация была явно обучена, она работает значительно лучше, чем отдельная модель, обученная с нуля при таком меньшем размере. Она воспользовалась «передачей знаний» от совместного обучения с более крупными, более способными путями.
2. Шедевр «смешивания и сопоставления»:
Здесь становится действительно интересно. Не все слои в трансформере вносят одинаковый вклад в каждую задачу. Ранние слои могут обрабатывать синтаксис и локальные шаблоны, в то время как более глубокие слои управляют более абстрактными семантическими рассуждениями.
С MatFormer вы можете «смешивать и сопоставлять» подсети между слоями, чтобы создать индивидуальную архитектуру. Вы можете профилировать свою модель, чтобы найти наиболее критические слои для вашей задачи, и назначить им большие FFN (например, S или S/2), экономя емкость на менее критичных слоях, используя меньшие FFN (например, S/8).
Например, если вы определите, что Слой 5 имеет решающее значение для обработки грамматических нюансов в вашей задаче перевода, вы можете выделить ему полную FFN S. Но если Слой 20 менее влиятелен, вы можете уменьшить его до S/8, сэкономив значительное количество вычислений и памяти с минимальной потерей производительности для этой конкретной задачи. Это позволяет вам построить индивидуально настроенную модель, которая оптимально балансирует производительность и использование ресурсов.
Магия памяти: как 5 миллиардов параметров помещаются в объеме 2 миллиардов
Итак, у нас есть эта гибкая вычислительная структура с MatFormer. Но у Gemma 3n есть еще один трюк в рукаве, и все дело в памяти. Вы, возможно, видели, что модель Gemma 3n 2B (E2B) на самом деле имеет около 5 миллиардов реальных параметров, но она занимает память GPU типичной модели 2B. Как это возможно?
Ответ — Встраивания на уровне слоев (Per-Layer Embeddings, PLE).
В стандартной языковой модели таблица встраивания токенов представляет собой единый монолитный блок памяти. Это гигантская таблица поиска размером vocabulary_size x hidden_dimension, которая должна находиться в VRAM вашего GPU. Приведем некоторые цифры. Для модели с словарем из 256 000 токенов и скрытым размером 2048, использующей bfloat16 (2 байта на параметр), одна только таблица встраивания составляет 256 000 * 2048 * 2 байта ≈ 1,05 ГБ. Это огромная статическая стоимость еще до обработки даже одного токена.
PLE умно обходит это, выгружая веса встраивания из высокоскоростной, но дефицитной VRAM GPU в гораздо более крупную, но медленную оперативную память CPU. Когда модели нужно обработать входную последовательность, она не загружает всю таблицу. Вместо этого она забирает из CPU в GPU через шину PCIe только конкретные векторы встраивания для токенов в этой последовательности.
Это классический инженерный компромисс. Вы принимаете крошечную задержку от передачи данных CPU-to-GPU, но взамен освобождаете огромный кусок VRAM. Это позволяет модели с гораздо большим истинным количеством параметров работать в ограниченном бюджете памяти.
Именно так устроено семейство Gemma 3n. Модель 4B (E4B, которая на самом деле имеет 5,44 млрд параметров) является полной моделью. Модель 2B (E2B) — это подсеть внутри нее, созданная путем объединения двух вещей:
- MatFormer: Выбор меньших подсетей FFN для уменьшения количества вычислений и активных параметров.
- Встраивания на уровне слоев: Использование выгрузки памяти для управления объемом полного набора параметров в 5 млрд.
Технология MatFormer — это не просто очередной академический эксперимент, а практическое решение одной из самых болезненных проблем индустрии: дилеммы «или мощность, или эффективность». Вместо того чтобы выбирать между большими и маленькими моделями, мы получаем универсальный инструмент, который адаптируется под конкретные задачи и аппаратные ограничения. Особенно впечатляет подход с обучением всех вложенных сетей одновременно — это напоминает принцип дистилляции знаний, но без необходимости отдельного процесса обучения учителя и ученика. Впрочем, остается вопрос, насколько хорошо такие «универсальные солдаты» справляются со специализированными задачами по сравнению с узкоспециализированными моделями.
По материалам Hugging Face.





Оставить комментарий