
Оглавление
Новый бенчмарк от Artificial Analysis выявил тревожные слабости в фактической надежности больших языковых моделей. Из 40 протестированных моделей только четыре показали положительный результат — с явным лидерством Gemini 3 Pro от Google.
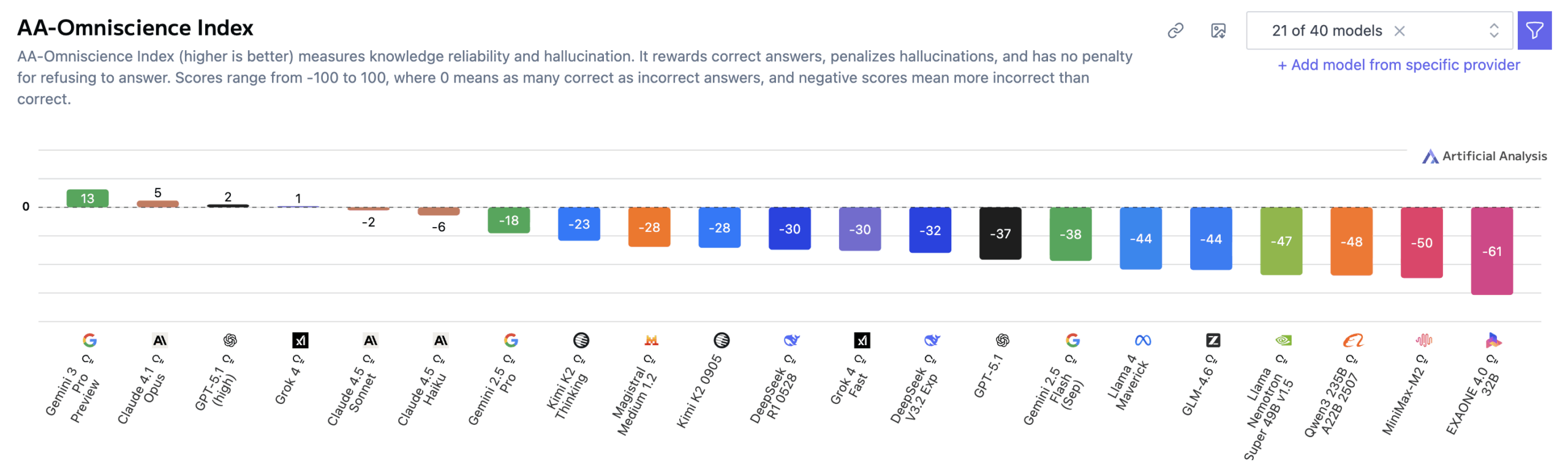
Gemini 3 Pro набрал 13 баллов в новом индексе Omniscience (диапазон от -100 до 100), значительно опередив Claude 4.1 Opus (4,8), GPT-5.1 и Grok 4. Высокий результат в основном отражает исключительную точность модели — Gemini 3 Pro превзошел Grok 4, ранее самую точную модель, на 14 пунктов. Нулевой балл означает, что модель дает правильные и неправильные ответы с одинаковой частотой. AA-Omniscience Benchmark измеряет, насколько надежно ИИ-модели извлекают фактические знания в разных предметных областях.
Согласно Artificial Analysis, лидерство Gemini 3 Pro в основном обусловлено повышенной точностью — на 14 пунктов выше, чем у предыдущего рекордсмена Grok 4. Исследователи интерпретируют это как доказательство большого масштаба модели, поскольку точность в бенчмарке сильно коррелирует с размером модели.
Высокие показатели галлюцинаций остаются главной проблемой
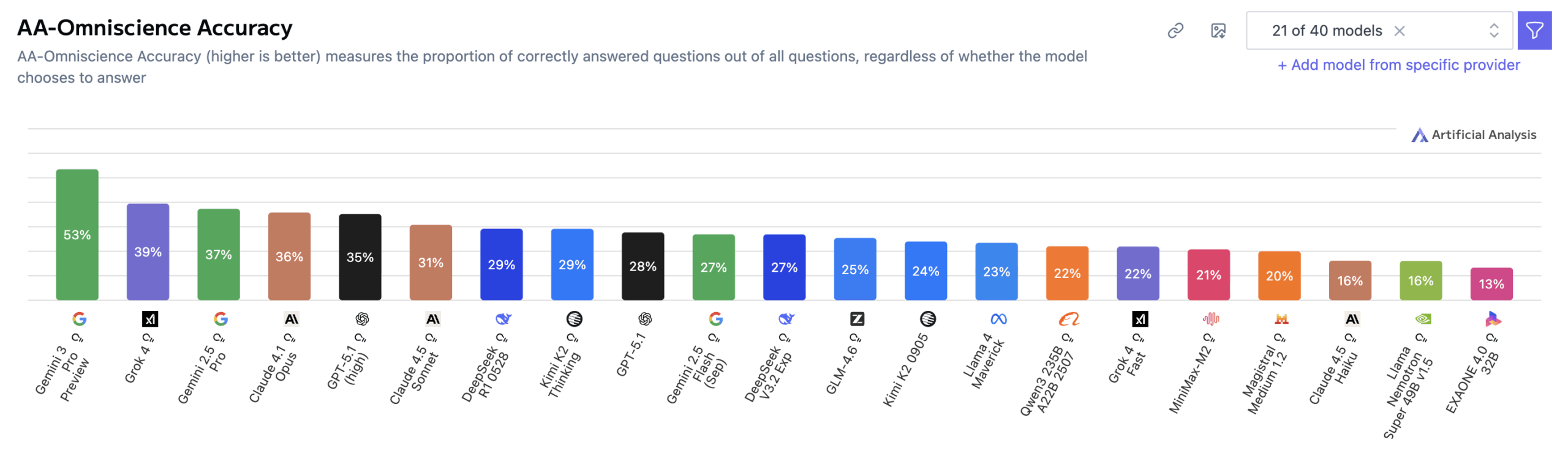
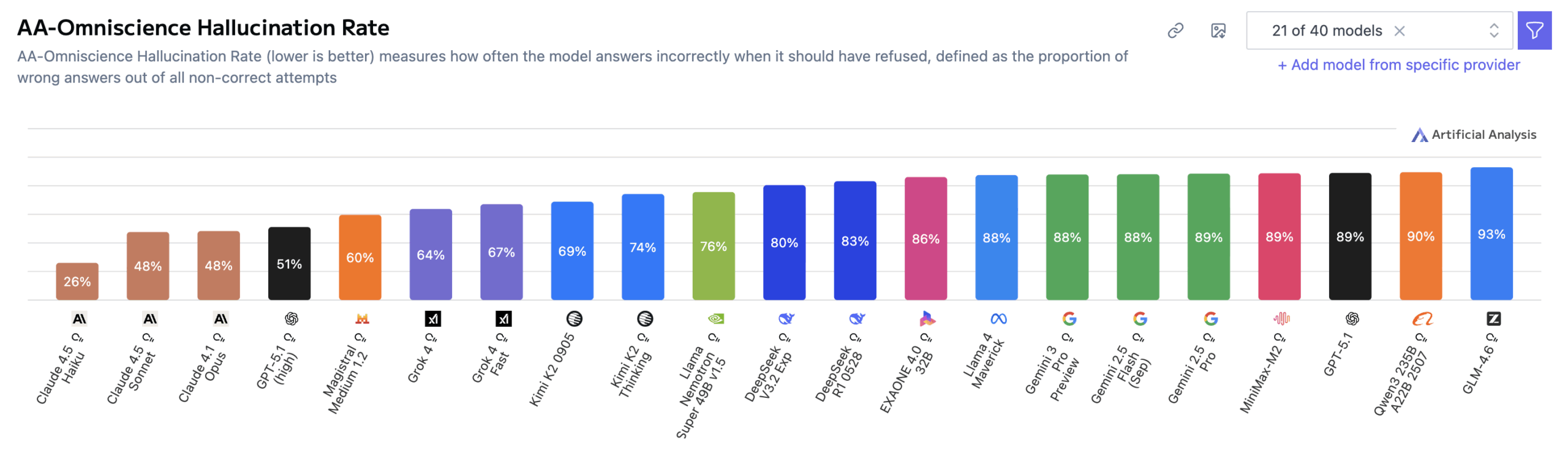
Исследование показало, что плохие результаты в целом в значительной степени связаны с высокими показателями галлюцинаций. Gemini 3 Pro достиг наивысшей общей точности — 53 процента, значительно опередив предыдущих лидеров, таких как GPT-5.1 (high) и Grok 4, у которых по 39 процентов. Но у модели по-прежнему сохраняется показатель галлюцинаций 88 процентов, что соответствует показателям Gemini 2.5 Pro и Gemini 2.5 Flash.
GPT-5.1 (high) и Grok 4 также показали высокие результаты — 81 и 64 процента соответственно, но Gemini 3 Pro пошел еще дальше. Artificial Analysis пришел к выводу, что хотя Gemini 3 Pro демонстрирует больший охват фактов, его тенденция давать неправильные ответы вместо признания неуверенности остается неизменной.
Здесь показатель галлюцинаций относится к доле ложных ответов среди всех неправильных попыток — это означает, что высокое значение указывает на чрезмерную уверенность, а не на незнание.
Claude 4.1 Opus показал точность 36 процентов с одним из самых низких показателей галлюцинаций, что обеспечило ему лидирующую позицию до выхода Gemini 3 Pro.
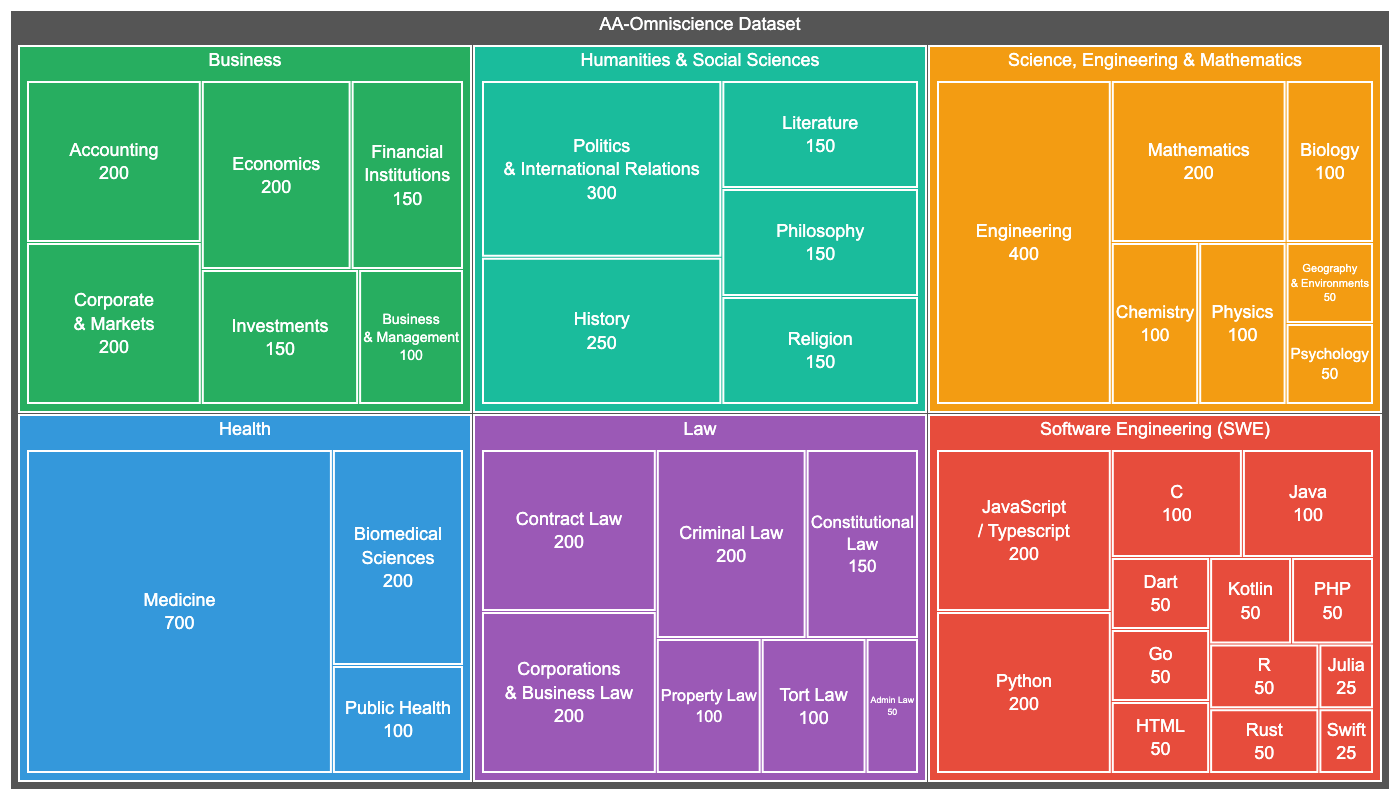
Бенчмарк AA-Omniscience охватывает 6000 вопросов по 42 экономически значимым темам в шести областях: бизнес, гуманитарные и социальные науки, здравоохранение, право, программная инженерия, а также наука и математика. Набор данных взят из авторитетных академических и промышленных источников и был автоматически сгенерирован ИИ-агентом.
Новая система оценки, которая наказывает за угадывание
В отличие от типичных бенчмарков, индекс Omniscience наказывает за неправильные ответы так же сильно, как и вознаграждает за правильные. Исследователи утверждают, что современные методы оценки часто поощряют угадывание, что увеличивает поведение галлюцинаций.
Напротив, новая метрика вознаграждает сдержанность. Модели не получают баллов за признание неуверенности, но и не наказываются. Однако неправильные ответы приводят к большим вычетам.
Результаты группируют модели в четыре категории:
- Модели с обширными знаниями и высокой надежностью (как Claude 4.1 Opus)
- Модели со знаниями, но низкой надежностью (как Claude 4.5 Haiku)
- Модели с ограниченными знаниями, но последовательной надежностью (как GPT-5.1)
- Меньшие модели, которым не хватает как знаний, так и надежности, такие как облегченная gpt-oss от OpenAI
Разбивка по предметным областям для Gemini 3 Pro не предоставлялась.
Старая модель Llama показывает удивительно хорошие результаты
Общий интеллект не обязательно переводится в фактическую надежность. Модели, такие как Minimax M2 и gpt-oss-120b (high), показывают сильные результаты в более широком индексе интеллекта Artificial Analysis, который агрегирует результаты нескольких бенчмарков, но плохо справляются с индексом Omniscience из-за высоких показателей галлюцинаций.
И наоборот, более старая Llama-3.1-405B показала хорошие результаты в индексе Omniscience, хотя обычно занимает более низкие места, чем новые фронтирные модели, в общих оценках.
Ни одна модель не продемонстрировала последовательно высокую фактическую надежность во всех шести областях. Claude 4.1 Opus лидировал в праве, программной инженерии и гуманитарных науках; GPT-5.1.1 занял первое место по бизнес-вопросам; а Grok 4 показал лучшие результаты в здравоохранении и науке.
Согласно исследованию, эти различия между областями означают, что опора исключительно на общую производительность может скрывать важные пробелы.
Больше не всегда означает надежнее
Хотя более крупные модели, как правило, достигают более высокой точности, они не обязательно имеют более низкие показатели галлюцинаций. Несколько меньших моделей — таких как Nvidia Nemotron Nano 9B V2 и Llama Nemotron Super 49B v1.5 — превзошли гораздо более крупных конкурентов в индексе Omniscience.
Мы продолжаем гонку за размером моделей, в то время как ключевая проблема — чрезмерная уверенность ИИ — остается практически неизменной. Gemini 3 Pro демонстрирует впечатляющую точность, но его 88% галлюцинаций — это как нанять гениального сотрудника, который постоянно выдает бредовые идеи с апломбом. Пока мы не научим модели говорить «не знаю» вместо красивой ерунды, реальное применение останется ограниченным.
Artificial Analysis подтвердил, что точность сильно коррелирует с размером модели, но надежность ответов — нет. По материалам The Decoder.





Оставить комментарий