
Оглавление
Сообщество получило свежие данные с бенчмарка Gaia2, который становится новым стандартом для оценки агентских способностей языковых моделей. По сообщению Hugging Face, последние результаты показывают интересные закономерности в эффективности и стоимости различных подходов.
Новые участники и результаты
В обновленную оценку вошли Claude 4 Sonnet Extended Thinking, который продолжает отставать от GPT-5 (high), но показывает последовательное улучшение по сравнению со стандартной версией. Также добавлены модели с открытым исходным кодом: DeepSeek, Qwen 235B в режиме мышления и GPT-OSS 120B в режиме высокого рассуждения.
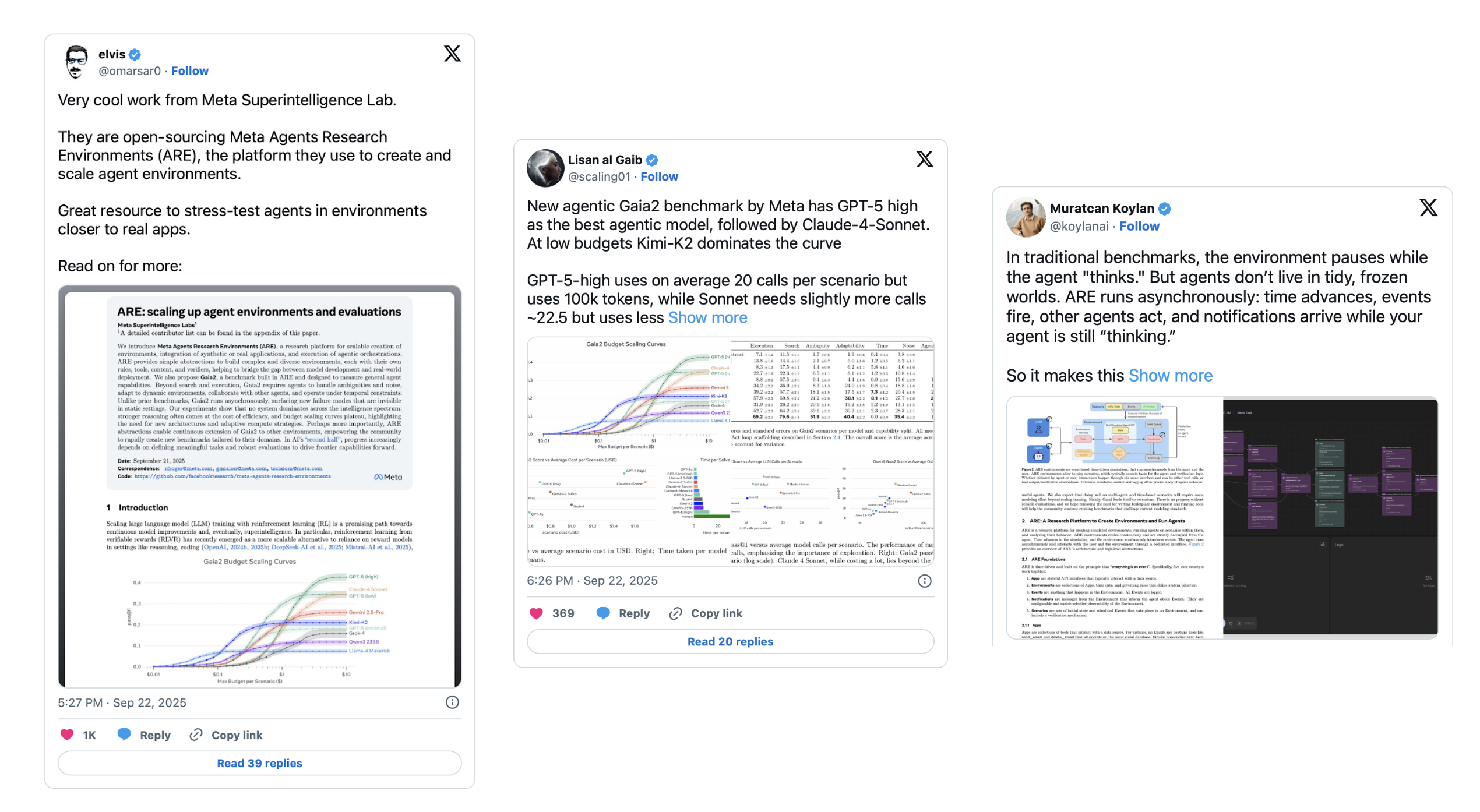
DeepSeek Terminus демонстрирует заметный прирост производительности по сравнению с v3.1, обходя Kimi-K2 и сокращая отставание от Gemini-2-5-Pro. Qwen3 235B с включенным рассуждением показывает прирост +4 пункта, что подтверждает важность явного мышления для агентского поведения.
Экономика токенов: неожиданные затраты
Один из самых интересных инсайтов: Claude оказывается дороже GPT-5 (high), несмотря на генерацию меньшего количества токенов на шаг. Модель выполняет больше шагов в целом, а поскольку входные токены доминируют в стоимости (трассировки составляют ~100-200К токенов), итоговая цена оказывается выше.
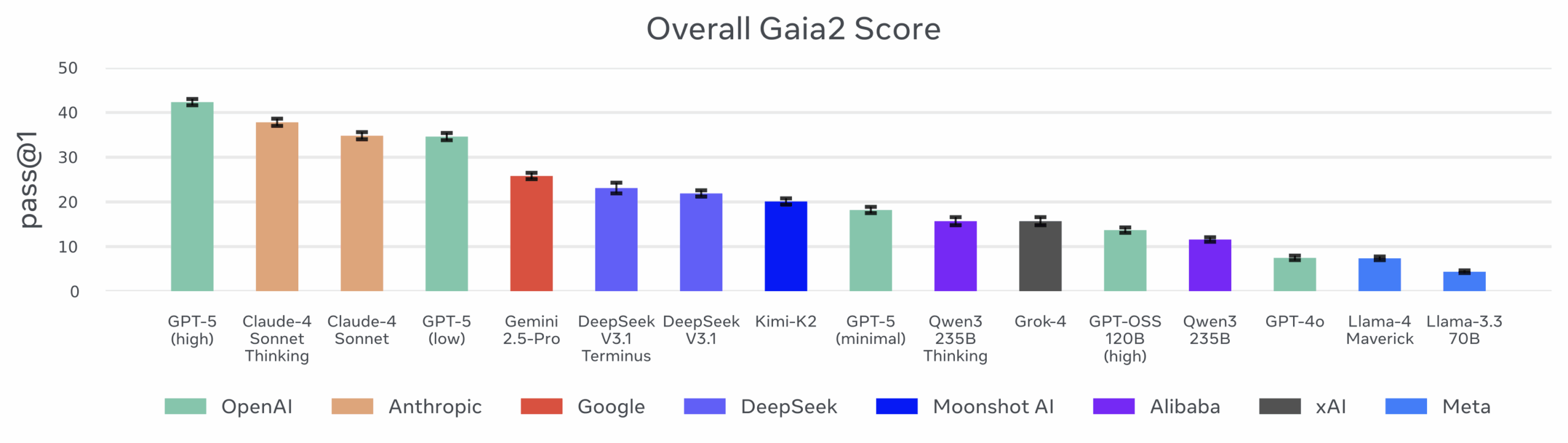
Качество против количества
Включение режима «мышления» может улучшить модели без увеличения затрат. Для Qwen и Claude Sonnet рассуждение улучшает точность и может снизить общую стоимость и время выполнения. Это создает эффект обратного масштабирования относительно GPT-5: модели, производящие больше токенов на шаг при рассуждении, требуют меньше шагов в целом, поскольку делают более эффективные вызовы инструментов.
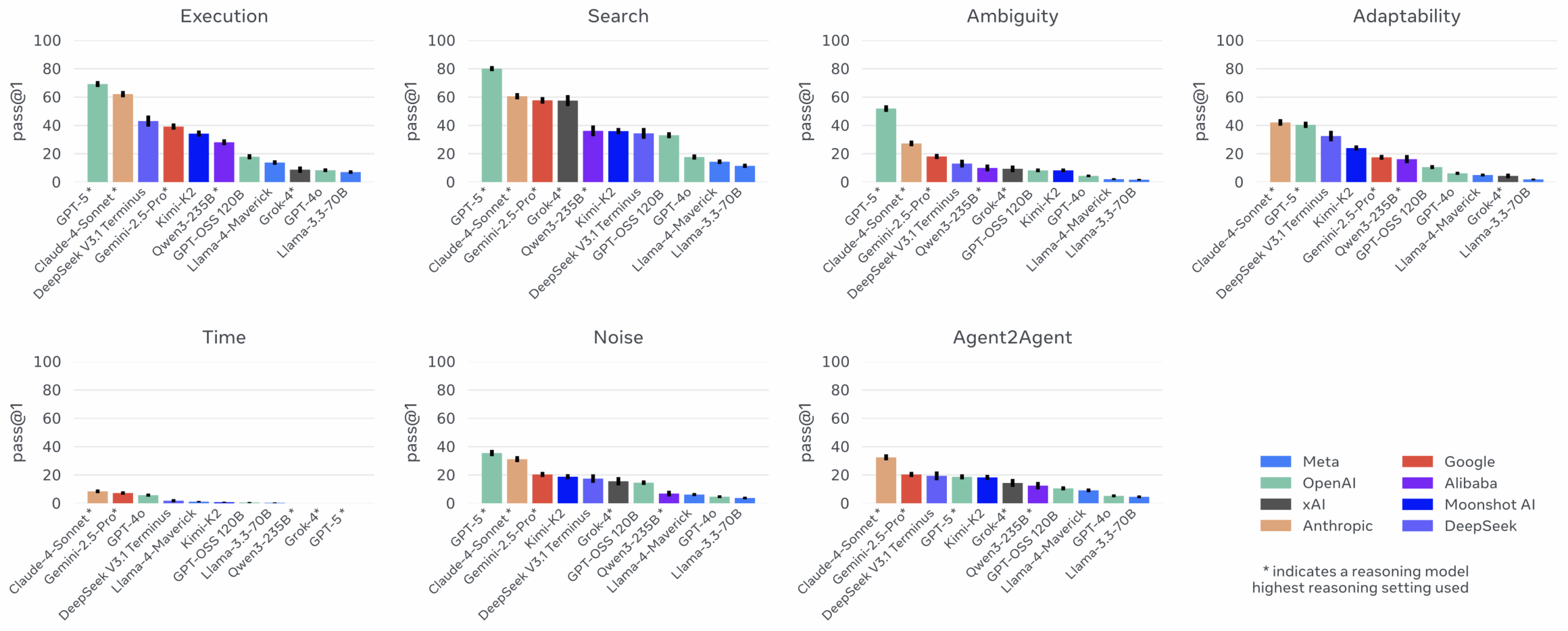
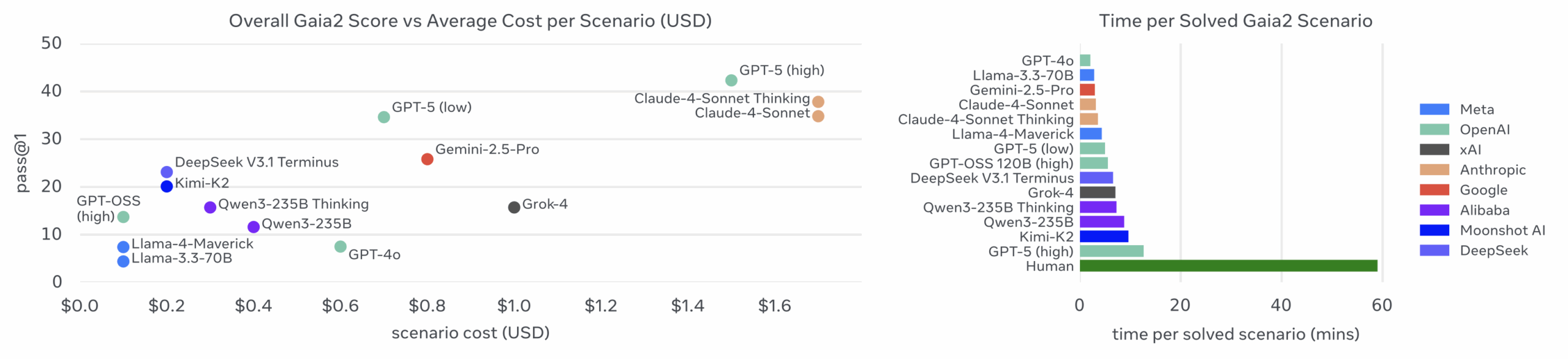
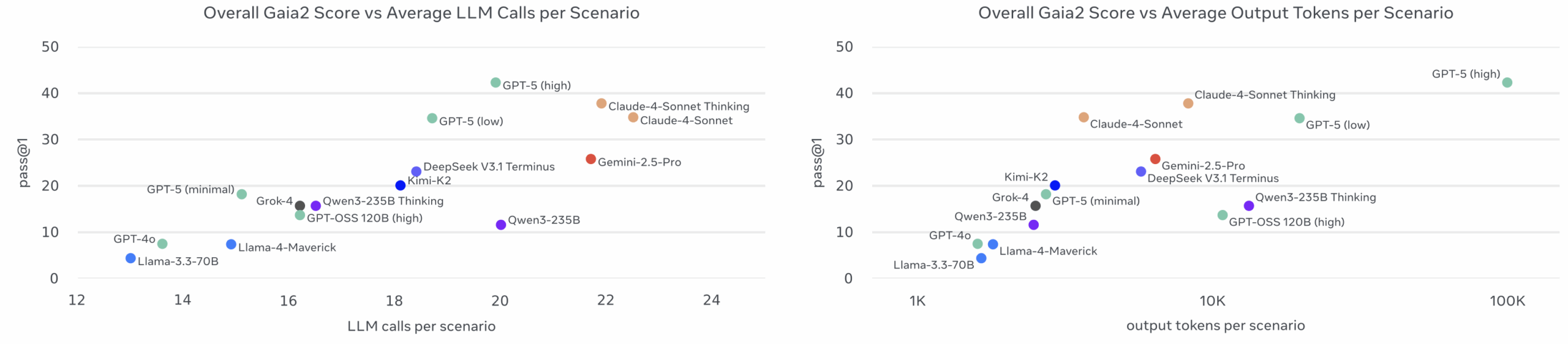
Интересно наблюдать, как экономика токенов становится новым полем битвы для AI-компаний. Тот факт, что Claude с его якобы более дешевым API в итоге оказывается дороже GPT-5 из-за архитектурных особенностей — прекрасная иллюстрация того, как поверхностные метрики могут вводить в заблуждение. Реальные затраты определяются не стоимостью одного токена, а тем, сколько шагов требует задача и как модель распределяет вычисления между input и output.
Бюджетные конкуренты
С добавлением новых моделей с открытым исходным кодом появляются новые претенденты в нижних бюджетных категориях. Кривые масштабирования бюджета показывают, что стандартные решения для построения цепочек рассуждений и модели не доминируют во всем спектре интеллекта — каждая делает компромисс между возможностями, эффективностью и бюджетом.
Все кривые выходят на плато, что предполагает, что стандартные решения для построения цепочек рассуждений и/или модели упускают ключевые компоненты для устойчивого прогресса. Это указывает на необходимость разработки более сложных подходов к архитектуре агентов.
Полные результаты доступны на лидерборде Gaia2, где можно детально изучить производительность различных моделей по разным показателям способностей.





Оставить комментарий