Оглавление
Французские исследователи представили специализированную версию мультимодальной модели SmolVLM, оптимизированную для анализа нормативных документов ядерной отрасли. Модель демонстрирует 15-кратное улучшение точности при работе с французскими документами по сравнению с базовой версией.
Проблема анализа ядерной документации
Ядерная отрасль сталкивается с растущим объемом нормативной и технической документации, требующей эффективных инструментов анализа для обеспечения соответствия требованиям и операционной эффективности. Традиционные подходы к обработке таких документов, сочетающих текст, схемы и таблицы, часто оказываются недостаточно точными.
Разработка отраслеспецифичных языковых моделей — это тренд, который будет только усиливаться, особенно в регулируемых секторах с высокими требованиями к точности и технологическому суверенитету.
Методология подготовки данных
Исследователи использовали систематический сбор документов с трех уровней регулирования:
- Публичная документация международных организаций (МАГАТЭ, NEA/OECD, WENRA)
- Директивы и нормативы Европейского союза по ядерной безопасности
- Французские нормативные акты и техническая документация операторов
Для обработки данных использовался инструмент OGC pdf-to-parquet, который преобразует PDF в изображения высокого разрешения с сохранением оригинальной верстки и автоматически генерирует технические вопросы для обучения.
Архитектура и обучение модели
В качестве базовой модели выбрали HuggingFaceTB/SmolVLM-Instruct — европейскую open-source разработку. Обучение проводили с использованием техники LoRA (Low-Rank Adaptation), которая позволяет адаптировать модель без потери общих возможностей.
Конфигурация обучения включала:
- 40 000 примеров для обучения
- Оптимизацию последних 20% параметров модели
- Специализацию на терминологии ядерной отрасли
Результаты и сравнительное тестирование
Оптимизированная модель показала значительное улучшение метрики NDCG@1 (нормализованный дисконтированный кумулятивный выигрыш на первой позиции):
| Модель | Английский | Французский |
|---|---|---|
| Базовый SmolVLM | 0.17 | 0.04 |
| llamaindex/vdr-2b-multi-v1 | 0.66 | 0.48 |
| Специализированная версия | 0.74 | 0.61 |
Это соответствует увеличению точности в 4.35 раза для английского и в 15.25 раза для французского языка по сравнению с базовой моделью.
Практический пример работы
Модель успешно справляется со сложными запросами, например: «Каков критерий приемлемости для ограниченного воздействия без долгосрочных действий за пределами 800 м от реактора, учитывая как наземные, так и повышенные выбросы?»
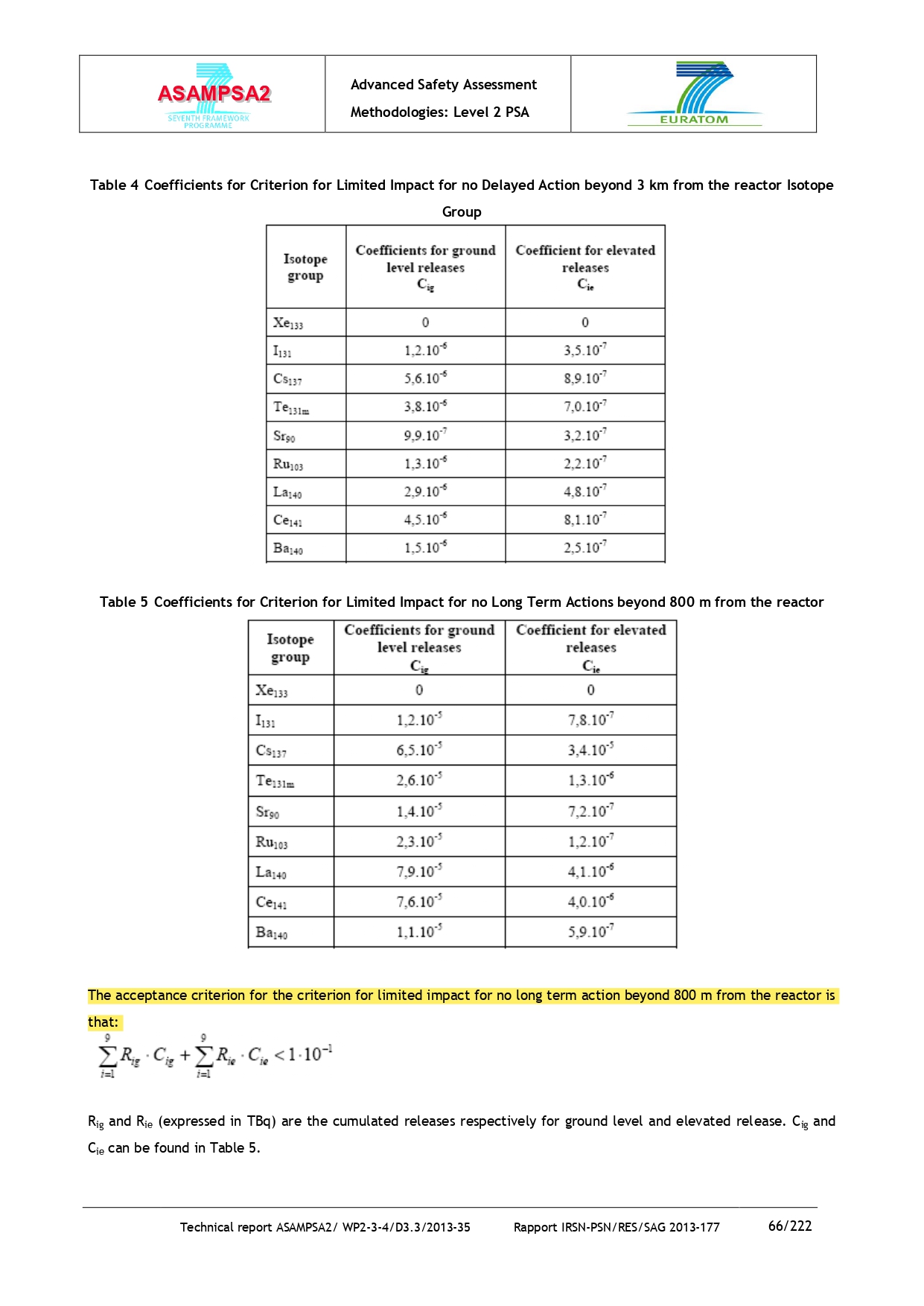
Источник: huggingface.co
Пример корректного документа из тестового набора

Источник: huggingface.co
Пример похожего но некорректного документа
Модель должна различить визуально похожие нормативные документы и выбрать именно тот, который содержит точную нормативную информацию по запросу.
Значение для отрасли
Разработка демонстрирует возможность создания конкурентоспособных европейских AI-решений для критически важных отраслей. Подход с открытыми данными OGC Nuclear dataset и воспроизводимой методологией позволяет другим исследователям развивать это направление.
По сообщению Hugging Face, работа является частью стратегии технологического суверенитета для таких чувствительных секторов, как ядерная энергетика.





Оставить комментарий