Оглавление
Hugging Face пишет, что выход Llama 3.1 открыл новые возможности для кастомизации языковых моделей. Вместо использования замороженных моделей вроде GPT-4o и Claude 3.5, разработчики теперь могут тонко настраивать Llama 3.1 под конкретные задачи, достигая лучшей производительности и кастомизации при меньших затратах.
Контролируемый тонкий настрой (SFT)
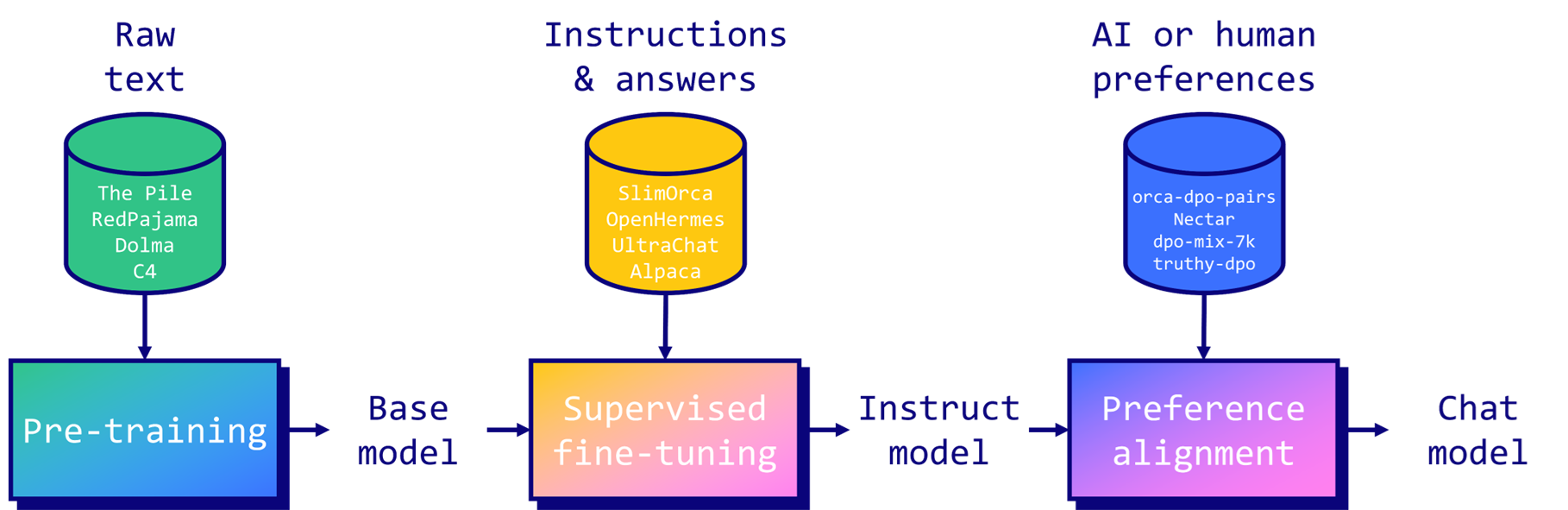
Контролируемый тонкий настрой (Supervised Fine-Tuning) — это метод улучшения и кастомизации предварительно обученных языковых моделей. Он включает дообучение базовых моделей на меньших наборах данных с инструкциями и ответами. Основная цель — преобразовать базовую модель, предсказывающую текст, в ассистента, способного следовать инструкциям и отвечать на вопросы.
SFT также может улучшить общую производительность модели, добавить новые знания или адаптировать ее к конкретным задачам и доменам. После тонкой настройки модели могут пройти дополнительный этап выравнивания предпочтений для удаления нежелательных ответов и изменения стиля.
Техники тонкого настроя
Три наиболее популярные техники SFT:
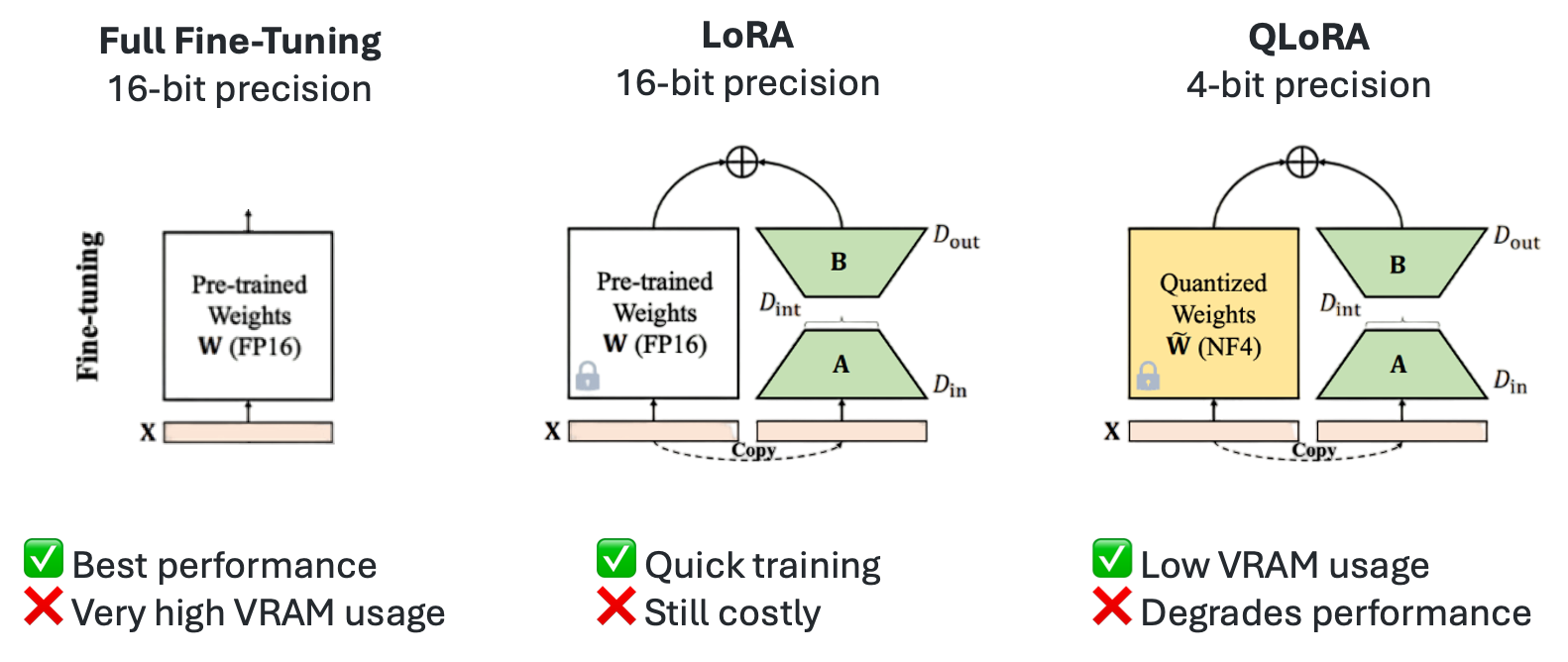
- Полный тонкий настрой — переобучение всех параметров модели, требует значительных вычислительных ресурсов
- LoRA (Low-Rank Adaptation) — параметрически эффективная техника, обучающая менее 1% параметров
- QLoRA — расширение LoRA с дополнительной экономией памяти до 33%
Пока все бегут за многоразовыми API-вызовами к закрытым моделям, умные разработчики уже кастомизируют Llama 3.1 под свои нужды. QLoRA с Unsloth — это как найти секретный проход в игре: те же результаты, но в разы дешевле и с полным контролем над моделью. Правда, придется разобраться с низкоранговыми адаптерами вместо простых промптов.
Практическая реализация
Для эффективного тонкого настроя модели Llama 3.1 8B используется библиотека Unsloth, которая обеспечивает 2-кратное ускорение обучения и 60% экономию памяти по сравнению с другими решениями. Это особенно важно в среде с ограниченными ресурсами, такой как Google Colab.
В примере используется QLoRA тонкая настройка на датасете mlabonne/FineTome-100k — ультра-качественном наборе данных, включающем диалоги, задачи на рассуждения и вызов функций.
Кодовая реализация
Установка необходимых библиотек:
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install --no-deps "xformers<0.0.27" "trl<0.9.0" peft accelerate bitsandbytes
Загрузка модели в 4-битной точности (5.4 GB вместо 16 GB) значительно ускоряет процесс:
import torch from trl import SFTTrainer from datasets import load_dataset from transformers import TrainingArguments, TextStreamer from unsloth.chat_templates import get_chat_template from unsloth import FastLanguageModel, is_bfloat16_supported
Такой подход позволяет эффективно настраивать большие модели даже на ограниченном железе, открывая возможности кастомизации ИИ для более широкого круга разработчиков.





Оставить комментарий