
Оглавление
Китайская лаборатория искусственного интеллекта Deepseek представила языковую модель Deepseek V3.2, которая по ключевым тестам на рассуждение и решению задач сравнялась с флагманскими коммерческими моделями OpenAI GPT-5 и Google Gemini 3 Pro. Более того, её экспериментальная версия достигла уровня золотой медали на Международной математической олимпиаде (IMO) 2025 года. Главный сюрприз: модель выпущена под открытой лицензией Apache 2.0, что меняет расклад сил на рынке.
Технические улучшения в Deepseek V3.2
Разработчики выделили три главные слабости современных открытых моделей: неэффективная обработка длинных текстов, слабые возможности автономных агентов и недостаточные инвестиции в пост-тренинг. V3.2 атакует эти проблемы с двух флангов.
- Deepseek Sparse Attention (DSA): Новая архитектура внимания, которая вместо перепроверки каждого предыдущего токена использует небольшую индексную систему для выявления только важных частей истории текста. Это снижает вычислительные затраты на длинных контекстах без потери качества.
- Масштабный пост-тренинг: На этап дообучения с подкреплением и выравнивания теперь тратится более 10% от изначальных затрат на предварительное обучение. Два года назад этот показатель составлял около 1%. Для генерации данных обучения команда сначала создала специализированные модели для математики, программирования, логики и агентских задач, которые затем готовили данные для финальной модели. Было также построено более 1800 синтетических сред и тысячи исполняемых сценариев на основе реальных GitHub Issues.
То, как Deepseek атакует слабые места открытых моделей, напоминает хирургическую операцию. Они не просто увеличивают параметры, а целенаправленно перепроектируют архитектуру внимания и вкладываются в качество пост-тренинга — области, которые многие недофинансировали. Особенно иронично, что стратегия «больше предобучения», которую некоторые исследователи списывали со счетов, снова в игре. Это показывает, что в гонке ИИ еще много неразведанных путей, а не только дорогостоящее масштабирование.
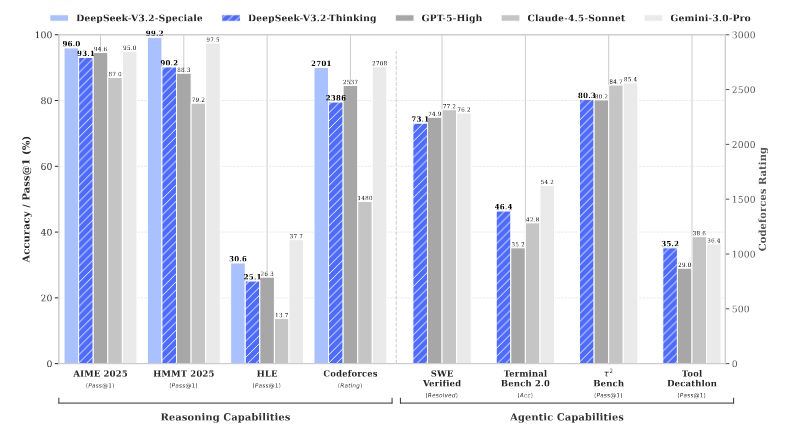
Сравнительные показатели: битва гигантов
В тестах V3.2 демонстрирует впечатляющую конкурентоспособность. Вот ключевые результаты:
- AIME 2025 (математика): Deepseek V3.2 — 93.1%, GPT-5 (High) — 94.6%, Gemini 3 Pro — 95.0%.
- LiveCodeBench (программирование): V3.2 — 83.3%, GPT-5 — 84.5%, Gemini 3 Pro — 90.7%.
- SWE Multilingual (разработка на основе GitHub Issues): V3.2 решает 70.2% проблем, значительно опережая GPT-5 (55.3%), но отставая от Gemini 3 Pro (54.2% в другом тесте).
- Terminal Bench 2.0: V3.2 показывает 46.4% против 35.2% у GPT-5.
Таким образом, модель не просто догоняет, а в некоторых практических задачах, связанных с разработкой, обходит текущие версии GPT-5.
Математическая корона и открытый исходный код
Настоящий прорыв связан с экспериментальным вариантом Deepseek V3.2 Speciale, в котором ослаблены ограничения на длину цепочек рассуждения. Эта версия:
- Заняла 10-е место и получила золото на Международной олимпиаде по информатике (IOI) 2025.
- Заняла второе место на финале ICPC World Final 2025.
- Интегрировав компоненты Deepseek Math V2, достигла золотого уровня на Международной математической олимпиаде (IMO) 2025.
Этим летом OpenAI и Google DeepMind анонсировали модели, способные на подобное, что многие считали невозможным для чистых языковых моделей. Deepseek не только повторил этот результат, но и сделал его общедоступным, пока конкуренты лишь обещают улучшенные версии «в ближайшие месяцы».
Однако за мощность Speciale приходится платить: для решения задач с Codeforces ей требуется в среднем 77 000 токенов, тогда как Gemini 3 Pro справляется с 22 000. Из-за высоких затрат и задержек в стандартной V3.2 применены строгие лимиты на токены.
Где модель еще отстает и как ее получить
Разработчики признают, что V3.2 все еще уступает коммерческим фронтирным моделям в трех аспектах: широте знаний, эффективности использования токенов и производительности на самых сложных задачах. Планируется устранить разрыв в знаниях через дополнительное предобучение.
Модель доступна здесь и сейчас по адресу Hugging Face и через API. Это прямой вызов ценовой политике OpenAI, предлагающий более дешевую альтернативу для агентских рабочих процессов. V3.2 также превосходит другие открытые модели, такие как Kimi K2 Thinking и MiniMax M2, при работе с Model Context Protocol (MCP).
По материалам The Decoder.





Оставить комментарий