
Китайская компания DeepSeek анонсировала экспериментальную модель V3.2-exp с технологией разреженного внимания, которая потенциально способна сократить стоимость API-вызовов вдвое при работе с длинными контекстами. Модель доступна на Hugging Face вместе с техническим документом на GitHub.
Как работает технология разреженного внимания
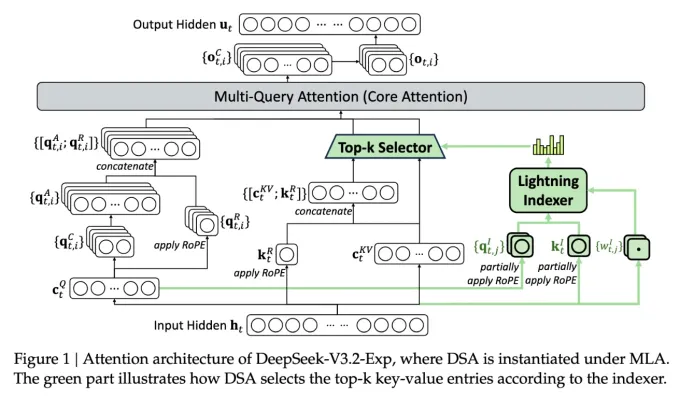
Ключевой инновацией стала система DeepSeek Sparse Attention, состоящая из двух модулей:
- Lightning indexer — идентифицирует релевантные фрагменты в длинном контексте
- Fine-grained token selection system — выбирает конкретные токены для обработки
Вместо обработки всего контекста целиком, система фокусируется только на наиболее значимых частях, что значительно снижает вычислительную нагрузку.
Экономический эффект
По предварительным оценкам DeepSeek, стоимость API-запросов при работе с длинными контекстами может снизиться на 50%. Хотя требуются дополнительные независимые тесты, открытая доступность модели позволяет быстро проверить эти заявления.
Разреженное внимание — это не революция, а эволюция трансформерной архитектуры. Технология решает фундаментальную проблему квадратичной сложности внимания, но требует тщательной балансировки между производительностью и качеством. Интересно, что прорыв приходит из Китая, где инженеры часто вынуждены оптимизировать вычисления из-за ограниченного доступа к самым мощным GPU.
Контекст и перспективы
DeepSeek продолжает удивлять нестандартными подходами — после модели R1, обученной преимущественно через обучение с подкреплением, компания снова демонстрирует инженерную изобретательность. В отличие от американских коллег, которые часто полагаются на грубую силу вычислительных мощностей, китайские разработчики вынуждены искать более эффективные алгоритмические решения.
Технология разреженного внимания может стать важным шагом в снижении операционных затрат для провайдеров ИИ-сервисов, особенно в регионах с высокой стоимостью облачных вычислений.
По материалам TechCrunch.





Оставить комментарий