
Оглавление
Компания Deep Cogito представила Cogito v2.1 671B — крупнейшую и самую производительную открытую языковую модель среди разработок американских компаний. Модель демонстрирует конкурентные результаты на отраслевых бенчмарках и внутренних тестах, опережая другие открытые модели из США.
Ключевые особенности релиза
Новая модель предлагает несколько важных преимуществ:
- Эффективное использование токенов: благодаря улучшенным способностям к рассуждению модель требует значительно меньше токенов по сравнению с аналогами аналогичной мощности
- Улучшенное следование инструкциям: лучше понимает и выполняет сложные запросы
- Продвинутые возможности программирования: демонстрирует высокие результаты в кодинге
- Работа с длинными запросами: эффективно обрабатывает объемные тексты
- Многоуровневые диалоги: поддерживает сложные многократные взаимодействия
- Креативность: показывает улучшенные творческие способности
Доступность модели
Веса модели доступны на Huggingface, а также через API на платформах OpenRouter, Fireworks AI, Together AI, Ollama’s cloud, Baseten и RunPod.
Для локального запуска можно использовать Ollama или Unsloth. Также доступен бесплатный чат-интерфейс на chat.deepcogito.com без сохранения истории диалогов.
Технические характеристики
Cogito v2.1 представляет собой Mixture of Experts модель с 671 миллиардами параметров в формате BF16, занимающую примерно 1.3 ТБ для хранения параметров. Для запуска потребуется как минимум 8 B200 (1 узел) или 16 H200 (2 узла). Для обслуживания на 8 H200 доступна квантованная версия deepcogito/cogito-671b-v2.1-FP8.
Производительность и оценка
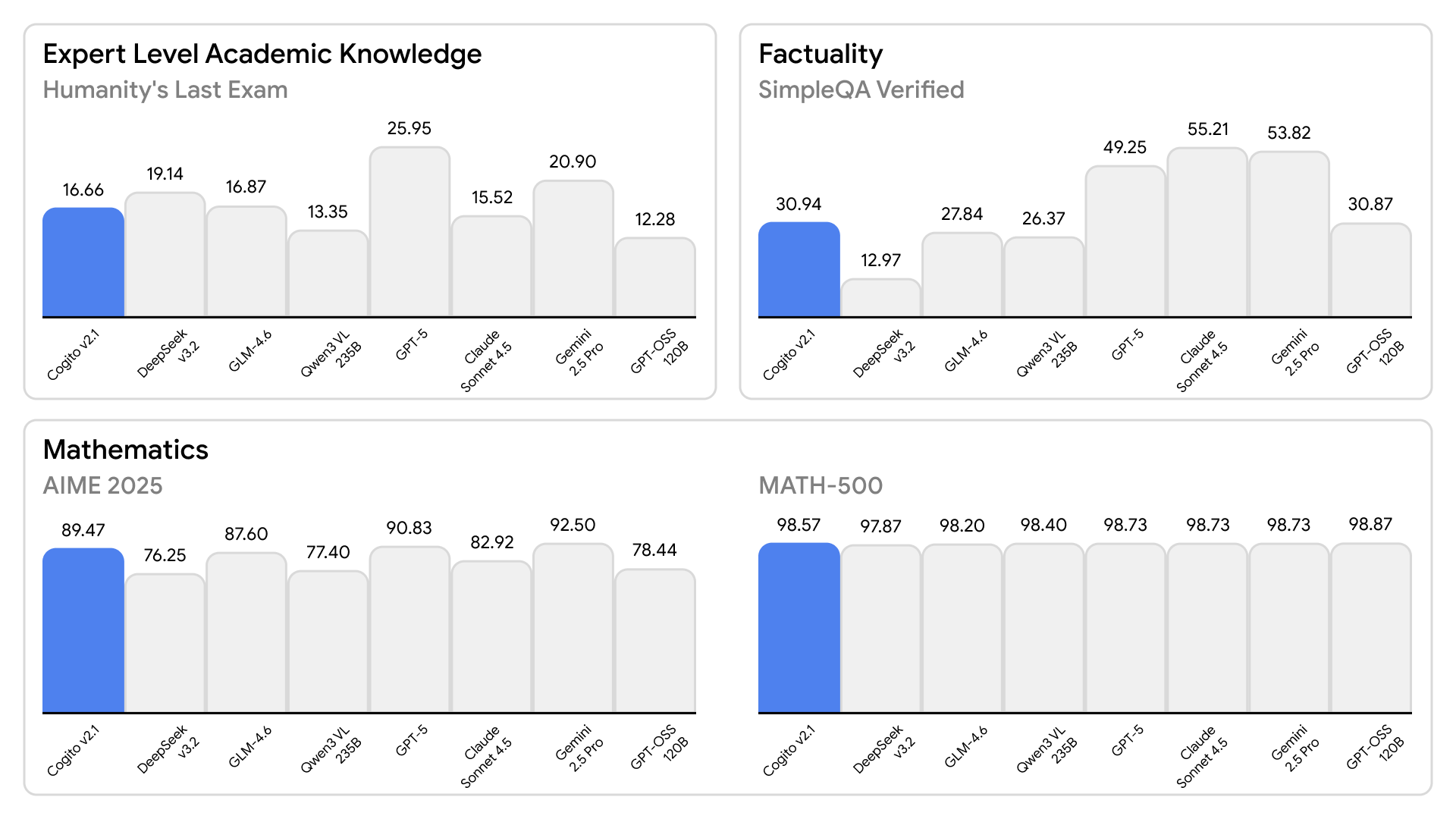
Модель прошла оценку на стандартных бенчмарках, хотя разработчики отмечают, что такие тесты не полностью отражают реальную производительность.

Особенностью Cogito является обучение через процесс супервизии для цепочек рассуждений. Это позволяет модели развивать более сильную интуицию для правильного поискового траектории во время процесса рассуждения, не требуя длинных цепочек рассуждений для достижения правильного ответа.
Cogito v2.1 использует наименьшее среднее количество токенов среди моделей рассуждений аналогичных возможностей.
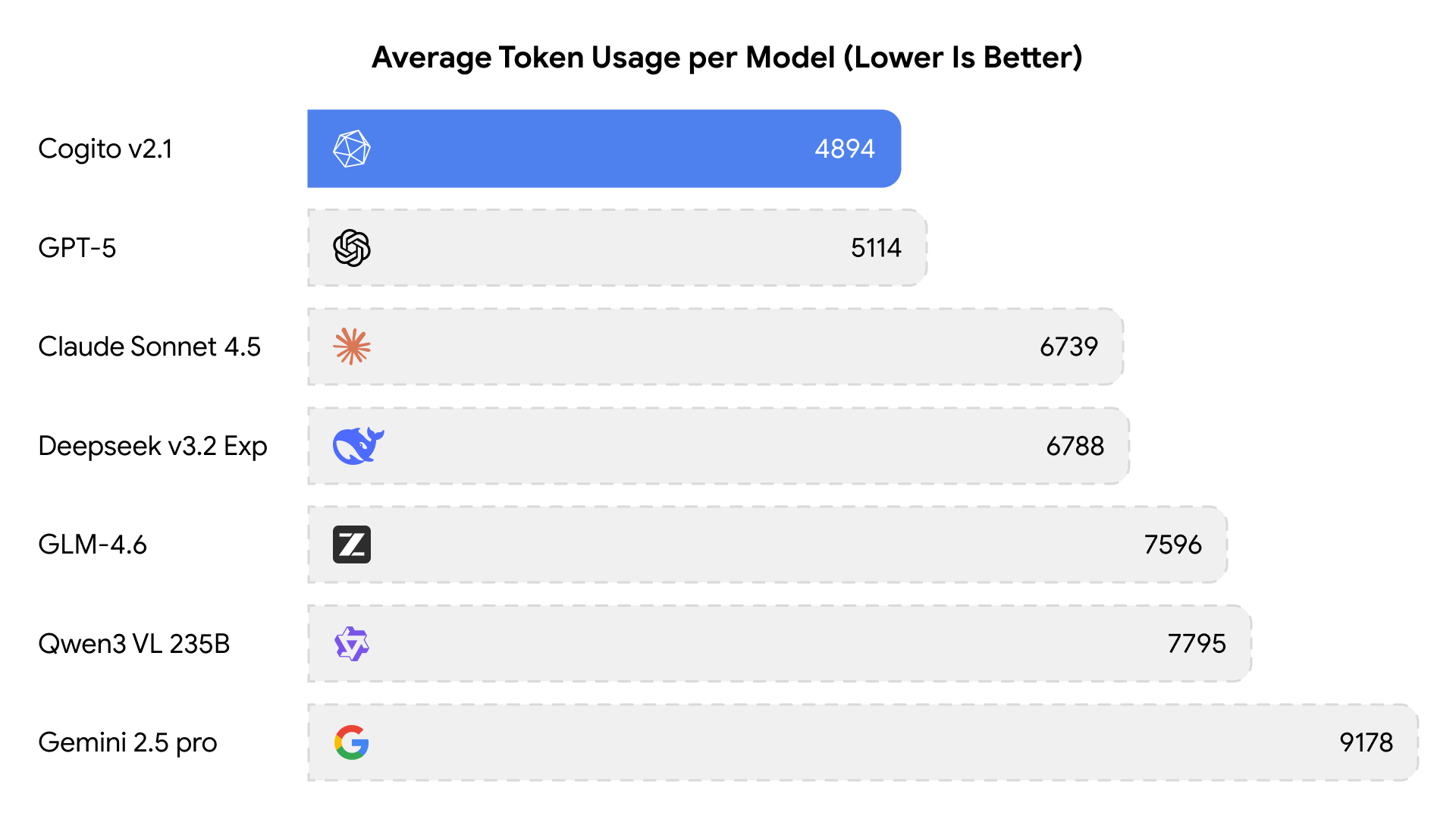
Появление таких моделей как Cogito v2.1 меняет расстановку сил на рынке открытых LLM. Американские компании демонстрируют, что могут конкурировать с мировыми лидерами, при этом сохраняя открытость весов модели. Особенно впечатляет эффективность использования токенов — это не просто очередной гигантский параметрический монстр, а действительно оптимизированное решение, которое может быть экономически выгодным для развертывания.
Примеры использования
С HuggingFace pipeline
import torch
from transformers import pipeline
model_id = "deepcogito/cogito-671b-v2.1"
pipe = pipeline("text-generation", model=model_id, model_kwargs={"dtype": "auto"}, device_map="auto")
messages = [
{"role": "system", "content": "Always respond in 1-2 words."},
{"role": "user", "content": "Who created you?"},
]
## without reasoning
outputs = pipe(messages, max_new_tokens=512, tokenizer_encode_kwargs={"enable_thinking": False})
print(outputs[0]["generated_text"][-1])
# {'role': 'assistant', 'content': 'Deep Cogito'}
## with reasoning
outputs = pipe(messages, max_new_tokens=512, tokenizer_encode_kwargs={"enable_thinking": True})
print(outputs[0]["generated_text"][-1])
# {'role': 'assistant', 'content': 'The question is asking about my creator. I know that I\'m Cogito, an AI assistant created by Deep Cogito, which is an AI research lab. The question is very direct and can be answered very briefly. Since the user has specified to always respond in 1-2 words, I should keep my answer extremely concise.\n\nThe most accurate 2-word answer would be "Deep Cogito" - this names the organization that created me without any unnecessary details. "Deep Cogito" is two words, so it fits the requirement perfectly.\n\nDeep Cogito'}
С HuggingFace AutoModel
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepcogito/cogito-671b-v2.1"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
messages = [
{"role": "system", "content": "Always respond in 1-2 words."},
{"role": "user", "content": "Who created you?"}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
# To enable reasoning, set `enable_thinking=True` above.
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
С vLLM
from transformers import AutoTokenizer
from vllm import SamplingParams, LLM
model_id = "deepcogito/cogito-671b-v2.1-FP8"
tokenizer = AutoTokenizer.from_pretrained(model_id)
llm = LLM(model=model_id, tensor_parallel_size=8, gpu_memory_utilization=0.95, max_model_len=16384)
sampling_params = SamplingParams(temperature=0.6, max_tokens=8192)
prompts = ["who created you?", "how are you doing?"]
prompts = [
tokenizer.apply_chat_template(
[{"role": "system", "content": "Always respond in 1-2 words."}, {"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
for prompt in prompts
]
# To enable reasoning, set `enable_thinking=True` above.
out = llm.generate(prompts, sampling_params=sampling_params)
print([res.outputs[0].text for res in out])
С SGLang
Запуск локального эндпоинта:
# H200s python3 -m sglang.launch_server --model deepcogito/cogito-671b-v2.1-FP8 --tp 8 # B200s python3 -m sglang.launch_server --model deepcogito/cogito-671b-v2.1-FP8 --tp 8 --quantization compressed-tensors --moe-runner-backend triton
Запрос к модели:
import openai
client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "Always respond in 1-2 words."},
{"role": "user", "content": "Who created you?"},
],
temperature=0.6,
max_tokens=8192,
extra_body = {"chat_template_kwargs": {"enable_thinking": False}}
)
# To enable reasoning, set `enable_thinking=True` above.
print(response.choices[0].message.content)
По сообщению HuggingFace, релиз знаменует собой важный шаг в развитии открытых языковых моделей высокой мощности.





Оставить комментарий