Оглавление
Компания Cloudflare представила Infire — новый высокоэффективный движок для вывода языковых моделей, разработанный специально для работы в распределенной edge-инфраструктуре. Решение написано на Rust и демонстрирует до 7% прироста производительности по сравнению с популярным vLLM на оборудовании H100 NVL.
Проблема централизованного AI в распределенном мире
Традиционные подходы к inference-вычислениям предполагают использование крупных централизованных датацентров с дорогостоящими GPU. Для Cloudflare с ее глобально распределенной сетью, находящейся в радиусе 50 мс от 95% интернет-населения, такая модель не подходит. Растущая сложность и размеры AI-моделей только усугубляют проблему.
Переход на собственный inference-движок — это не прихоть, а необходимость для edge-провайдеров. Стандартные решения не учитывают специфику распределенных сетей с их требованиями к безопасности, ресурсам и динамическому масштабированию.
Почему vLLM не подошел для edge
Хотя vLLM остается отличным решением для датацентров, он имеет фундаментальные ограничения для edge-среды:
- Написан на Python, что создает overhead и ограничивает низкоуровневую оптимизацию
- Не поддерживает совместное размещение нескольких моделей на одном GPU без MIG
- Требует дополнительной изоляции через gvisor, что увеличивает потребление CPU и время запуска
- Плохо адаптирован к динамическим workload распределенных сетей
Архитектурные преимущества Infire
Infire построен на трех ключевых компонентах: HTTP-сервер с OpenAI-совместимым API, батчер и собственно движок inference. Решение использует несколько инновационных подходов:
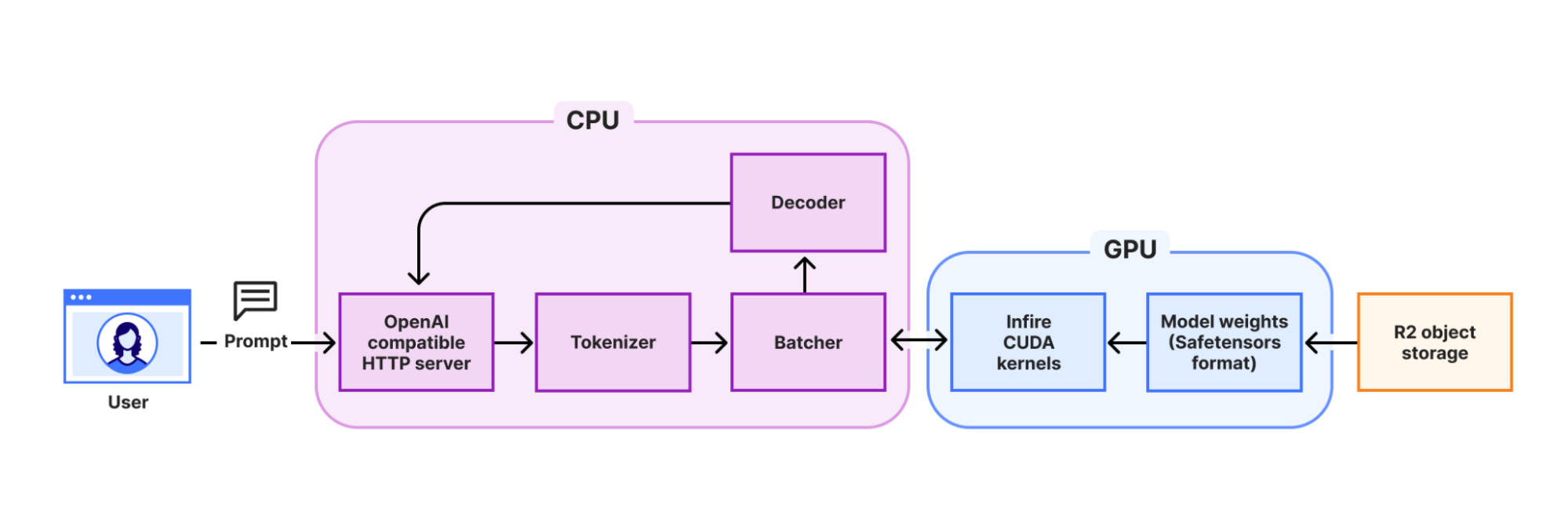
При запуске модели система параллельно загружает веса из R2 object storage и компилирует необходимые ядра, сокращая общее время инициализации до 4 секунд для модели Llama-3-8B-Instruct.
Технические особенности реализации
Для максимизации эффективности Infire использует:
- Комбинацию Page Locked memory и асинхронного копирования CUDA через multiple streams
- HTTP-сервер на основе высокопроизводительного crate hyper
- Поддержку формата BF16 для оптимального баланса размера и точности
- Автоматическое масштабирование и динамическое распределение моделей по GPU
Уже сейчас Infire powers модель Llama 3.1 8B для Workers AI, демонстрируя значительное улучшение utilization GPU и снижение нагрузки на CPU.
По материалам Cloudflare Blog





Оставить комментарий