
Оглавление
Годовая проверка способностей ChatGPT к суммаризации научных статей показала удручающие результаты: языковая модель жертвует точностью ради простоты и требует такого же уровня проверки фактов, как и ручное написание с нуля, сообщает Ars Technica.
Методология тестирования
С декабря 2023 по декабрь 2024 года исследователи Американской ассоциации содействия развитию науки (AAAS) отбирали до двух статей в неделю для суммаризации с помощью ChatGPT. Тестирование проводилось на самых современных публично доступных версиях GPT-4 и GPT-4o через платную подписку Plus.
Было проанализировано 64 научные работы с различной степенью сложности: технический жаргон, спорные выводы, прорывные открытия, исследования с участием людей и нетрадиционные форматы публикаций.
Результаты: разочаровывающая точность
Количественные оценки журналистов оказались безоговорочно негативными. По вопросу о том, могут ли ChatGPT-рефераты органично вписаться в работы живых авторов, средняя оценка составила всего 2,26 из 5. По критерию «увлекательности» результат был еще хуже — 2,14 из 5.
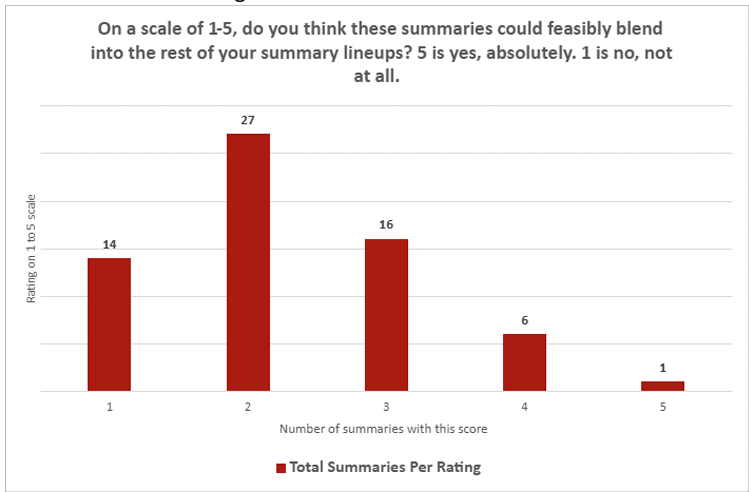
Только один реферат получил высший балл по любому из критериев, в то время как 30 оценок были минимальными («1»).
Качественные недостатки
В качественных оценках журналисты отмечали систематические проблемы:
- Смешение корреляции и причинно-следственной связи
- Отсутствие контекста (например, что мягкие актуаторы обычно очень медленные)
- Чрезмерное использование гиперболических терминов вроде «прорывной» и «новаторский»
- Неспособность анализировать методологии, ограничения и общие следствия исследований
Ирония в том, что ИИ, созданный для обработки информации, оказался беспомощен перед настоящей научной сложностью. Он прекрасно переписывает простые тексты, но как только требуется понять методологию или ограничения исследования — начинает генерировать красивый, но пустой текст. Это напоминает студента, который выучил все термины, но не понимает предмет.
Структурное соответствие vs содержательный провал
Исследователи обнаружили, что ChatGPT обычно хорошо «транскрибирует» написанное в научной статье, особенно если в статье мало нюансов. Однако модель слаба в «переводе» этих находок — анализе методологий, ограничений или более широких последствий.
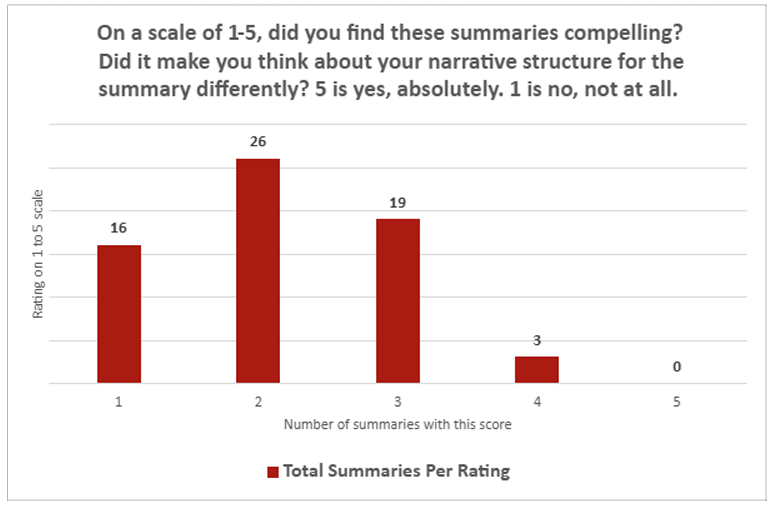
Эти слабости особенно проявлялись в статьях с множественными различными результатами или когда модель пыталась суммаризировать две связанные статьи в один краткий обзор.
Выводы для научной коммуникации
Журналисты AAAS пришли к выводу, что ChatGPT «не соответствует стилю и стандартам кратких обзоров в пресс-пакете SciPak». Даже использование ChatGPT-рефератов в качестве «отправной точки» для человеческого редактирования «потребовало бы столько же, если не больше усилий, чем написание рефератов с нуля» из-за необходимости «тщательной проверки фактов».
Белый документ допускает, что стоит повторить эксперимент, если ChatGPT «претерпит серьезное обновление». Что касается GPT-5, представленного публике в августе 2025 года, то его возможности в научной суммаризации еще предстоит оценить.





Оставить комментарий