Оглавление
Параметры важны, но не решают всё
Хотя количество параметров напрямую влияет на стоимость инференса (векторные матрицы требуют памяти), размер — не гарантия качества. Новые поколения моделей, как Nemotron, обходят предшественников через оптимизацию архитектуры: дистилляцию возможностей и отсев избыточных параметров. Результат — более быстрые ответы, меньшее потребление памяти и улучшенные рассуждения при сравнимой или меньшей сложности.
Методика оценки: точность vs стоимость
Тестирование проводилось на финансовом кейсе через фреймворк syftr, имитирующем работу junior-аналитика. Моделям ставились задачи:
- Анализ отчетов Boeing (10-K, 10-Q)
- Сравнение показателей маржи за периоды
- Объяснение релевантности метрик
Для объективности использовался FinanceBench — датасет с экспертно проверенными ответами.
Глубокий анализ производительности
При построении workflow выявились закономерности:
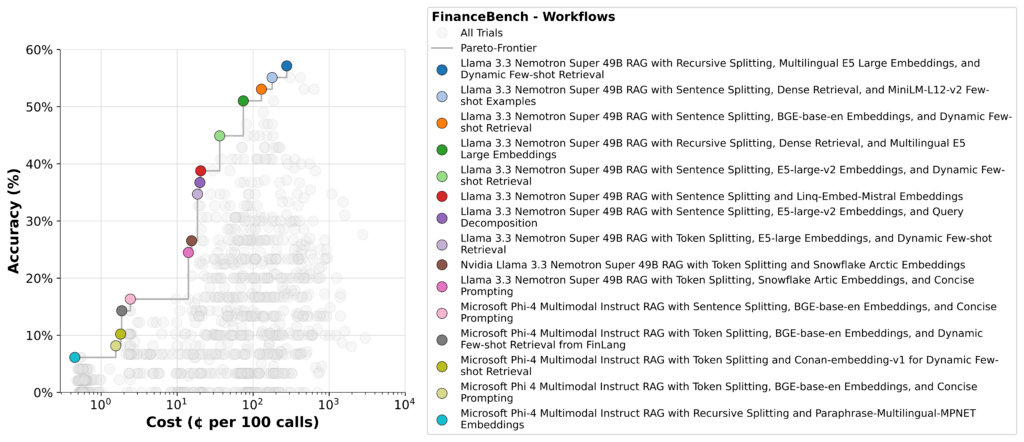
Простые пайплайны с альтернативными моделями (левый нижний угол) были дешевы, но неточны. Сложные агентские стратегии (правый верхний) давали точность, но удорожали инференс в 3-5 раз. Nemotron занял золотую середину на Парето-фронте.
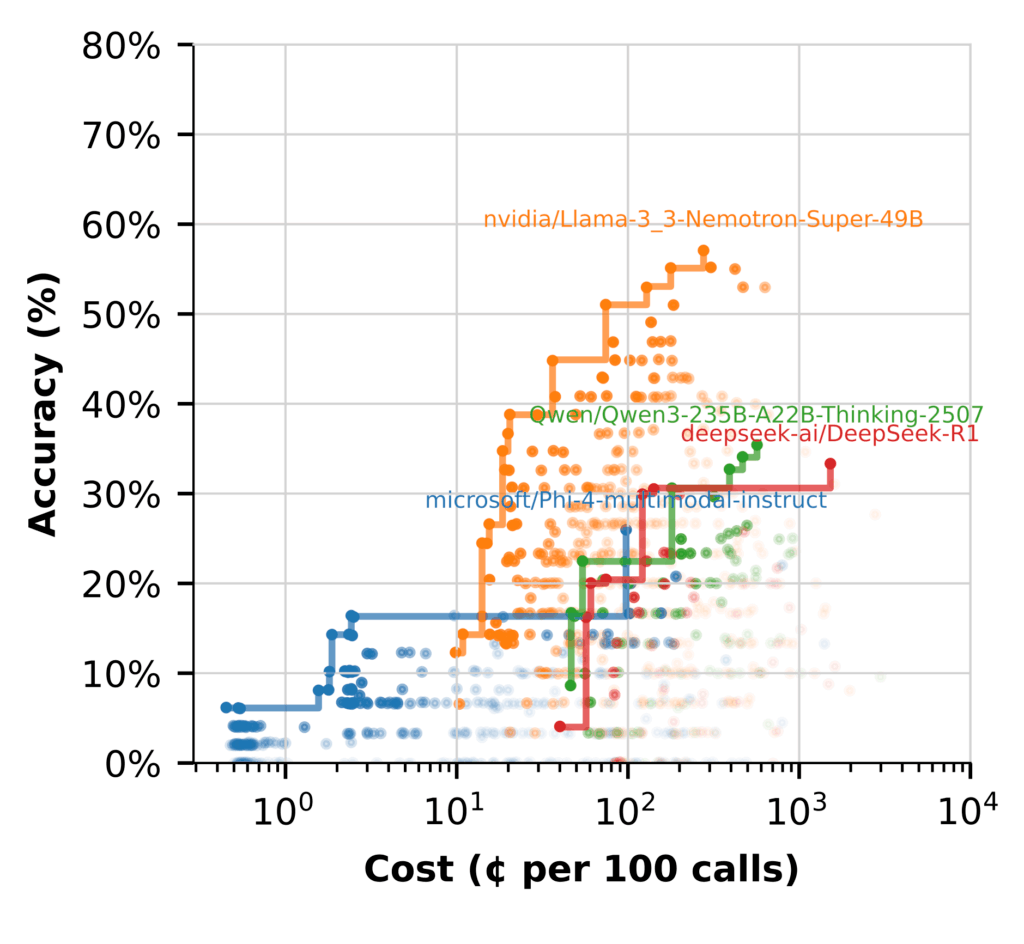
При использовании моделей для синтеза данных разрыв стал очевиден: большинство конкурентов не достигли точности Nemotron даже с инженерией контекста.
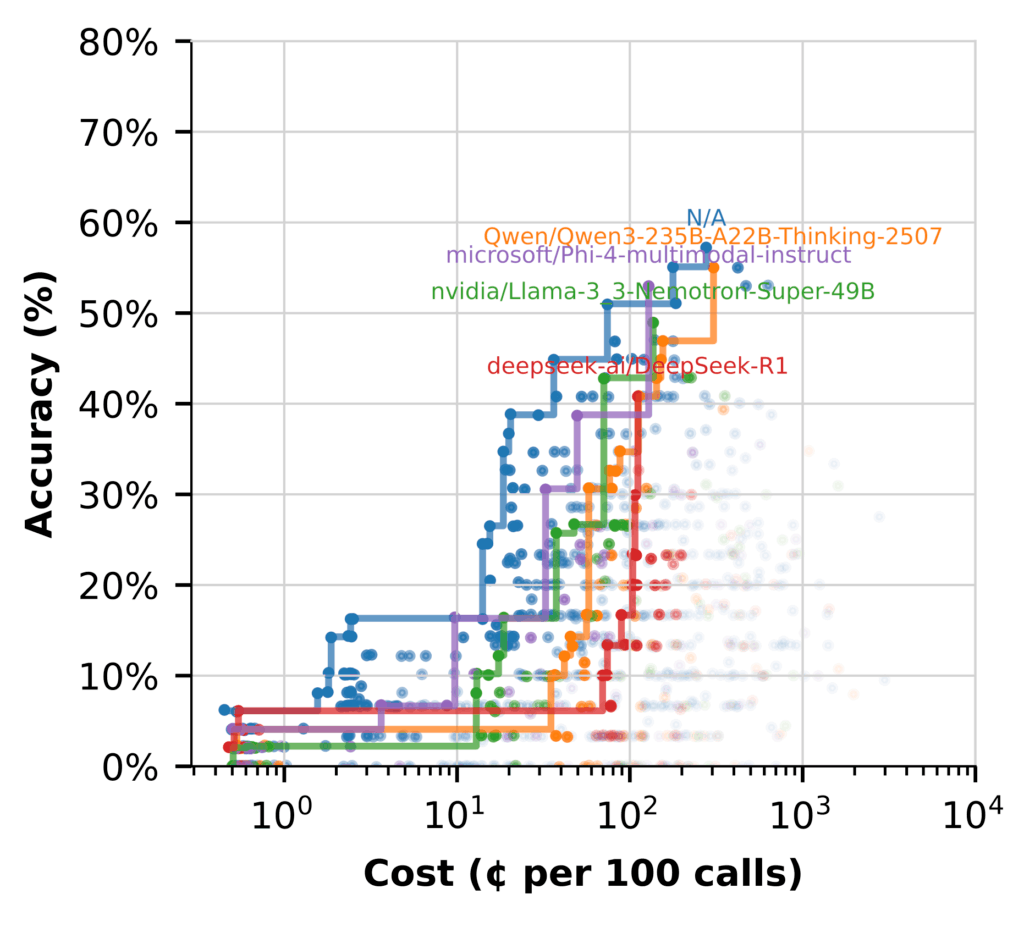
Ситуация изменилась при применении HyDE (Hypothetical Document Embeddings): здесь эффективно проявили себя и другие модели, что подвело к ключевому выводу.
Оптимизация вместо максимизации
Тесты показали:
- Nemotron лидирует в синтезе: даёт точные ответы без доп. затрат
- Гибридные решения эффективнее: HyDE-специалисты + Nemotron для рассуждений
- Баланс точности/стоимости достигается подбором модели под конкретный этап workflow
Как отмечают в DataRobot, оценка должна включать не только accuracy, но и латентность, энергоэффективность и интеграционную совместимость. Репозиторий syftr на GitHub позволяет проводить такие мультикритериальные сравнения.
Nemotron подтверждает тренд: размер модели перестал быть главным KPI. NVIDIA сделала ставку на архитектурную эффективность — и выиграла в практических кейсах финансового анализа, где меньший размер 49B модели не помешал ей обогнать более тяжелых конкурентов. Ключевой урок: тестирование в реальных workflow через syftr важнее абстрактных бенчмарков.
NVIDIA сознательно движется от «гонки параметров» к оптимизации под реальные задачи — и Nemotron удачный пример. Их 49B модель доказала: можно быть компактнее Llama 3 70B, но эффективнее в финансовой аналитике. Однако главное открытие исследования — не мощь отдельной модели, а ценность инструментов типа syftr. Без системного сравнения workflow инженеры рискуют переплачивать за избыточную мощность или терять качество на ложной экономии. В 2025 году «просто запустить LLM» уже недостаточно — нужна инженерия композиции.





Оставить комментарий