
Оглавление
Команда Baidu AI Cloud анонсировала Qianfan-VL — серию мультимодальных языковых моделей, которые демонстрируют исключительные результаты не только в общих бенчмарках, но и в специализированных задачах: OCR, анализе документов и математических рассуждениях. Особенность проекта — полное обучение на отечественных чипах Kunlun с эффективностью масштабирования более 90% на кластере из 5000+ чипов.
Архитектурные решения и четырехэтапное обучение
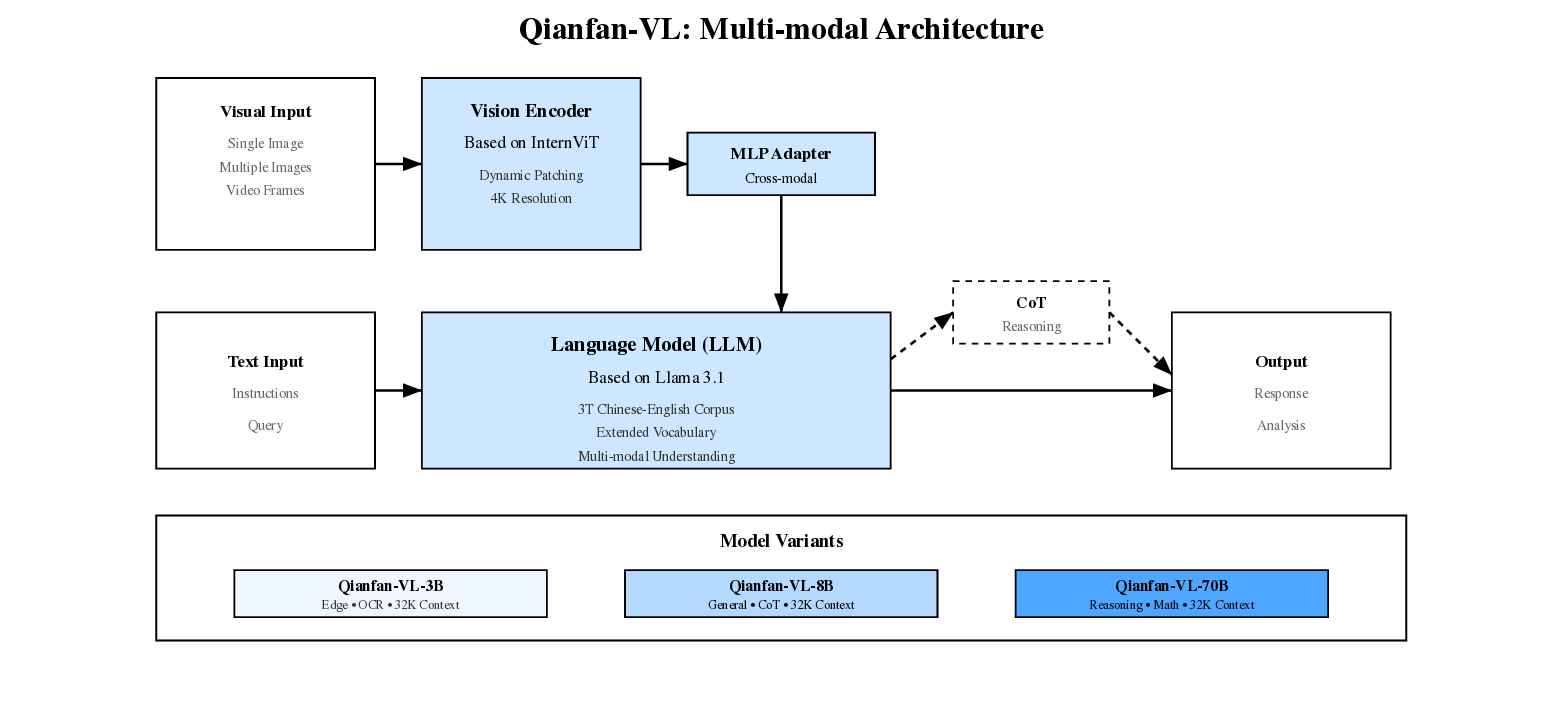
Qianfan-VL использует классическую трехкомпонентную архитектуру:
- Визуальный энкодер на основе InternViT с поддержкой динамического разделения изображений и разрешением до 4K
- Языковая модель Llama 3.1 для версий 8B/70B и Qwen2.5 для 3B версии
- Кросс-модальный адаптер двухслойная MLP-структура для эффективного выравнивания модальностей
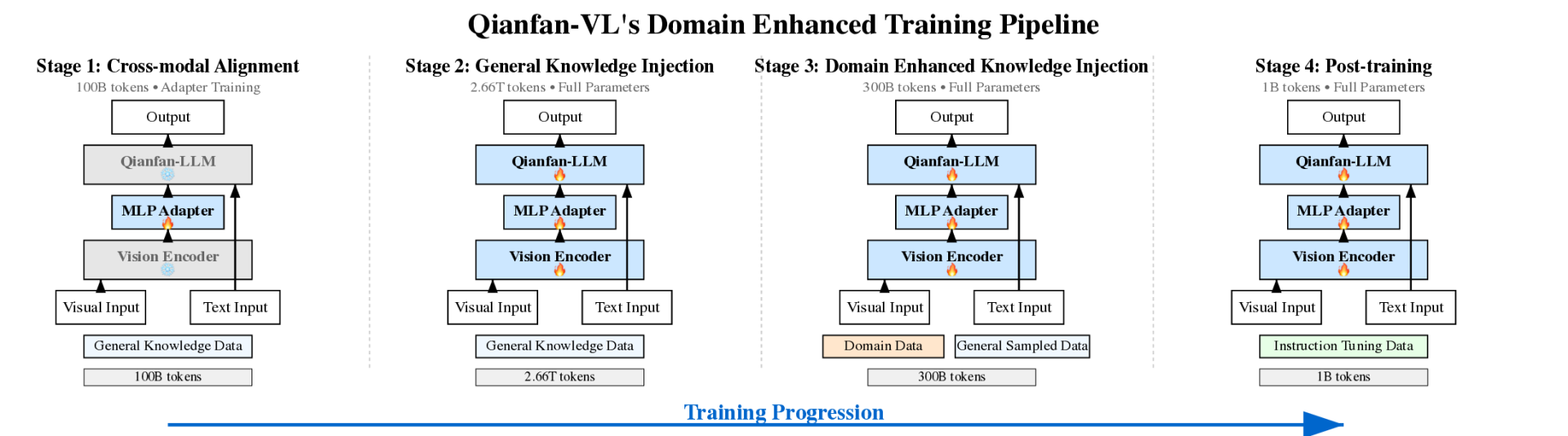
Четырехэтапный процесс обучения представляет собой образцовый пример инженерного подхода:
- Выравнивание модальностей (100B токенов) — обновление только адаптера при замороженных энкодере и языковой модели
- Инъекция общих знаний (2.66T токенов) — полное обновление параметров, 85% данных — OCR и подписи
- Доменное усиление (0.32T токенов) — золотое соотношение 70% доменных данных + 30% общих
- Инструктивное тонкое обучение (1B токенов) — внедрение длинной цепочки рассуждений (CoT)
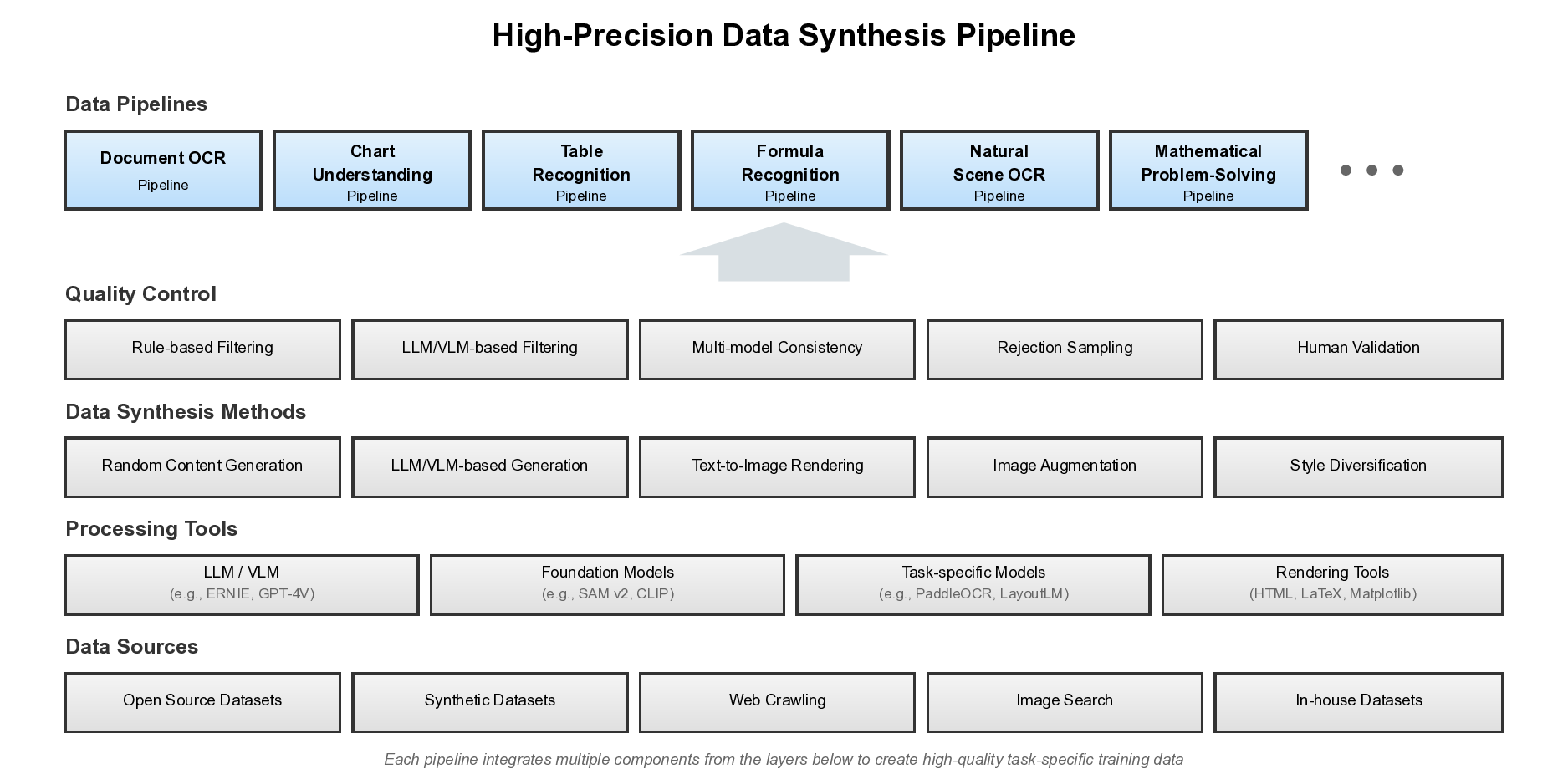
Промышленный конвейер синтеза данных
Команда Qianfan разработала шесть основных конвейеров синтеза данных, охватывающих распознавание документов, математические задачи, анализ графиков, таблиц, формул и сценовый OCR.
Особого внимания заслуживает конвейер синтеза математических задач: от уровня K-12 до университетского, включая подробные шаги решения, имитацию рукописного ввода и различные фоны документов.
Выдающиеся результаты производительности
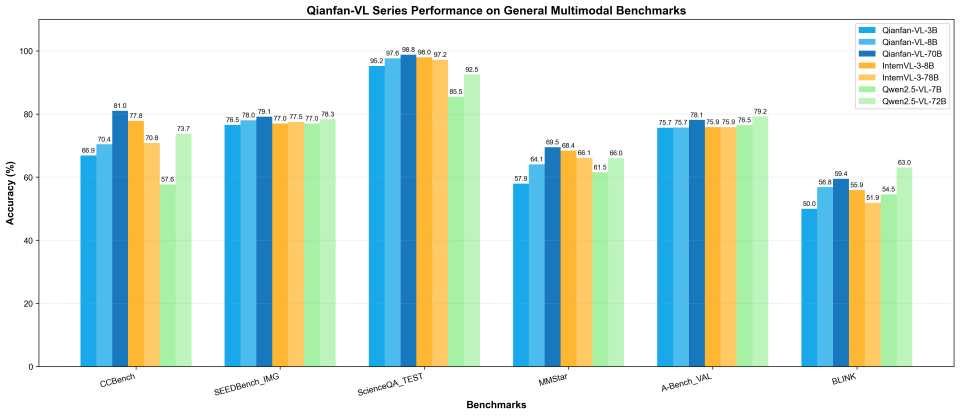
Модель демонстрирует превосходство на 14 стандартных бенчмарках:
- ScienceQA: 98.76% точности (70B версия)
- CCBench: 80.98% — выдающееся понимание китайского языка
- SEEDBench_IMG: 79.13% — отличное визуальное восприятие
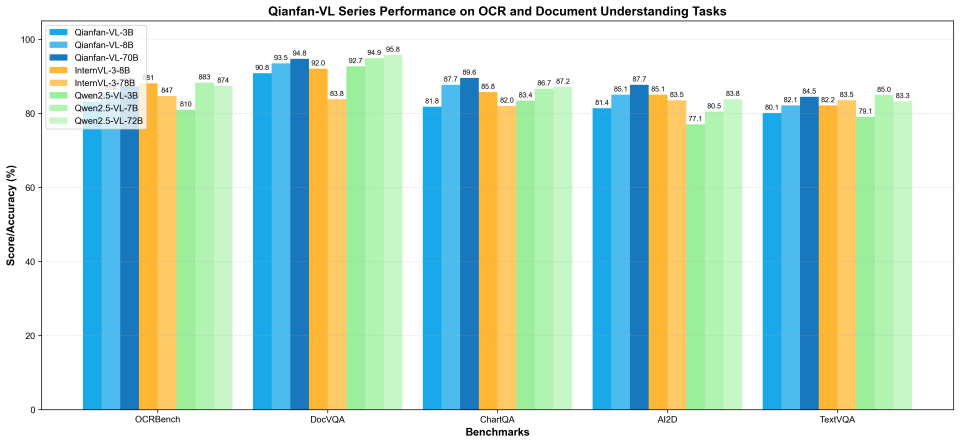
В задачах OCR и анализа документов Qianfan-VL показывает впечатляющие возможности:
- DocVQA: 94.75% — возможности вопросов и ответов по документам высшего уровня
- ChartQA: 89.60% — лидерство в понимании графиков
- OCRBench: 873 балла — сильные комплексные возможности OCR
После внедрения длинной цепочки рассуждений математические способности значительно улучшились:
- MathVista: 78.60% — SOTA среди открытых моделей
- Mathvision: 50.29% — обработка сложных визуальных математических задач
- Mathverse: 61.04% — многошаговые рассуждения
Практические применения: от политики до географии
Модель не только точно идентифицирует трендовые линии, но и анализирует изменения поддержки партий Великобритании, демонстрируя мощное понимание визуализации данных. В примере с тепловой картой Китая модель точно понимает легенды карт и может отвечать на вопросы о покрытии отопления в конкретных регионах.
Инфраструктурное достижение: 5000+ чипов Kunlun
Обучение полностью на чипах Baidu Kunlun P800 представляет собой веху в развитии отечественных AI-чипов:
- Масштаб кластера: 5000+ чипов параллельного обучения
- Эффективность масштабирования: более 90% — мировой уровень
- Стратегия оптимизации: 3D параллелизм (данные + тензор + конвейер)
- Слияние вычислений и коммуникаций: использование уникальной аппаратной архитектуры чипов Kunlun
В то время как западные вендоры спорят об этике ИИ, Baidu тихо демонстрирует, что настоящая инновация происходит в инженерных отделах, а не в комитетах по этике. Обучение модели такого масштаба на собственных чипах — это не просто техническое достижение, а стратегический ход, который переопределяет правила игры в глобальной AI-гонке. Вопрос не в том, «можем ли мы», а в том, «как быстро мы можем масштабироваться» — и Baidu только что дала весьма убедительный ответ.
По материалам Hugging Face





Оставить комментарий