
Оглавление
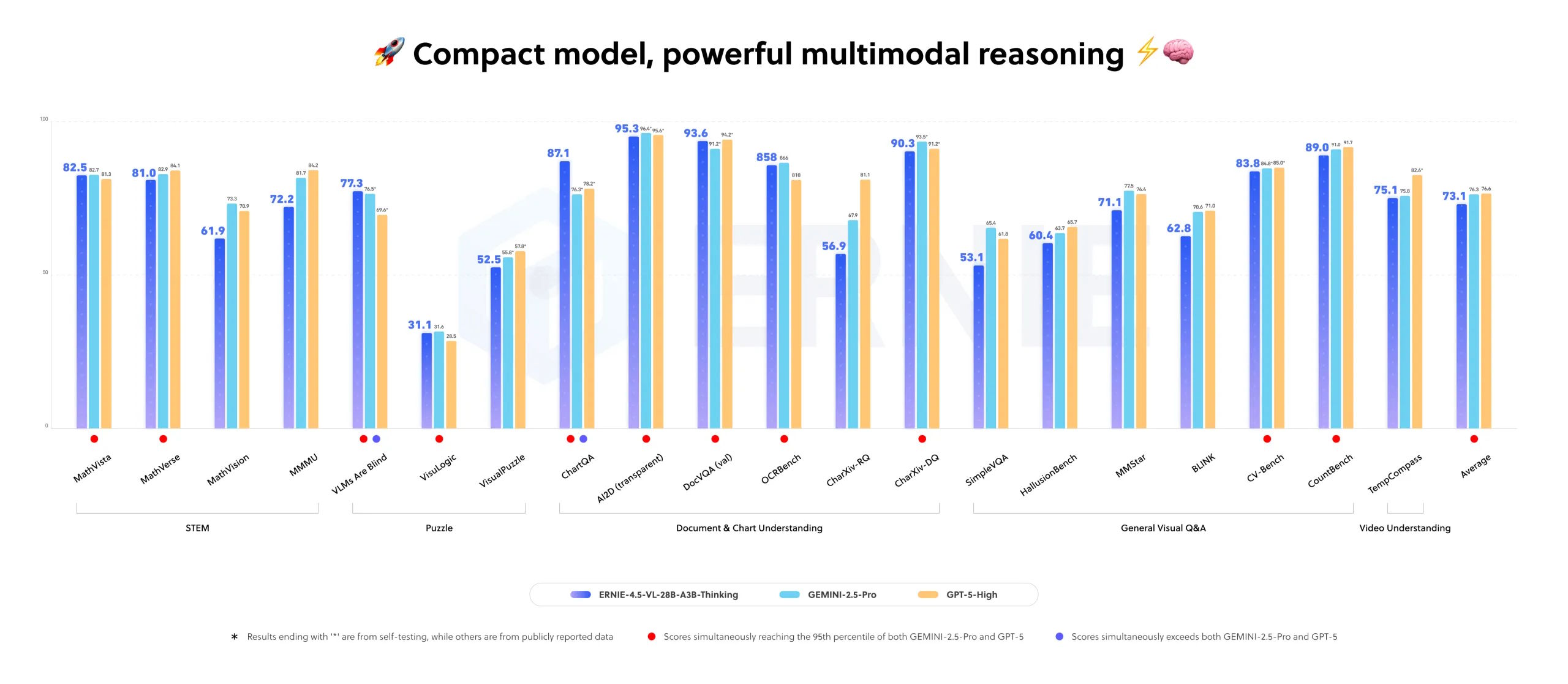
Компания Baidu представила новую модель искусственного интеллекта ERNIE-4.5-VL-28B-A3B-Thinking, способную обрабатывать изображения в процессе логического вывода. По заявлениям разработчика, модель превосходит более крупные коммерческие аналоги, включая Google Gemini 2.5 Pro и OpenAI GPT-5 High в нескольких мультимодальных бенчмарках.
Технические характеристики и доступность
Модель использует всего 3 миллиарда активных параметров из общего числа 28 миллиардов благодаря роутинговой архитектуре, что позволяет ей эффективно работать на одном графическом процессоре объемом 80 ГБ, таком как Nvidia A100. ERNIE-4.5-VL-28B-A3B-Thinking распространяется под лицензией Apache 2.0, что делает ее доступной для коммерческого использования без ограничений.
Заявленные показатели производительности пока не прошли независимую проверку, что оставляет пространство для здорового скептицизма. Однако сам факт появления таких возможностей в открытой модели спустя всего месяцы после их дебюта в проприетарных системах говорит о стремительном развитии конкуренции в области мультимодального ИИ.
Функциональные возможности
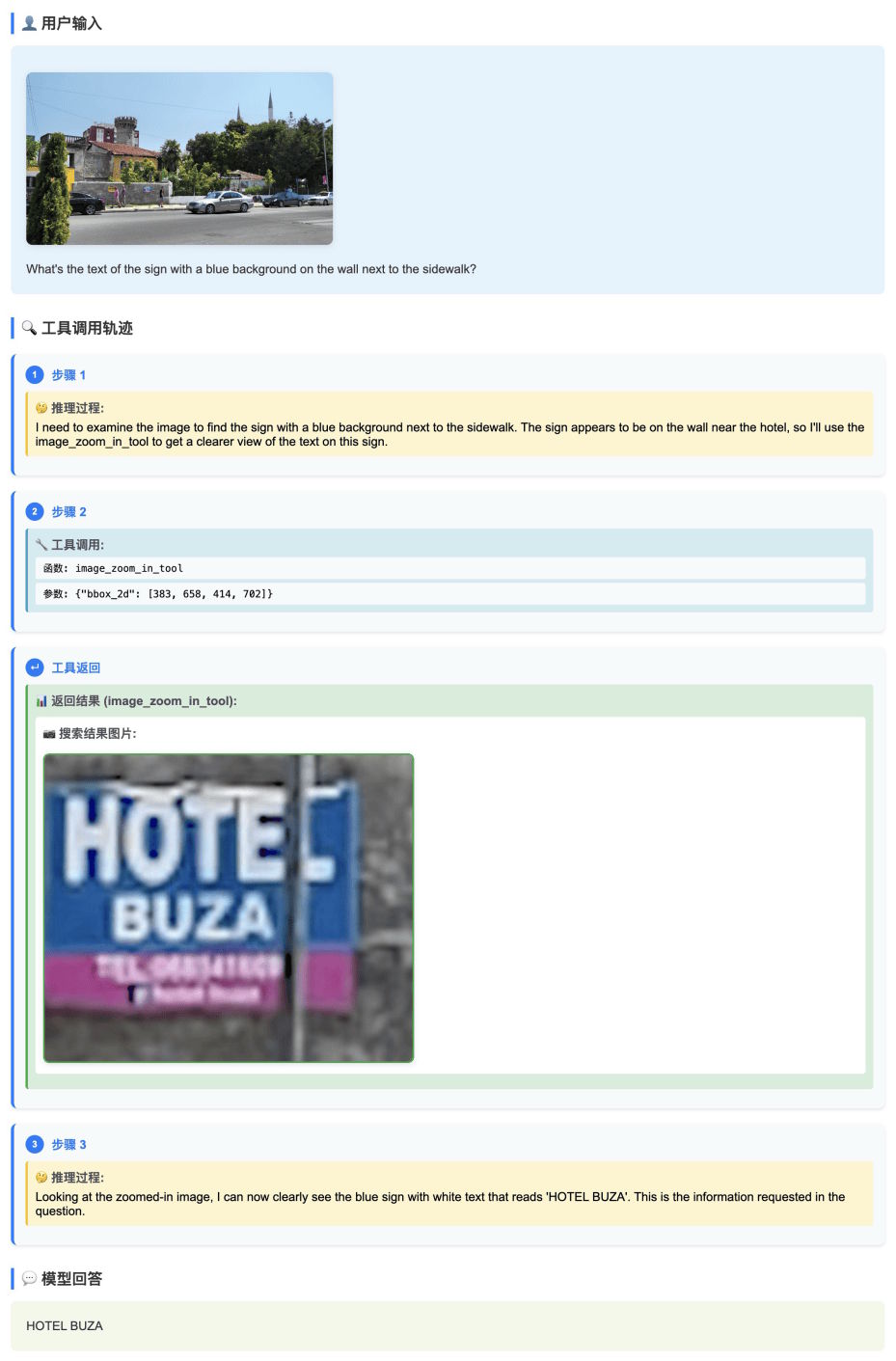
Ключевая особенность модели — функция «Thinking with Images», позволяющая динамически обрезать изображения для фокусировки на важных деталях. В демонстрационных примерах модель автоматически увеличивала синюю вывеску и распознавала текст на ней.
- Точное определение людей на изображениях с возвращением их координат
- Решение математических задач через анализ электрических схем
- Рекомендации оптимального времени посещения на основе анализа графиков
- Извлечение субтитров и сопоставление сцен с временными метками в видео
- Интеграция с внешними инструментами, включая поиск изображений в интернете
Контекст развития технологии
Хотя Baidu позиционирует способность модели обрезать и манипулировать изображениями как инновацию, подобный подход уже был представлен OpenAI в апреле 2025 года в моделях o3 и o4-mini. Эти модели также интегрируют изображения в цепочку логического вывода и используют нативные инструменты масштабирования, обрезки и вращения при работе с визуальными задачами.
Принципиальное отличие заключается в том, что передовые функции визуального мышления, ранее доступные только в проприетарных западных моделях, теперь появляются в открытых китайских решениях всего через несколько месяцев после их дебюта на Западе.
Источник новости: The Decoder





Оставить комментарий