Оглавление
По сообщению HuggingFace, с появлением моделей вроде OpenAI o1 в 2024 году произошла революция в подходе к работе языковых моделей — концепция вычислительных ресурсов во время тестирования позволила моделям тратить больше токенов на сложные задачи, значительно улучшая качество ответов.
Проблема выбора режима работы
С развитием гибридных моделей, таких как Qwen3 с возможностью переключения между режимами мышления, возникла новая задача — как автоматически определить, когда нужно включать режим размышлений, а когда можно обойтись быстрым ответом. Использование медленного, ресурсоемкого режима для простых задач стало раздражающим фактором для пользователей.
Идея автоматического роутера выглядит элегантным решением проблемы, которая становилась все более актуальной с каждым новым релизом моделей от OpenAI и других вендоров. Вместо ручного переключения флажков — умная система сама решает, когда думать, а когда стрелять ответами без лишних раздумий.
Архитектура решения
Для создания маршрутизатора потребовалось собрать парные данные: для каждого пользовательского запроса генерировались два ответа — с включенным и выключенным режимом мышления, с последующей оценкой, какой из подходов дает лучший результат.
Ключевой подход:
- Использование одной базовой модели с разными настройками мышления
- Оценка результатов с помощью модели вознаграждения
- Создание классификатора для автоматического принятия решений
Сбор и разметка данных
Для обучения использовались два типа датасетов:
Открытые датасеты
Эти наборы содержат реальные пользовательские запросы, что делает их максимально приближенными к реальным сценариям использования.
Закрытые датасеты
- AIME-1983-2024-Qwen3-8B (математические олимпиадные задачи)
- Big-Math-RL-Qwen3-8B
Для закрытых задач с известными правильными ответами разметка была более простой — если режим мышления давал правильный ответ, а быстрый режим ошибался, запрос помечался как требующий мышления.
Процесс обучения
После сбора и разметки данных исследователь получил около 70 000 образцов для обучения классификатора. Были протестированы различные архитектуры, включая BERT-варианты и Qwen3-0.6B.
Наиболее эффективными оказались:
- Qwen3-0.6B
- mmBERT-small
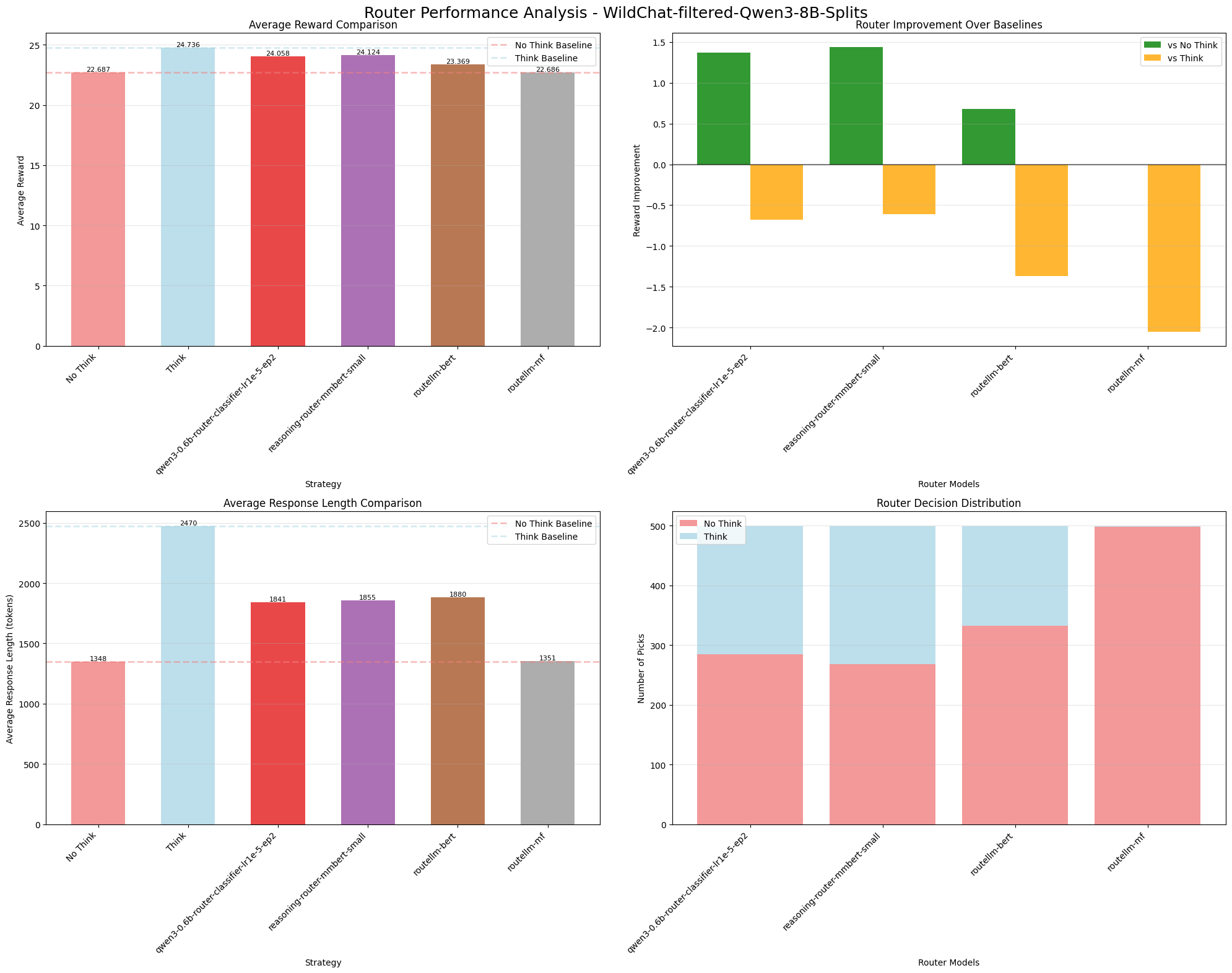
Источник: huggingface.co
Обученная модель доступна для тестирования в Hugging Face Space.
Результаты и перспективы
Модель успешно прошла тестирование на открытых датасетах и новых математических бенчмарках 2025 года, демонстрируя способность эффективно принимать решения о необходимости использования режима мышления.
Этот подход может стать стандартом для всех гибридных моделей будущего — вместо того чтобы заставлять пользователей вручную выбирать между скоростью и качеством, система сама будет принимать оптимальные решения, экономя и время, и вычислительные ресурсы.
Исследование показывает, что автоматическая маршрутизация запросов между разными режимами работы языковых моделей — это не просто удобная функция, а необходимость в эпоху, когда вычислительная эффективность становится таким же важным параметром, как и качество ответов.





Оставить комментарий