
Оглавление
Миллионы пользователей уже общаются с искусственным интеллектом голосом, перейдя от текста к гораздо более сложному миру звука. Реальная человеческая речь полна нюансов, прерывается паузами, самоперебиваниями и исправлениями прямо посреди фразы — как если бы клиент в кафе менял свой заказ, не успев его закончить. Даже самые продвинутые системы ИИ с этим не справляются. Точность в лабораторных условиях, как выясняется, не всегда означает точность в реальном мире.
Чтобы создать голосовых агентов, которые действительно работают, нужно перестать оценивать их по навыкам чтения и начать тестировать их разговорный интеллект. Именно для этого компания Scale представила новый бенчмарк Audio MultiChallenge. Это первый стандарт, созданный для стресс-тестирования разговорной устойчивости нативных моделей «речь-в-речь» (Speech-to-Speech, S2S).
Столпы разговорного интеллекта
Audio MultiChallenge оценивает модели по конкретным компетенциям в диалогах длиной от 2 до 8 реплик. Разработчики выделили четыре ключевых способности, отличающих устойчивого агента от хрупкого:
- Редактирование речи («тест посетителя кафе»). Самое сложное испытание для практического применения. В естественной речи намерение человека нелинейно: мы возвращаемся назад, редактируем и перебиваем себя. Модель на тексте видит конечную, очищенную от помех транскрипцию. Но нативная аудиомодель сначала слышит линейный поток токенов для «салата». Чтобы быть успешной, она должна распознать поправку и «перезаписать» своё первоначальное понимание в реальном времени. Бенчмарк проверяет эти самокоррекции, вмешательства и отступления.
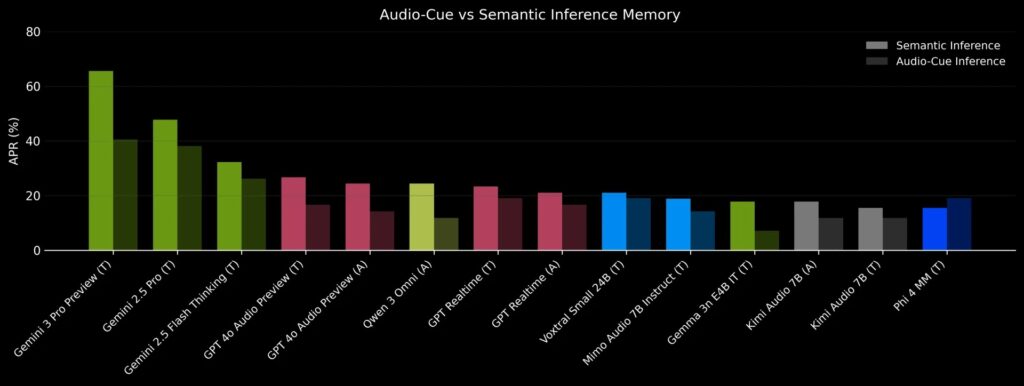
- Память, управляемая аудиоконтекстом. Стандартные бенчмарки часто транскрибируют аудио в текст перед оценкой, удаляя жизненно важный контекст. Audio MultiChallenge проверяет, может ли модель уловить детали, существующие только в исходном аудио, а не в текстовой расшифровке. В тестах модели показывали значительно худшие результаты на таких задачах по сравнению со стандартным семантическим запоминанием.
- Соблюдение инструкций. Тест на способность следовать конкретной директиве («говори от определённого лица», «используй ограниченное количество слов», «избегай негативных фраз») на протяжении всего многоходового диалога. Аудиомодели часто теряют эти инструкции даже в коротких взаимодействиях, а их производительность ещё больше снижается для «условных» указаний.
- Самосогласованность. Оценка внутренней непротиворечивости модели. Тест проверяет, сохраняет ли модель свои собственные факты, временную линию и персонажа, не противореча себе. В длинном голосовом разговоре модель может заявить, что она фитнес-инструктор в первом повороте, но предложить противоречивый, нездоровый совет в пятом.
Результаты тестирования
Когда современные передовые модели прошли тестирование, результаты показали чёткую иерархию и суровую реальность состояния нативного аудио.
Модель Google Gemini 3 Pro Preview оказалась лучшей со средним баллом по рубрике (Average Rubric Score, ARS) 54,7%, продемонстрировав наилучшее понимание разговорных нюансов. За ней следуют Gemini 2.5 Pro (46,9%) и Gemini 2.5 Flash (40,0%). Аудиопревью OpenAI GPT-4o отстало с результатом 25,4%. Это подчёркивает, что хотя задержка и качество голоса улучшаются повсеместно, сложные рассуждения в аудиомодальности остаются важным дифференцирующим фактором.
Результаты бенчмарка / источник: scale
В целом производительность моделей падает на 36,5% относительно, когда их проверяют не только на удержание семантической информации, но и на аудиоконтекст, такой как фоновый шум и паралингвистика говорящего (эмоция или тон). Редактирование голоса — самый сложный аспект, что подчёркивает: модели не устойчивы к колебаниям в середине высказывания или возвратам назад.
Многие нативные модели, особенно настроенные на вывод текста вместо аудио, показывают значительно лучшие результаты на синтетических данных Text-to-Speech (TTS), чем на реальных человеческих записях. Естественные нарушения плавности человеческой речи создают «шум», который снижает производительность некоторых архитектур до 21,5%. Это подтверждает, что обучение и оценка на чистом синтетическом аудио маскируют реальные режимы сбоев. Любопытно, что лучшие модели Gemini были устойчивы к этому шуму, показывая немного лучшие результаты на реальной человеческой речи, чем на TTS.
Когнитивная цена нативных S2S-систем
Нативные модели «речь-в-речь» всё ещё отстают от традиционных каскадных систем (распознавание речи → текстовый LLM) в семантических задачах, в первую очередь потому, что эти системы могут использовать передовые LLM для рассуждений. Frontier LLM, такие как GPT-5 или Claude Opus 4.5, набирают 51,2% и 39,22% соответственно, что намного выше, чем у большинства сквозных речевых архитектур в этой конфигурации.
Любопытно, что в несемантических задачах на «аудиоконтекст» эти каскадные системы всё ещё могут достигать результатов до 36%, несмотря на то, что им подаются только транскрипты и окружающий диалог. Этот результат указывает на то, что понимание аудио, особенно паралингвистики и эмоций, может улучшаться за счёт сильных текстовых рассуждений уже после обучения, тогда как архитектуры S2S в настоящее время жертвуют частью «IQ» ради скорости и выразительности.
Индустрия столкнулась с классической проблемой «лабораторного идеала» против «уличного хаоса». Мы годами тренировали модели на чистых, отполированных данных и удивляемся, почему они спотыкаются о реальность. Результаты Scale — отрезвляющий душ для всех, кто верит в скорое появление полноценных голосовых ассистентов. Лидерство Google Gemini в этом тесте — не случайность, а результат другой философии данных. Пока все гонятся за скоростью ответа и натуральностью голоса, настоящая битва будет происходить в способности модели «держать в уме» весь хаос живого диалога. GPT-4o, с его фокусом на low-latency и мультимодальность, здесь явно проигрывает, и это может стать его ахиллесовой пятой.
Гибридный подход к сбору данных
Чтобы выявить эти провалы, потребовались данные, специально созданные для того, чтобы обнажить трещины в текущих архитектурах. Набор данных Audio MultiChallenge был создан с использованием протокола «человек в петле» по принципу состязательности.
Сначала автоматизированный «Агент-планировщик» генерировал сложные сценарии диалогов, предназначенные для проверки конкретных логических ограничений и ограничений памяти. Затем, вместо чтения по сценарию или использования синтеза речи, реальные люди разыгрывали эти сценарии с моделью в цикле, получив конкретный мандат — «сломать» её. Чтобы обеспечить справедливую оценку этих сложных взаимодействий, разработчики проверили подход «LLM-как-судья» (с использованием o4-mini), который достиг высокой степени согласия с оценками людей.
Этот подход позволил зафиксировать грязные, спонтанные явления, которые упускают синтетические бенчмарки. Поощряя тестеров-людей взаимодействовать естественно, был создан набор данных, отражающий реальные трудности общения с машиной в реальном мире.
Чтобы сократить разрыв между сегодняшними моделями «речь-в-речь» и их текстовыми аналогами, нужны оценки, которые перестанут рассматривать речь как просто «текст вслух». Нужны бенчмарки, которые принимают беспорядок, прерывания и когнитивную нагрузку реального человеческого взаимодействия. С помощью Audio MultiChallenge Scale предоставляет инструмент для измерения прогресса, гарантируя, что следующее поколение ИИ не просто будет нас слышать, но и действительно понимать.
По материалам Scale.





Оставить комментарий