
Оглавление
Архитектура Mixture of Experts копирует эффективность человеческого мозга, активируя только нужных «экспертов» для каждого токена ИИ. Это позволяет генерировать токены быстрее и эффективнее, без пропорционального роста вычислений. В топ-10 самых умных открытых моделей все используют эту архитектуру, включая DeepSeek-R1 от DeepSeek AI, Kimi K2 Thinking от Moonshot AI, gpt-oss-120B от OpenAI и Mistral Large 3 от Mistral AI.
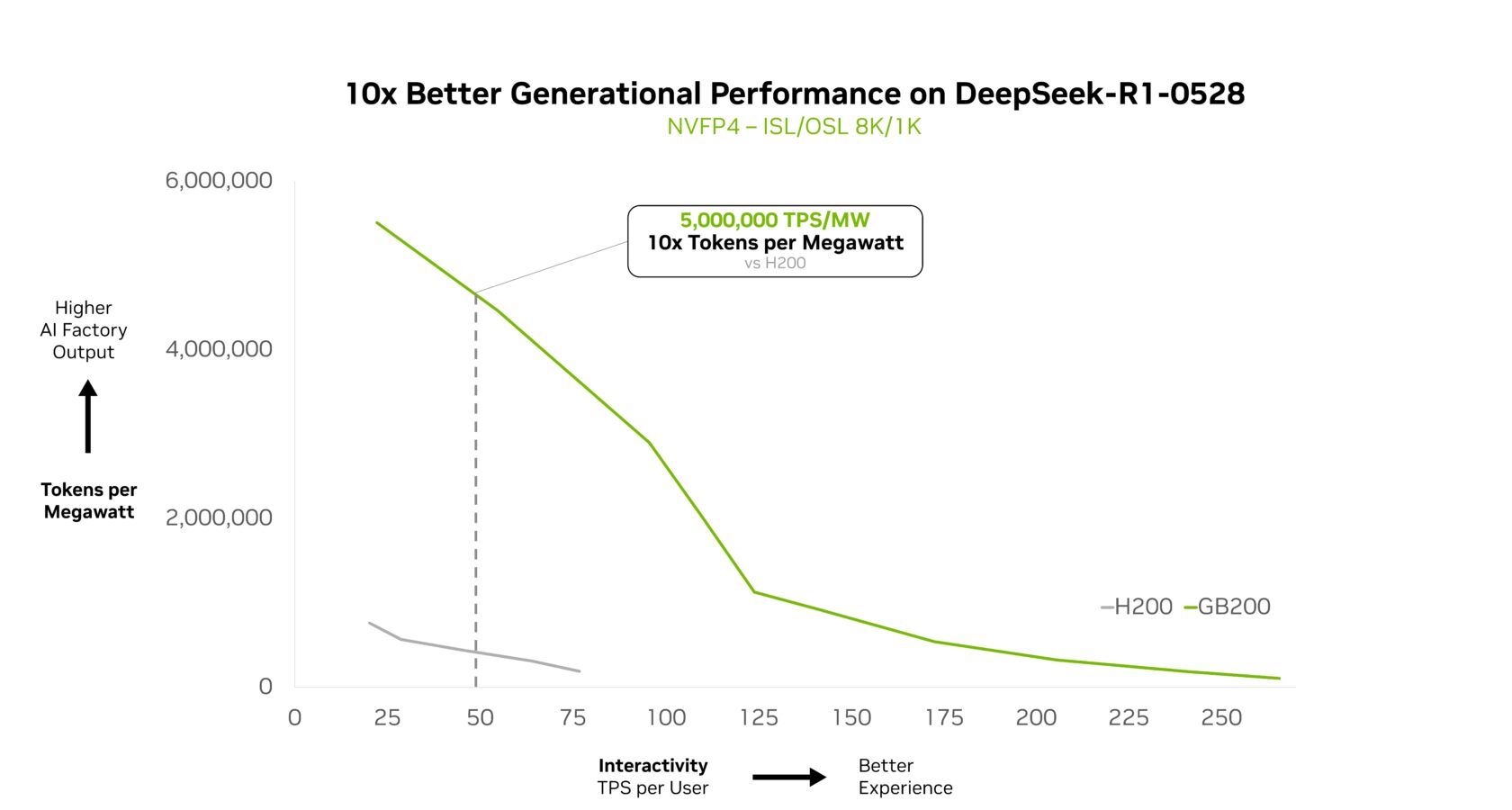
Однако масштабирование таких моделей в продакшене требует мощной аппаратной оптимизации, как в системах NVIDIA GB200 NVL72, где Kimi K2 Thinking работает в 10 раз быстрее, чем на HGX H200.
Что такое MoE и почему она стала стандартом для передовых моделей?
Ранее индустрия полагалась на плотные модели, задействующие все параметры — сотни миллиардов — для каждого токена. Это требовало огромных ресурсов, затрудняя масштабирование. Архитектура смеси экспертов работает иначе: модель состоит из специализированных экспертов, а роутер активирует только релевантных для конкретного токена. Хотя общий объем параметров может достигать сотен миллиардов, для одного токена используются лишь десятки миллиардов.
Источник: blogs.nvidia.com
Как мозг использует разные зоны для задач, модели смеси экспертов выбирают экспертов через роутер для каждого токена. Это повышает интеллект и адаптивность без роста затрат, делая архитектуру фундаментом для эффективных систем ИИ, оптимизированных по производительности на доллар и ватт.
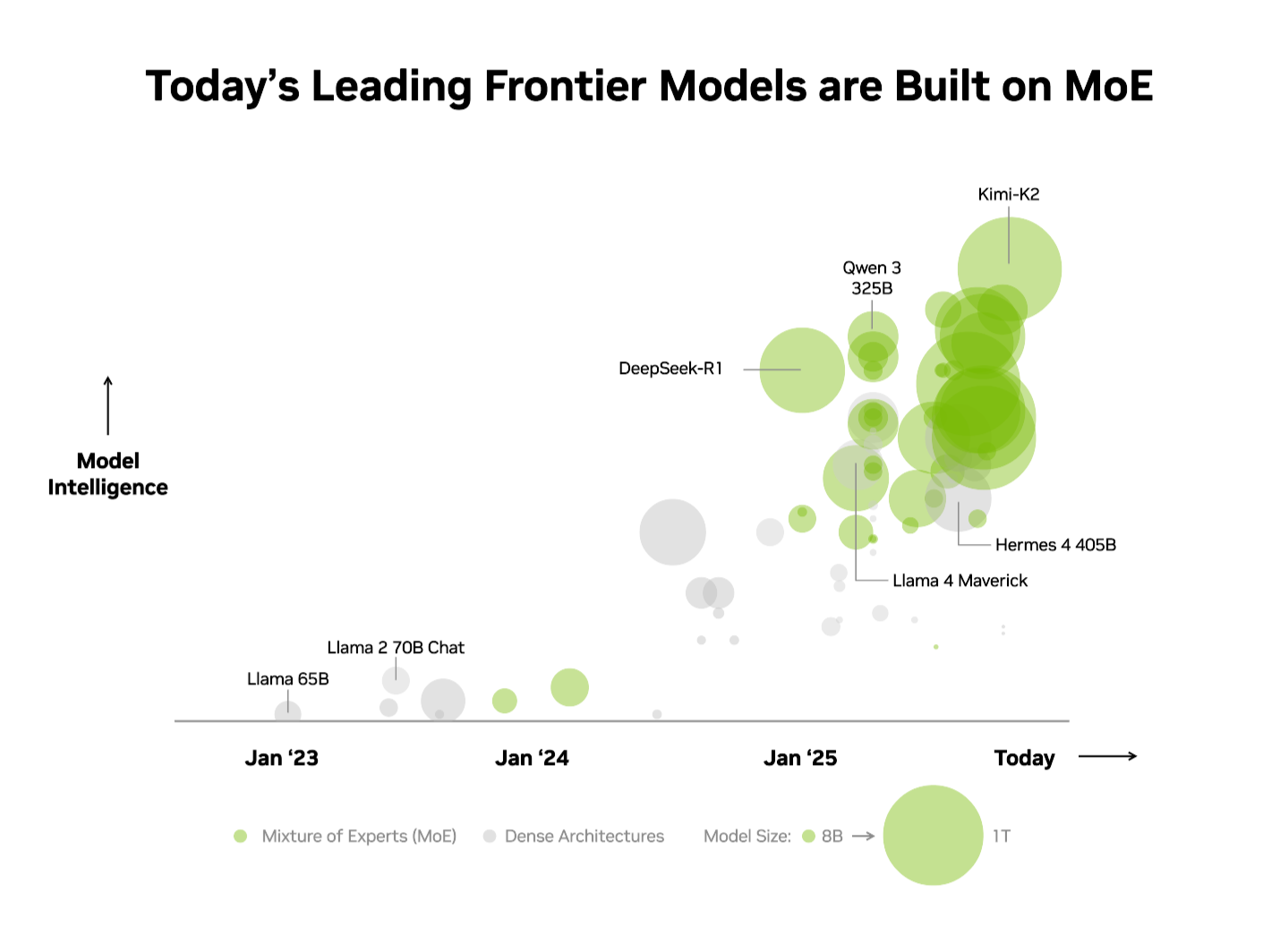
Неудивительно, что смесь экспертов стала выбором для передовых моделей: более 60% открытых релизов с начала года используют эту архитектуру, увеличив интеллект моделей почти в 70 раз с раннего 2023 года.
Источник: blogs.nvidia.com
С раннего 2025 года почти все ведущие модели применяют дизайн смеси экспертов.
«Наша пионерская работа с открытой архитектурой смеси экспертов, начатая с Mixtral 8x7B два года назад, делает продвинутый интеллект доступным и устойчивым для широкого спектра приложений,» — сказал Гийом Лампль, соучредитель и главный ученый Mistral AI. — «Архитектура смеси экспертов в Mistral Large 3 позволяет масштабировать системы ИИ до большего быстродействия и эффективности, резко снижая потребление энергии и вычислений.»
Преодоление узких мест масштабирования смеси экспертов с помощью экстремального кодзайна
Передовые модели смеси экспертов слишком велики для одного GPU, поэтому эксперты распределяют по нескольким устройствам — экспертный параллелизм. Но на платформах вроде H200 возникают проблемы: ограничения памяти, когда параметры экспертов загружаются динамично, и латентность при коммуникации между GPU. Решение — экстремальный кодзайн в NVIDIA GB200 NVL72: 72 GPU Blackwell объединены в единую систему с 1,4 экзафлопсами производительности ИИ и 30 ТБ общей памяти, соединенные NVLink с пропускной способностью 130 ТБ/с.
Это позволяет масштабировать экспертный параллелизм до 72 GPU, решая узкие места:
- Снижение числа экспертов на GPU: Распределение по 72 GPU уменьшает нагрузку на память каждого устройства, высвобождая место для большего числа одновременных пользователей и длинных входных последовательностей.
- Ускорение коммуникаций экспертов: Эксперты общаются мгновенно через NVLink, а переключатель NVLink берет на себя часть вычислений для объединения информации.
Другие оптимизации, такие как фреймворк NVIDIA Dynamo для распределенного обслуживания, формат NVFP4 для точности и эффективности, плюс открытые фреймворки вроде TensorRT-LLM, SGLang и vLLM, усиливают производительность. GB200 NVL72 развертывается через облачных провайдеров, включая Amazon Web Services, CoreWeave и Microsoft Azure.
Источник новости: NVIDIA.





Оставить комментарий