
Оглавление
The Decoder сообщает, что китайский технологический гигант Alibaba выпустил Qwen3-Omni — нативную мультимодальную модель искусственного интеллекта, способную обрабатывать текст, изображения, аудио и видео в реальном времени.
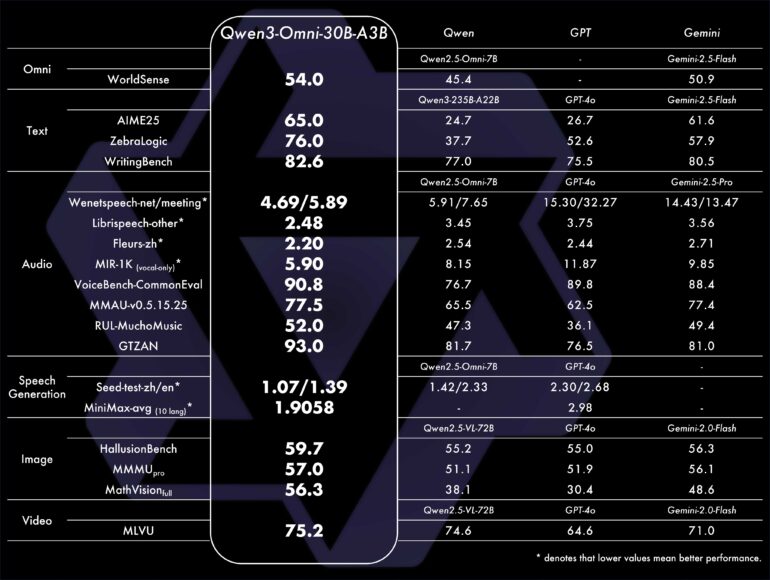
По заявлениям компании, модель демонстрирует лидирующие результаты на 32 из 36 аудио- и видео-бенчмарков, превосходя такие известные модели как Gemini 2.5 Flash и GPT-4o в задачах понимания речи и генерации голоса. В специализированных областях ее производительность соответствует моделям, созданным для работы с одним типом входных данных.
Архитектура с двумя компонентами
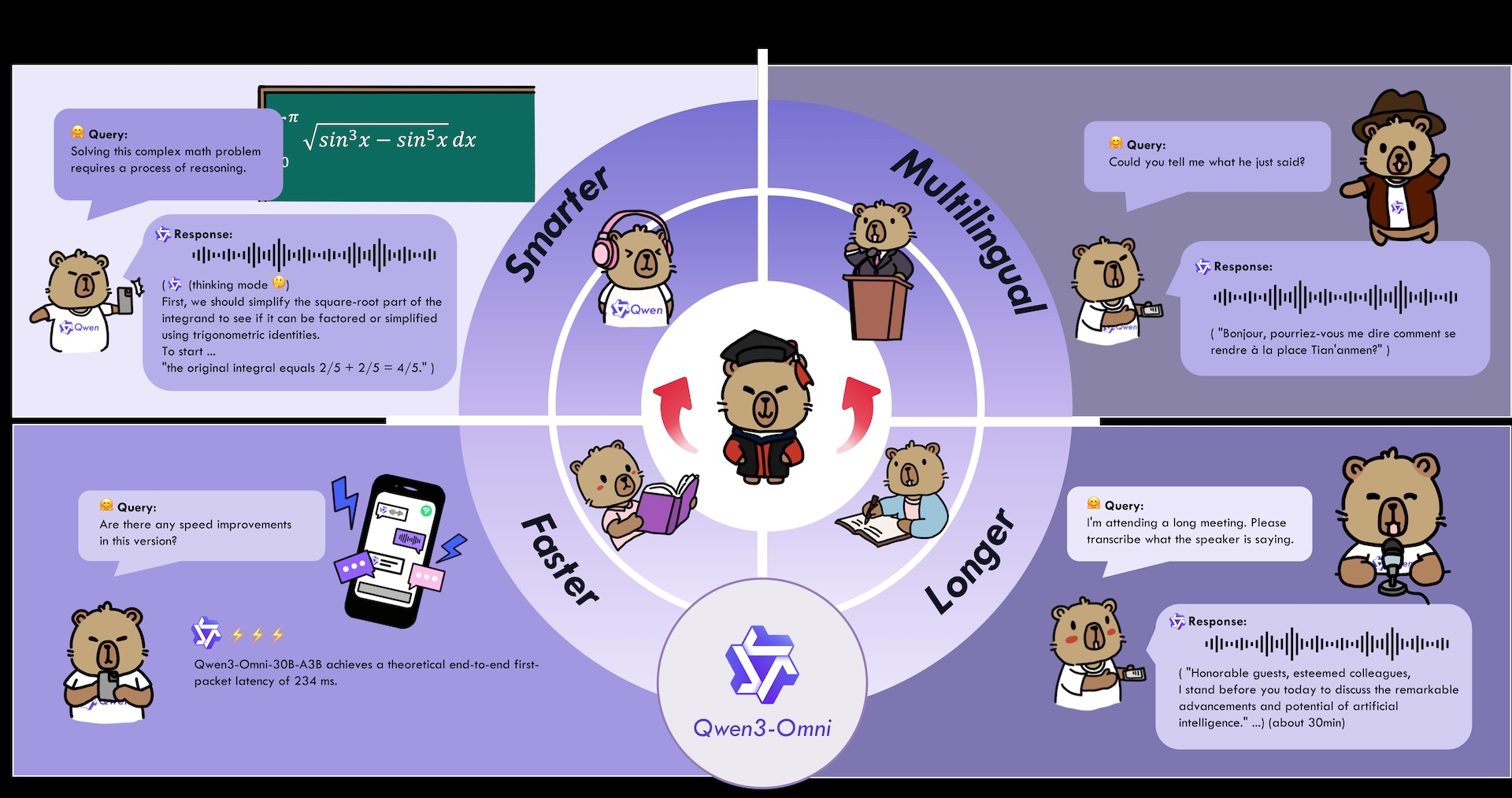
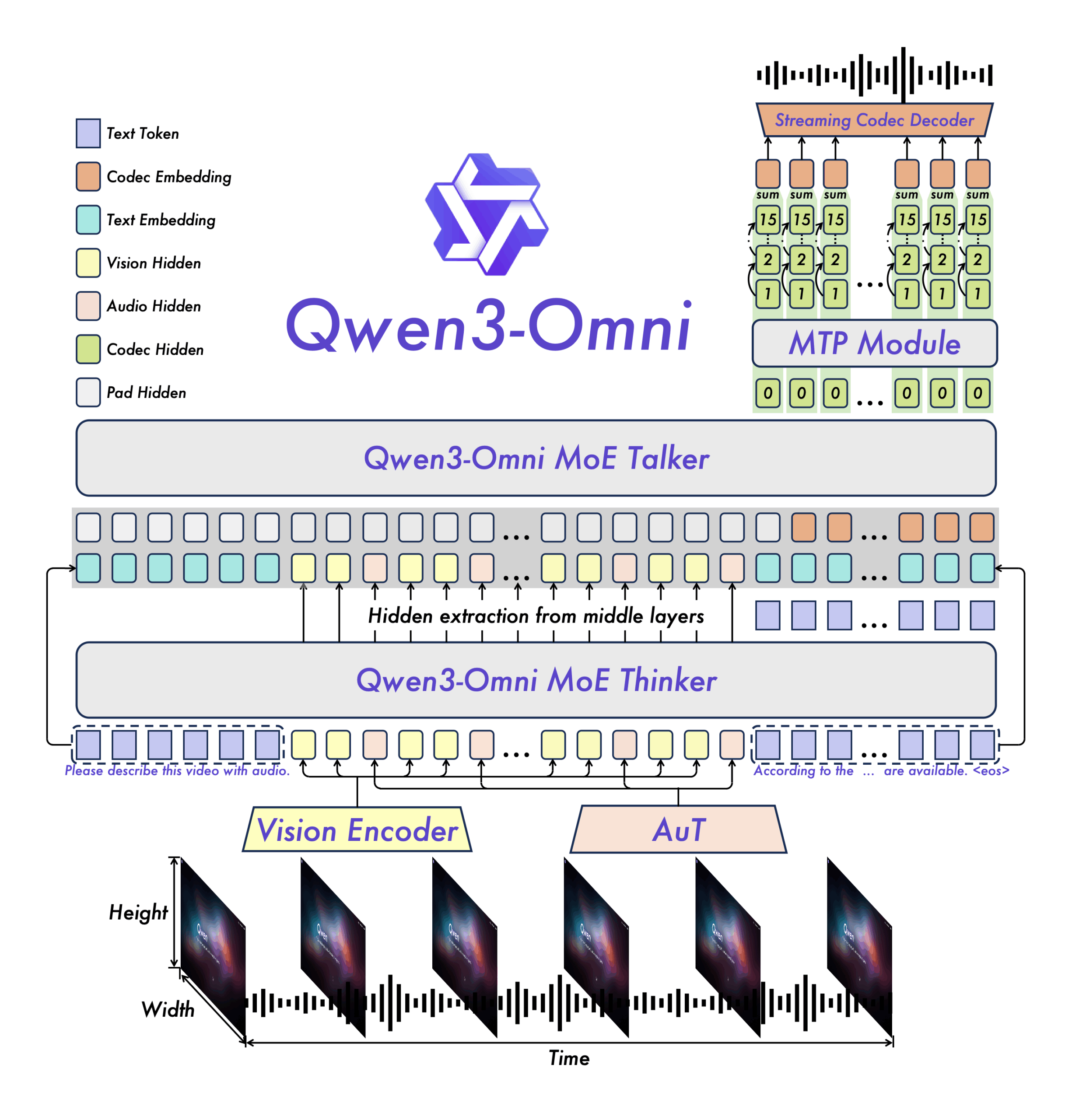
Qwen3-Omni использует двухкомпонентную систему: «Thinker» анализирует входные данные и генерирует текст, а «Talker» преобразует этот вывод непосредственно в речь. Оба компонента работают параллельно для минимизации задержек.
Для вывода в реальном времени модель генерирует аудио поэтапно вместо создания целых аудиофайлов сразу. Каждый шаг обработки немедленно преобразуется в слышимую речь, что позволяет осуществлять беспрерывную потоковую передачу. Аудиоэнкодер был обучен на 20 миллионах часов аудиоданных.
Технические характеристики
При отсутствии технического отчета, некоторые детали становятся известны из блог-постов и результатов бенчмарков. Модель с 30 миллиардами параметров использует архитектуру смешанных экспертов, активируя три миллиарда параметров на один вывод. Qwen3-Omni обрабатывает аудиовход за 211 миллисекунд, а комбинированные аудио- и видеоданные — за 507 миллисекунд.
Для 30-миллиардной модели такие показатели действительно впечатляют, но стоит помнить, что бенчмарки — это контролируемая среда. В реальных условиях компактные модели часто проигрывают более крупным конкурентам в стабильности и качестве ответов. Китайский гигант явно делает ставку на эффективность, но сможет ли Qwen3-Omni последовательно конкурировать с GPT-4o — вопрос открытый.
Языковая поддержка и возможности
Модель поддерживает обработку текста на 119 языках, понимание устной речи на 19 языках и может отвечать на 10 языках. Она способна анализировать и суммировать до 30 минут аудиозаписей.
Alibaba заявляет, что модель обучена одинаково хорошо работать со всеми поддерживаемыми типами входных данных без компромиссов в какой-либо области, даже при одновременной обработке нескольких модальностей.
Пользователи могут настраивать поведение модели с помощью специальных инструкций, изменяя стиль ответов или личность. Qwen3-Omni также может подключаться к внешним инструментам и сервисам для выполнения более сложных задач.
Отдельная модель для аудиоописаний
Alibaba также выпускает Qwen3-Omni-30B-A3B-Captioner — отдельную модель, созданную для детального анализа аудиоконтента, такого как музыка. Цель — генерация точных описаний с низким уровнем ошибок и заполнение пробела в экосистеме open-source.
Компания планирует улучшить распознавание нескольких говорящих, добавить распознавание текста для видео и усилить обучение на комбинациях аудио и видео. Также ведется работа над расширением возможностей автономных агентов.
Доступность и стратегия
Qwen3-Omni доступна через Qwen Chat и как демо на Hugging Face. Разработчики могут интегрировать модель в свои приложения с помощью API-платформы Alibaba. Также доступны две open-source версии: Qwen3-Omni-30B-A3B-Instruct для следования инструкциям и Qwen3-Omni-30B-A3B-Thinking для сложных рассуждений. С англоязычной рекламой Alibaba явно выходит за пределы Китая и нацеливается на пользователей в западных рынках.





Оставить комментарий