
Оглавление
Пока языковые модели бьют рекорды на академических тестах, их реальная полезность для профессионалов остается под большим вопросом. Новый бенчмарк PRBench от Scale демонстрирует тревожный разрыв между академическими показателями и практической применимостью ИИ в сложных профессиональных сценариях.
Что такое PRBench?
PRBench (Professional Reasoning Bench) — это серия специализированных тестов, созданных для оценки способности ИИ справляться с реальными профессиональными задачами. Первые два бенчмарка серии сосредоточены на финансах и юриспруденции.
В отличие от чисто академических тестов, PRBench присоединяется к важной тенденции оценки моделей на реальных практических навыках. Эта работа включает бенчмарки для фриланс-проектов (Remote Labor Index), разработки программного обеспечения (SWE-Bench Pro) и использования инструментов (MCP Atlas).
Масштабы исследования
Бенчмарки создавались командой из 182 экспертов в предметной области, включая профессионалов с юридическим образованием для права и специалистов с квалификацией CFA или 6+ годами опыта для финансов. Вопросы основаны на реальном опыте экспертов по использованию чат-ассистентов и типичных запросах от клиентов.
Датасет включает:
- 1100 реалистичных открытых задач
- Финансы: 600 образцов
- Право: 500 образцов
- Сложные подмножества самых трудных 300 финансовых и 250 юридических вопросов
- Смешанные типы пользователей: 74% экспертных вопросов в финансах и 53% в праве
- Охват 13 финансовых тем и 12 юридических тем
- Географический охват: 114 стран и зависимостей глобально, 47 юрисдикций США
- Многотуровые диалоги: около 30% всех бесед в датасете являются многоходовыми (до 10 ходов)
Реальная картина производительности
Результаты бенчмарка стали отрезвляющим душем для индустрии: хотя модели хорошо следуют инструкциям, они еще не являются экспертами и испытывают трудности со сложным профессиональным мышлением.
На полном датасете графики показывают четкую иерархию производительности, где топовые модели вроде GPT-5 Pro достигают показателей 0.51 в финансах и 0.50 в праве. Существенный разрыв отделяет верхний эшелон (GPT-5 Pro, GPT-5, o3) от большой конкурентной «середины», включающей модели вроде Claude 4.5 Sonnet, Kimi K2 Thinking и Gemini 2.5 Pro. Рейтинги моделей стабильны как в финансах, так и в праве.
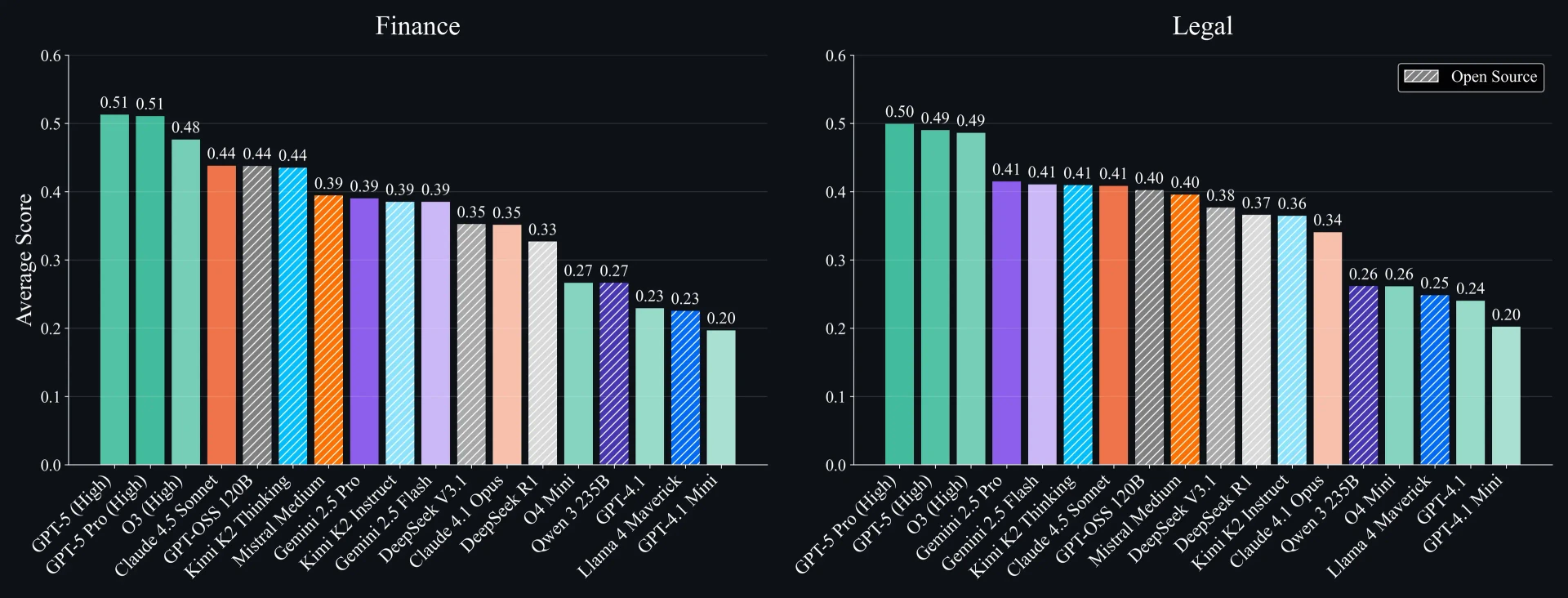
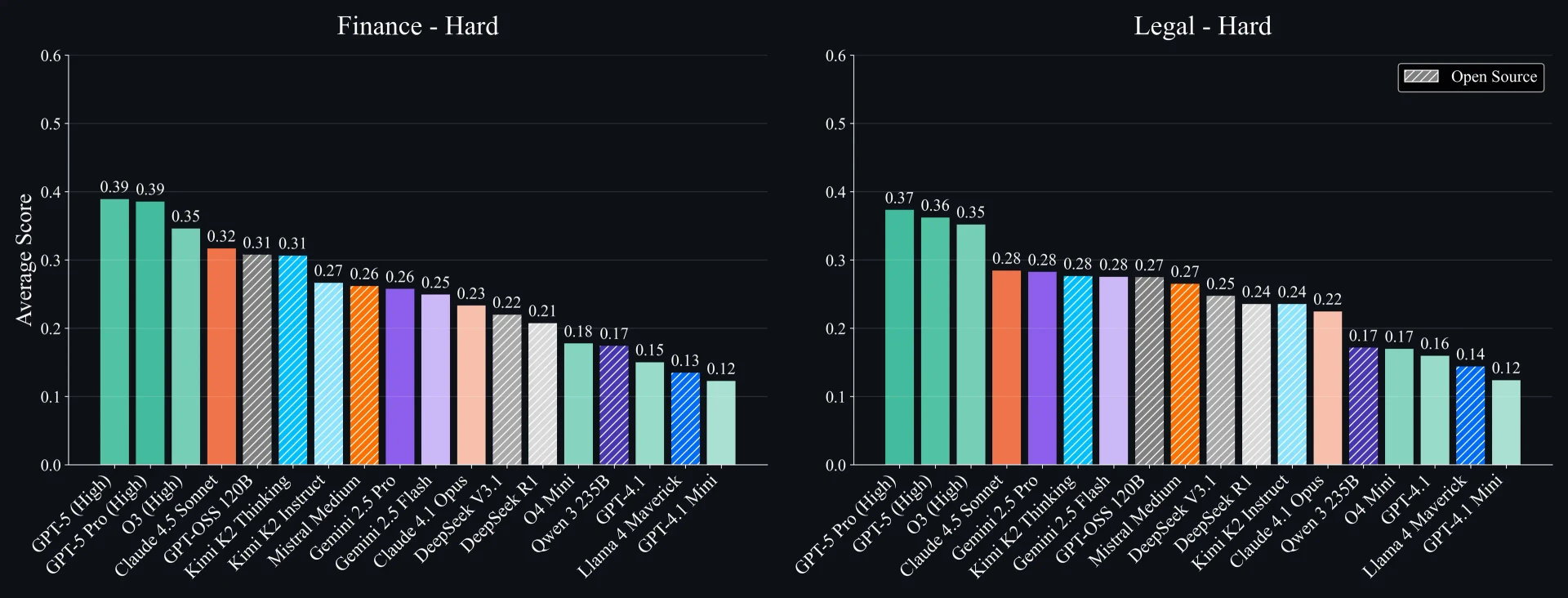
На сложных подмножествах производительность каждой модели значительно падает: максимальный результат в Finance-Hard снижается до 0.39, а в Legal-Hard — до 0.37. Хотя многие модели справляются со стандартными профессиональными запросами, они спотыкаются при столкновении с настоящей сложностью. Разрывы в производительности здесь усиливаются; например, в Legal-Hard поле сжимается, и несколько проприетарных и открытых моделей теснятся в диапазоне 0.25–0.28.
Основные проблемы ИИ
Исследование выявило четыре ключевые проблемы современных языковых моделей в профессиональных сценариях:
- Неточные суждения: Модели часто испытывают трудности с основным высокоуровневым мышлением, определяющим эти профессии
- Непрозрачное мышление: Даже при правильных выводах модели достигают их через неполные или непрозрачные процессы мышления
- Отсутствие добросовестности: Модели лучше справляются с выполнением инструкций, но продолжают испытывать трудности с предметно-специфической добросовестностью
- Инструменты не помогают: Предоставление моделям доступа к инструментам вроде веб-поиска или интерпретатора кода дало смешанные результаты
Хотя все модели исключительно сильны в «следовании инструкциям», они всеобъемлюще испытывают трудности с более тонким мышлением. Категории вроде «Дополнительной интуиции» и «Работы с неопределенностью» являются явными слабыми местами для всех пяти моделей как в финансах, так и в праве.
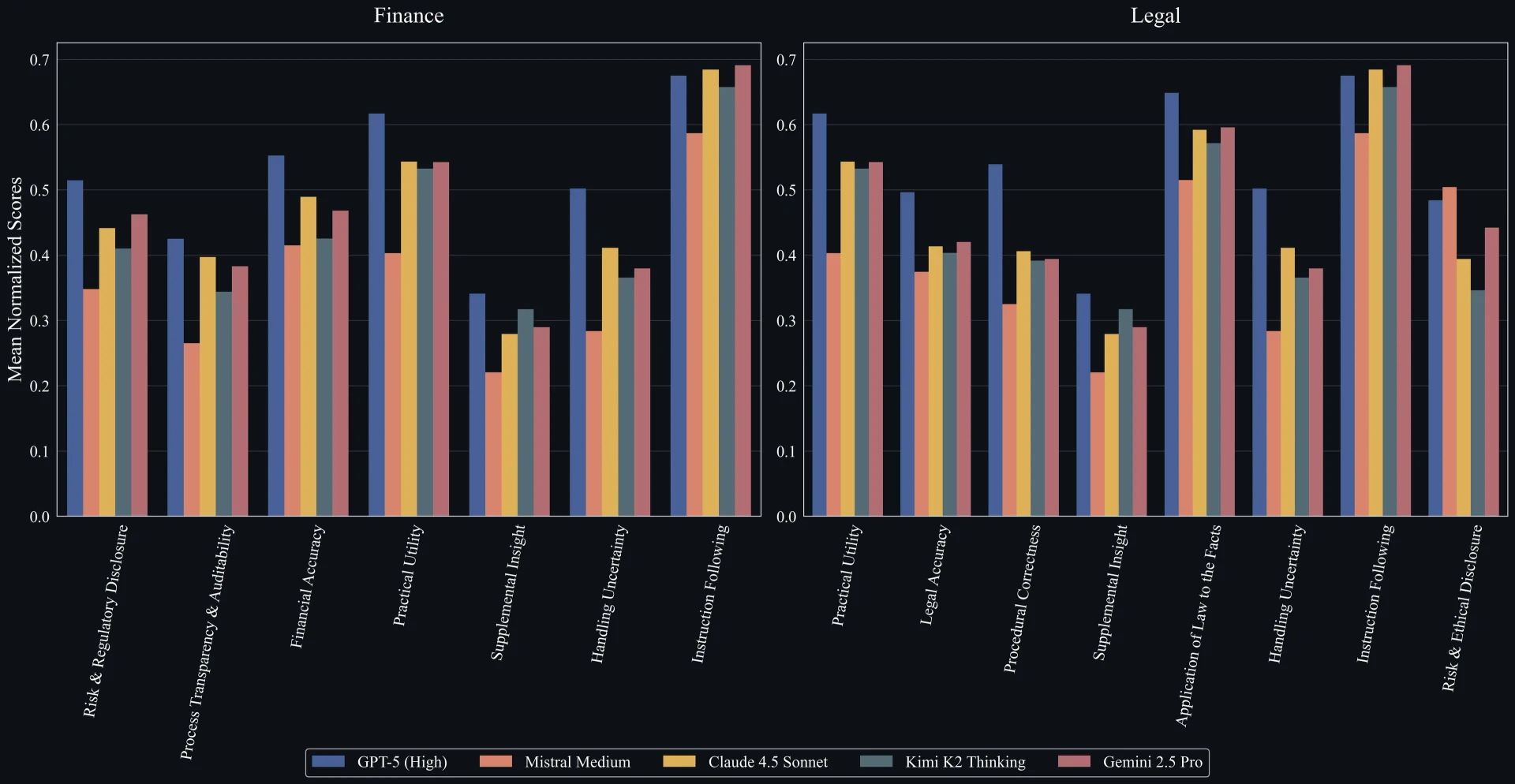
Поразительно наблюдать, как модели, демонстрирующие сверхчеловеческие способности на академических тестах, терпят крах на реальных профессиональных задачах. Это напоминает студента, который блестяще сдает экзамены по учебнику, но не может применить знания в реальной жизни. Особенно забавно, что дополнительные инструменты только усугубляют ситуацию — модели начинают «умничать» вместо того, чтобы решать задачу.
Выводы для индустрии
PRBench ясно демонстрирует, что передовые модели еще не готовы для серьезного применения в юриспруденции и финансах. Хотя модели отлично следуют инструкциям, им все еще не хватает критических предметных знаний, суждений и контекстуальной тонкости.
Для разработчиков эти бенчмарки предоставляют дорожную карту для исправления ситуации, двигаясь за пределы следования инструкциям к созданию инструментов, которым можно действительно доверять и которые можно проверять. Для корпоративных лидеров ясно, что модели общего назначения еще не подходят для критически важных экономически значимых решений.
Эта работа является частью более широких усилий по созданию бенчмарков, точно отражающих реальные сценарии использования, двигаясь за пределы академических оценок к преодолению разрыва между потенциалом ИИ и его действительно полезным, надежным и заслуживающим доверия применением для профессионалов.
По материалам Scale.





Оставить комментарий