Оглавление
Исследователи Google представили новый фреймворк для оценки языковых моделей в медицинской сфере, который решает ключевую проблему масштабируемости экспертной проверки. Метод использует адаптивные бинарные рубрики вместо традиционных шкал Лайкерта, что позволяет вдвое сократить время оценки при повышении точности.
Проблема традиционных методов оценки
Текущие практики оценки медицинских ИИ-систем в значительной степени опираются на человеческих экспертов, что делает процесс дорогостоящим, трудоемким и плохо масштабируемым. Задачи, требующие экспертного суждения, часто страдают от низкой согласованности между оценщиками и субъективных предубеждений.
Как отмечается в исследовательской работе, существующие методы не способны достаточно полно отражать тонкие различия в качестве ответов, особенно когда речь идет о персонализированных медицинских рекомендациях.

Адаптивные точные булевы рубрики
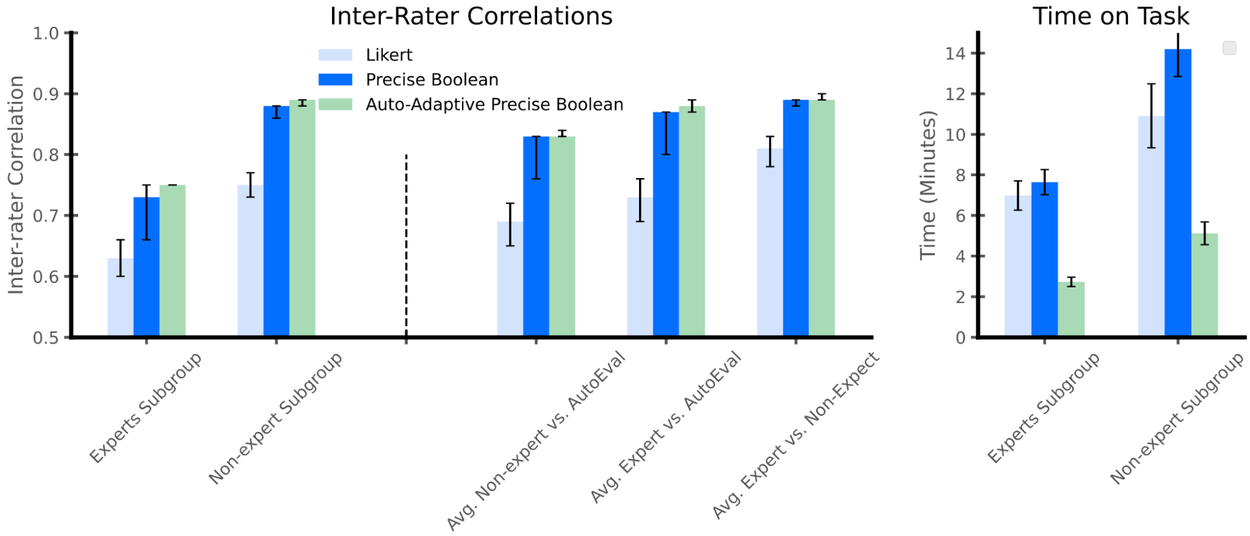
Новый подход Google преобразует сложные критерии оценки с открытыми ответами или многобалльными шкалами в детализированный набор бинарных критериев (Да/Нет). Этот метод, названный Точные булевы рубрики, существенно увеличивает согласованность оценок между экспертами.
Переход от субъективных шкал к бинарным критериям — это не просто техническое улучшение, а фундаментальное изменение парадигмы в оценке ИИ-систем. В медицинском контексте, где цена ошибки исключительно высока, такая точность становится критически важной.
Для дальнейшей оптимизации процесса исследователи разработали подход Адаптивные точные булевы рубрики, который динамически отфильтровывает обширный набор вопросов, оставляя только релевантные критерии для каждого конкретного случая. Это позволяет сократить количество необходимых оценок на 50% без потери качества.
Ключевые результаты
Валидация метода проводилась в области метаболического здоровья, включая диабет, сердечно-сосудистые заболевания и ожирение. Исследователи сравнили три подхода:
- Традиционные шкалы Лайкерта
- Точные булевы рубрики
- Адаптивные точные булевы рубрики
Результаты показали значительно более высокую межэкспертную согласованность при использовании бинарных рубрик по сравнению с традиционными методами. Коэффициенты внутриклассовой корреляции (ICC) демонстрировали существенное улучшение.
Автоматизация процесса
Для автоматической фильтрации релевантных критериев исследователи использовали Gemini в качестве классификатора без обучающих примеров. Модель анализировала пользовательский запрос, соответствующий ответ ИИ и конкретный критерий рубрики, определяя его релевантность.
Классификатор достиг средней точности 0.77 и F1-меры 0.83, что подтвердило возможность эффективной автоматизации процесса. Автоматически адаптируемые булевы рубрики показали эквивалентное улучшение ICC по сравнению с версиями, адаптированными людьми.
Автоматизированная система оценки, даже с неидеальной точностью классификации, способна улавливать ключевой оценочный сигнал. Это открывает возможности для массового тестирования медицинских ИИ-систем без привлечения огромных команд экспертов.
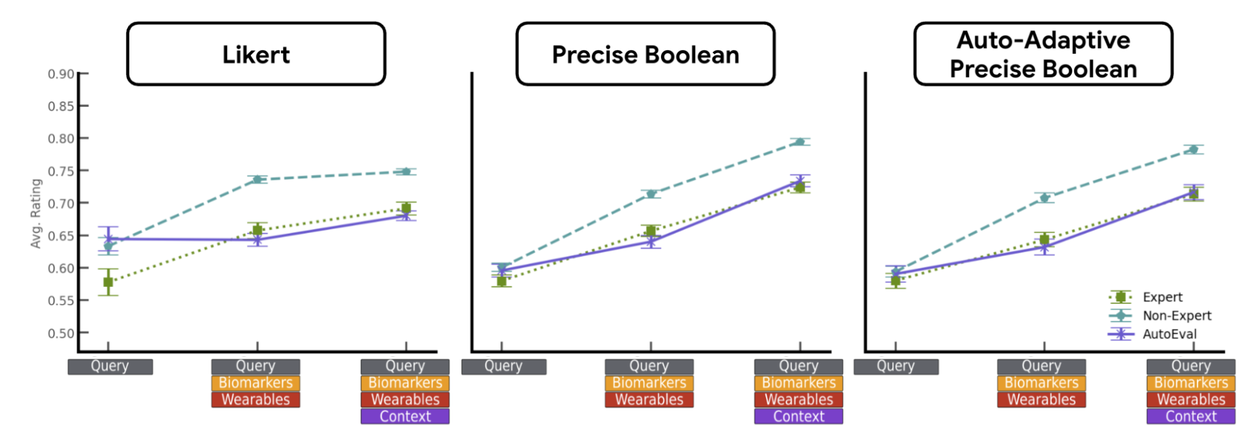
Метод также продемонстрировал более высокую чувствительность к изменениям в качестве ответов. В отличие от шкал Лайкерта, которые показывали ограниченную чувствительность к улучшениям входного контекста, бинарные рубрики чётко коррелировали с объемом предоставленных пользовательских данных.
По материалам Google Research





Оставить комментарий