
Amazon Web Services представила концепцию дашборда для анализа медицинских отчетов, который объединяет возможности языковых моделей через Amazon Bedrock, фреймворк LangChain для обработки документов и платформу Streamlit для создания пользовательского интерфейса.
Технологический стек решения
В основе системы лежат различные большие языковые модели, доступные через Amazon Bedrock, включая серию Anthropic Claude и Amazon Nova Foundation Models. Пользователи могут выбирать между моделями Claude Opus 4.1, Claude 3.7 Sonnet, Amazon Nova Pro и другими в зависимости от требований к производительности и точности.
Система обрабатывает медицинские отчеты, хранящиеся в Amazon S3, через цепочку обработки LangChain, которая управляет системой извлечения и поддерживает контекст разговора. Визуализации создаются с помощью Plotly и включают:
- Диаграммы сравнения нормальных и фактических значений
- Столбчатые диаграммы для сравнения параметров
- Графики трендов для отслеживания изменений во времени
Пользовательский интерфейс на Streamlit обеспечивает взаимодействие в реальном времени с ИИ-системой, управляя состоянием сессии и историей разговоров.
Архитектура решения
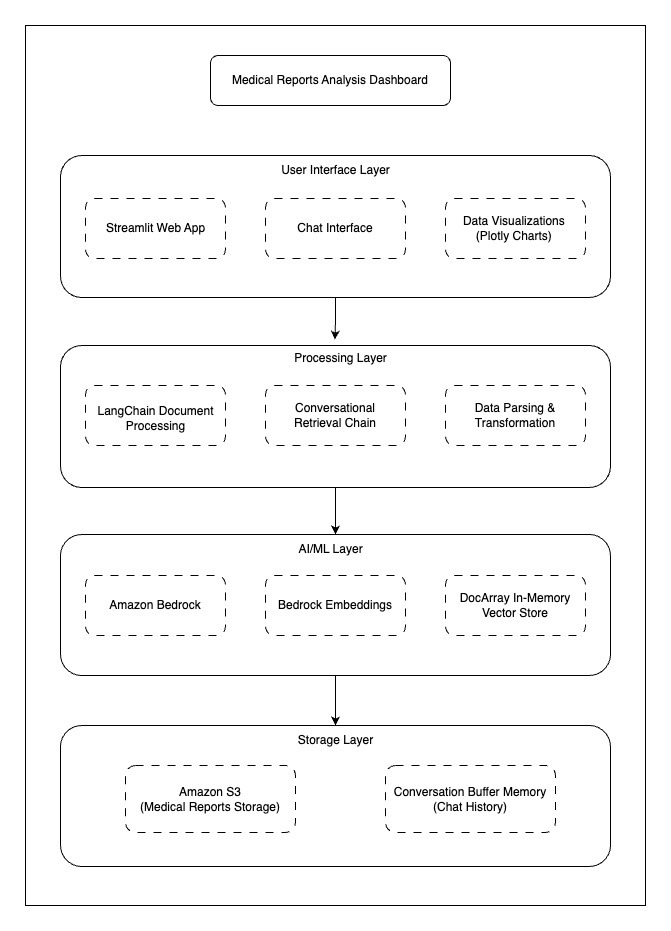
Архитектура системы состоит из четырех уровней:
- Уровень пользовательского интерфейса: Streamlit веб-приложение, чат-интерфейс, визуализации Plotly
- Уровень обработки: Обработка документов LangChain, цепочка извлечения разговоров, парсинг данных
- Уровень ИИ/ML: Amazon Bedrock, эмбеддинги Amazon Bedrock, векторное хранилище в памяти
- Уровень хранения: Amazon S3 для медицинских отчетов, буферная память разговоров
Предварительные требования
Для развертывания дашборда анализа медицинских отчетов необходимо:
- Аккаунт AWS с доступом к Amazon Bedrock
- Права IAM для Amazon Bedrock и Amazon S3
- Установленный и настроенный AWS CLI
- Бакет Amazon S3 для хранения медицинских отчетов в формате CSV
- Python 3.9 или новее с pip
- Доступ к моделям Amazon Bedrock
Интересно наблюдать, как облачные гиганты начинают осваивать нишу медицинской аналитики — область, где точность интерпретации данных буквально становится вопросом жизни и смерти. Технически решение выглядит грамотно собранным, но настоящий тест пройдет не в демо-режиме, а когда система столкнется с реальными медицинскими случаями, где каждая ошибка может иметь серьезные последствия. Особенно любопытно, как языковые модели справятся с медицинской терминологией на разных языках — ведь даже опытные врачи иногда ошибаются в интерпретации лабораторных данных.
По материалам AWS.





Оставить комментарий