
Оглавление
Эпоха закона Мура, диктовавшего прогресс классических процессоров, сменилась новой парадигмой — эрой параллельных вычислений. В этом контексте платформа NVIDIA с её GPU и архитектурой CUDA становится ключевым двигателем для трёх фундаментальных законов масштабирования искусственного интеллекта: предварительного обучения, посттренировки и вычислений во время инференса. Этот переход — не просто смена железа, а структурная революция в суперкомпьютинге и создании ИИ.
Исторический переворот: CPU уступают место GPU
На конференции SC25 основатель и CEO NVIDIA Дженсен Хуанг подчеркнул масштаб происходящих изменений. В подмножестве TOP100 списка TOP500, куда входят самые мощные суперкомпьютеры мира, более 85% систем теперь используют графические процессоры. Это знаменует исторический переход от последовательной обработки данных на CPU к массово-параллельным ускоренным архитектурам.
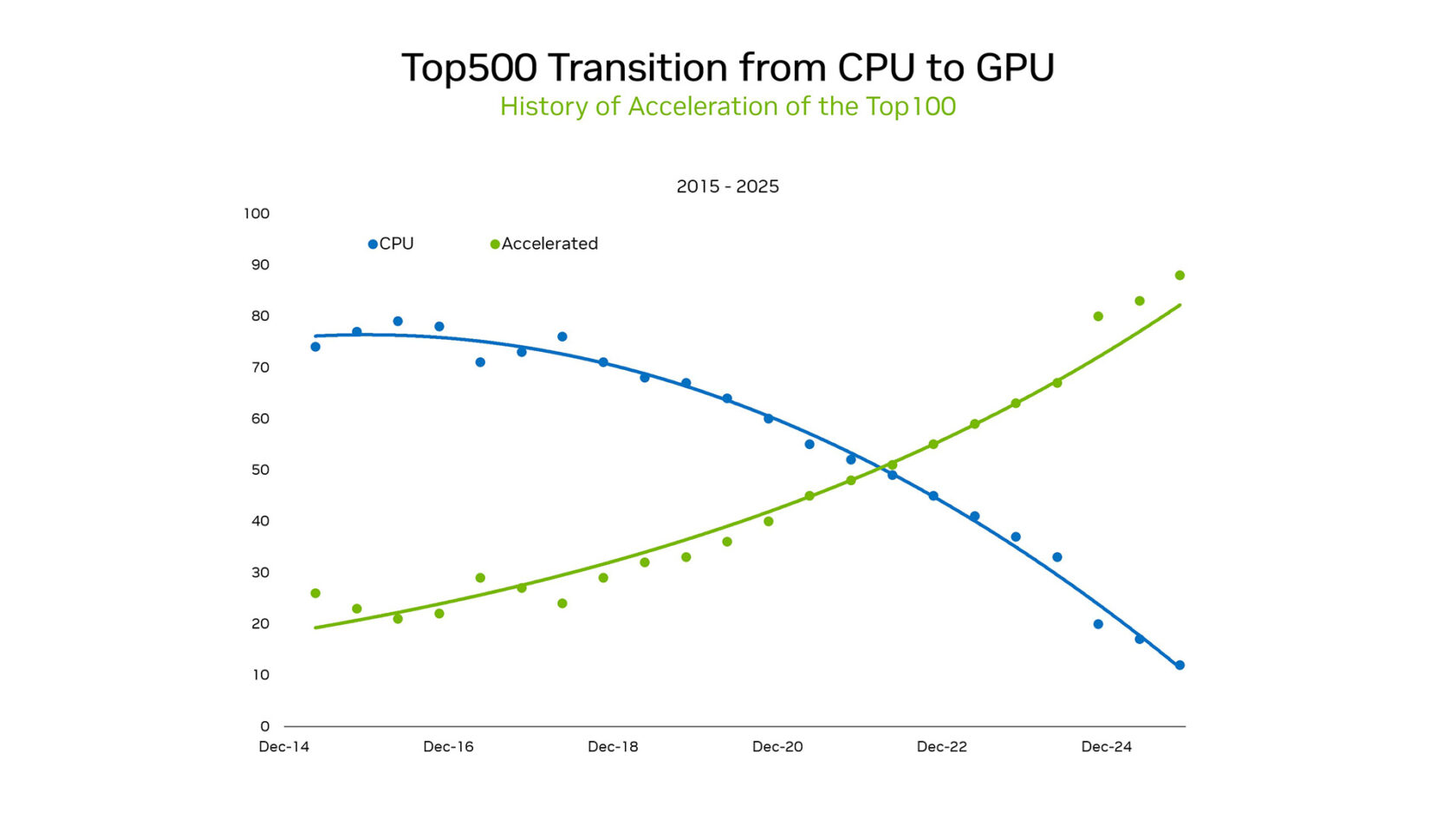
До 2012 года машинное обучение в основном опиралось на запрограммированную логику и статистические модели, эффективно работавшие на CPU. Всё изменила модель AlexNet, запущенная на игровых видеокартах, которая продемонстрировала, что классификацию изображений можно «обучать на примерах». Последствия для будущего ИИ были огромными: параллельная обработка всё возрастающих объёмов данных на GPU запустила новую волну вычислений.
Этот «переворот» касается не только аппаратного обеспечения. Речь идёт о платформах, открывающих новые возможности для науки. GPU обеспечивают значительно больше операций на ватт, делая экзафлопсные вычисления практичными без непомерных энергозатрат.
Переход с CPU на GPU часто преподносится как чисто аппаратная история, но настоящая магия происходит на уровне программного стека. Экосистема CUDA-X и открытые библиотеки — вот где скрывается реальное ускорение для разработчиков. История со Snowflake, интегрировавшей GPU A10 и библиотеки cuML/cuDF для ускорения ML-воркфлов без изменения кода, — идеальный пример того, как платформа NVIDIA становится стандартом де-факто не только для обучения моделей, но и для повседневной работы инженеров данных. Это стратегическое погружение в инфраструктуру компаний, которое создаёт почти монопольную экосистему — удобную для пользователя, но вызывающую вопросы о будущей конкуренции.
Три закона масштабирования ИИ
Смена процессорной парадигмы — не просто веха в суперкомпьютинге. Это фундамент для трёх законов масштабирования, которые определяют дорожную карту для следующего этапа развития ИИ.
1. Масштабирование предварительного обучения
Это был первый закон, осознанный индустрией. Исследователи обнаружили, что с ростом объёмов данных, количества параметров и вычислительных ресурсов производительность моделей улучшается предсказуемо. Удвоение данных или параметров означало скачок в точности и универсальности. На последних отраслевых бенчмарках MLPerf Training платформа NVIDIA показала наивысшую производительность во всех тестах и была единственной, представленной по всем дисциплинам. Без GPU эпоха «чем больше, тем лучше» в исследованиях ИИ застопорилась бы под грузом энергобюджетов и временных ограничений.
2. Масштабирование посттренировки
После создания базовой модели её необходимо доработать — настроить для конкретных индустрий, языков или требований безопасности. Такие техники, как обучение с подкреплением на основе обратной связи от людей, прунинг и дистилляция, требуют огромных дополнительных вычислений. В некоторых случаях эти затраты сопоставимы с предварительным обучением. Это похоже на то, как студент совершенствует знания после базового образования. GPU снова предоставляют необходимую мощность, обеспечивая постоянную тонкую настройку и адаптацию моделей в различных областях.
3. Масштабирование вычислений во время инференса
Этот новейший закон может оказаться самым трансформационным. Современные модели на архитектурах типа «смесь экспертов» могут рассуждать, планировать и оценивать несколько решений в реальном времени. Цепочки рассуждений, генеративный поиск и агентный ИИ требуют динамических, рекурсивных вычислений — часто превышающих требования предварительного обучения. Этот этап будет стимулировать экспоненциальный рост спроса на инфраструктуру для инференса — от дата-центров до периферийных устройств.
Вместе эти три закона объясняют растущий спрос на GPU для новых AI-нагрузок. Масштабирование предварительного обучения сделало GPU незаменимыми. Масштабирование посттренировки укрепило их роль в доработке моделей. Масштабирование вычислений во время инференса гарантирует, что GPU останутся критически важными ещё долго после завершения обучения. Это следующая глава в ускоренных вычислениях: жизненный цикл, в котором GPU питают каждый этап ИИ — от обучения и рассуждений до развёртывания.
Что дальше: генеративный, агентный и физический ИИ
Мир искусственного интеллекта расширяется далеко за пределы базовых рекомендательных систем, чат-ботов и генерации текста. VLM, или модели «язык-зрение», — это AI-системы, сочетающие компьютерное зрение и обработку естественного языка для понимания и интерпретации изображений и текста. А рекомендательные системы — движки персонализированных покупок, стриминга и социальных лент — лишь один из многих примеров того, как массовый переход от CPU к GPU меняет ландшафт ИИ.
По сообщению NVIDIA, ускоренные вычисления достигли переломного момента, и ИИ, трансформируя существующие приложения, открывает путь для совершенно новых.





Оставить комментарий