Оглавление
Создание многомашинных GPU-кластеров исторически было сложным и рутинным процессом — тикеты, согласования, ручная настройка отнимали драгоценное время инженеров и исследователей. Теперь Together Instant Clusters предлагают API-первый подход к развертыванию инфраструктуры для ИИ — от одиночных нод (8 GPU) до крупных кластеров с сотнями взаимосвязанных ускорителей с поддержкой NVIDIA Hopper и NVIDIA Blackwell.
Облачная эргономика для GPU-кластеров
Разработчики привыкли к API-первому, самообслуживаемому и предсказуемому облаку. Исторически GPU-кластеры таким не были — команды вручную собирали драйверы, планировщики и сетевую инфраструктуру. Together Instant Clusters автоматизируют процесс от запроса до запуска, обеспечивая консистентность в разных средах и масштабируемость без изменения рабочего процесса.
Самообслуживание за минуты
Развертывание через консоль, CLI или API с интеграцией Terraform и SkyPilot для Infrastructure as Code и мультиоблачных рабочих процессов. Выбор и фиксация версий NVIDIA driver/CUDA, собственные образы контейнеров, общее хранилище — все готово к работе за минуты.
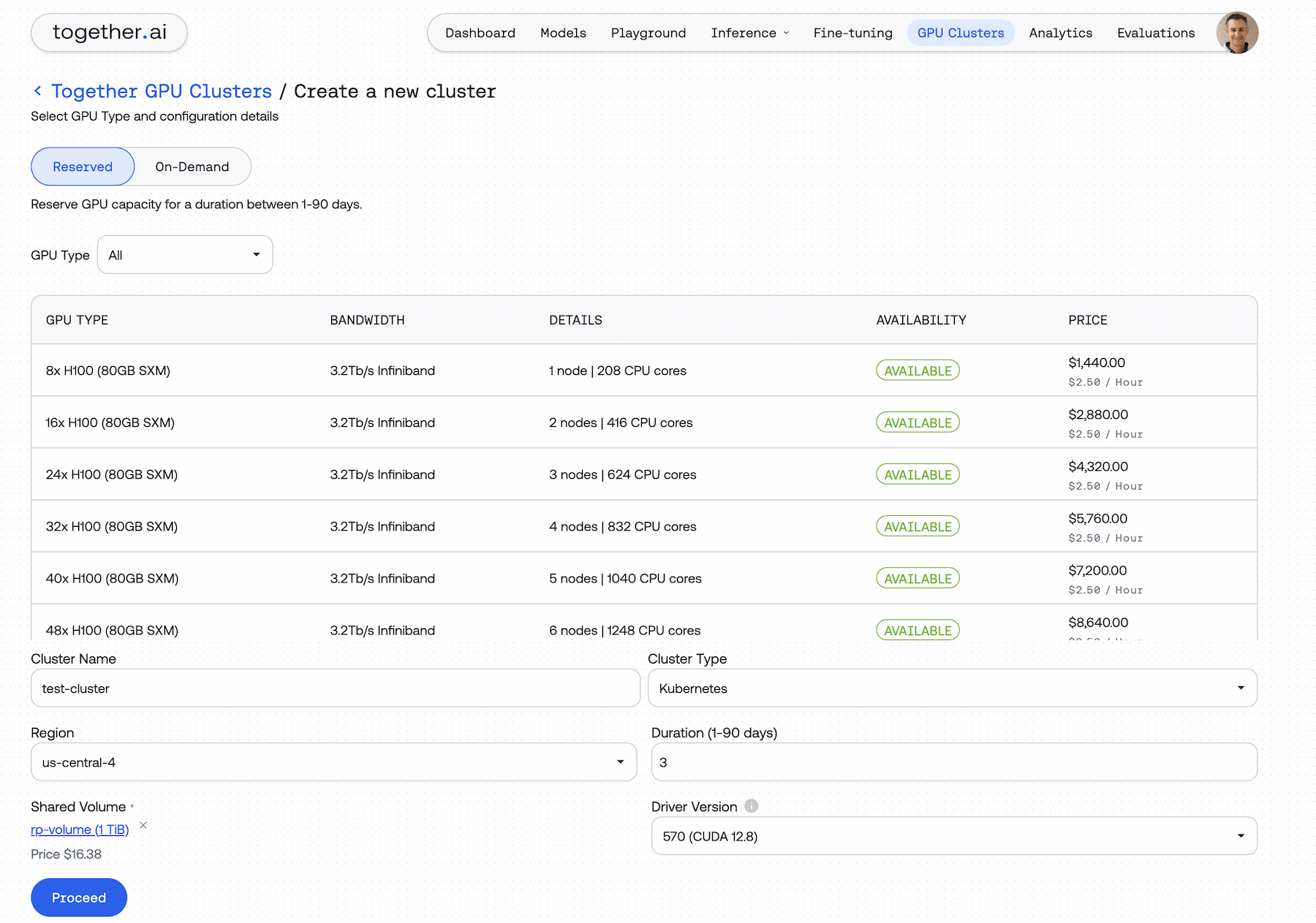
Все включено
Кластеры поставляются с предустановленными компонентами, которые обычно требуют дней ручной настройки:
- GPU Operator для управления драйверами и runtime
- Ingress controller для трафика
- NVIDIA Network Operator для высокопроизводительных сетей NVIDIA Quantum InfiniBand и NVIDIA Spectrum-X Ethernet
- Cert Manager для сертификатов и HTTPS endpoints
Оптимизация для распределенного обучения
Обучение в масштабе требует правильных межсоединений и оркестрации. Кластеры используют неблокирующий NVIDIA Quantum-2 InfiniBand между нодами и NVIDIA NVLink внутри нод, обеспечивая ультра-низкую задержку и высокую пропускную способность для многомашинного обучения.
Ирония в том, что пока исследователи пытаются ускорить обучение моделей на 5%, инфраструктурные задержки съедают 50% их времени. Сервисы вроде Instant Clusters — это не просто удобство, а фундаментальное изменение экономики исследований: когда кластер разворачивается за минуты вместо недель, можно делать в 10 раз больше экспериментов на тех же ресурсах.
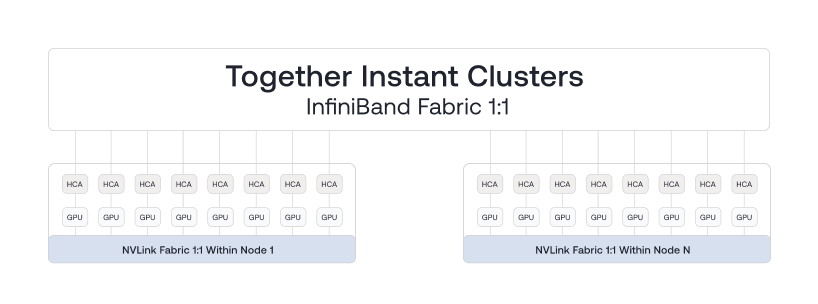
Масштабируемость для продакшн-инференса
При всплесках нагрузки сервисы должны масштабироваться, а не переархитектуриваться. Instant Clusters позволяют быстро добавлять мощности для инференса, сохраняя SLA по задержкам. Развертывание стека обслуживания на кластерах нужного размера, динамическое изменение мощностей под нагрузку — одна операционная модель от теста до продакшна.
Надежность в масштабе
Обучение на крупных GPU-кластерах не прощает слабых мест — плохой NIC, неправильный кабель или перегрев GPU могут остановить задачи или тихо ухудшить результаты. В общедоступной версии реализован полный режим надежности: каждая нода проходит тестирование на надежность и проверки NVLink/NVSwitch, межнодные соединения валидируются NCCL all-reduces, референсные прогоны подтверждают tokens/sec и Model FLOPs Utilization.
Ценообразование
Простое и прозрачное ценообразование без скрытых сборов. Выбор периода использования: почасово, 1-6 дней или 1 неделя-3 месяца. Цены в $/GPU-hour:
| Железо | 1 Неделя — 3 Месяца | 1 — 6 Дней | Почасово |
|---|---|---|---|
| NVIDIA HGX H100 Inference | $1.76 | $2.00 | $2.39 |
| NVIDIA HGX H100 SXM | $2.20 | $2.50 | $2.99 |
| NVIDIA HGX H200 | $3.15 | $3.45 | $3.79 |
| NVIDIA HGX B200 | $4.00 | $4.50 | $5.50 |
Хранилище и данные: общее хранилище — $0.16 за GiB-месяц, передача данных — бесплатный исходящий и входящий трафик.
По материалам Together.ai





Оставить комментарий