
Оглавление
Новая технология SuperOffload от команды DeepSpeed обещает революцию в обучении больших языковых моделей, позволяя эффективно проводить тонкую настройку моделей размером до 70 миллиардов параметров на единичных суперчипах NVIDIA GH200. Об этом сообщает PyTorch.
Ключевые преимущества технологии
SuperOffload демонстрирует впечатляющие результаты:
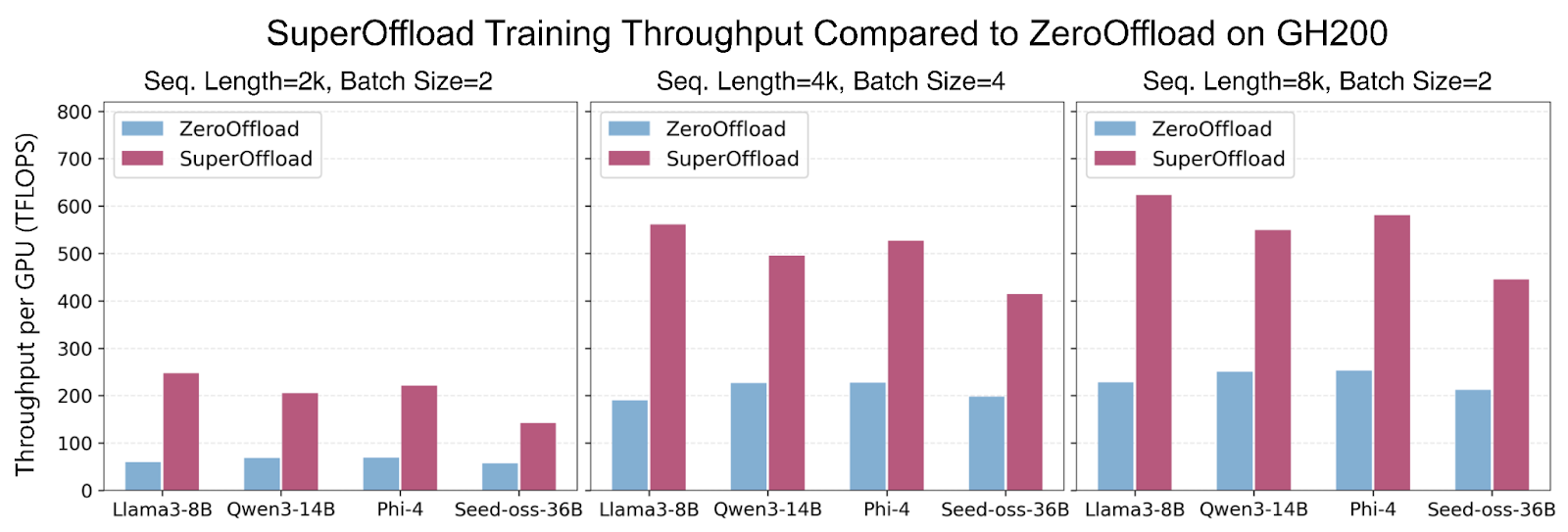
- Одиночный GH200: Полная тонкая настройка GPT-OSS-20B и Qwen3-14B с производительностью до 600 TFLOPS
- Мульти-GPU конфигурации: Qwen3-30B-A3B и Seed-OSS-36B на двух GH200; Llama-70B на четырех GH200
- Ускорение обучения: До 4 раз выше пропускной способности по сравнению с предыдущими решениями типа ZeRO-Offload
- Эффективность GPU: Увеличение утилизации графических процессоров с ~50% до более 80%
Проблема традиционных решений
Существующие методы оффлоудинга были разработаны для традиционных слабосвязанных архитектур и оказались неоптимальными для суперчипов. Они страдают от высоких накладных расходов и низкой утилизации GPU, поскольку не учитывают возможности высокоскоростных соединений типа NVLink-C2C с пропускной способностью 900 ГБ/с против 64 ГБ/с у PCIe-Gen4.
Технические инновации SuperOffload
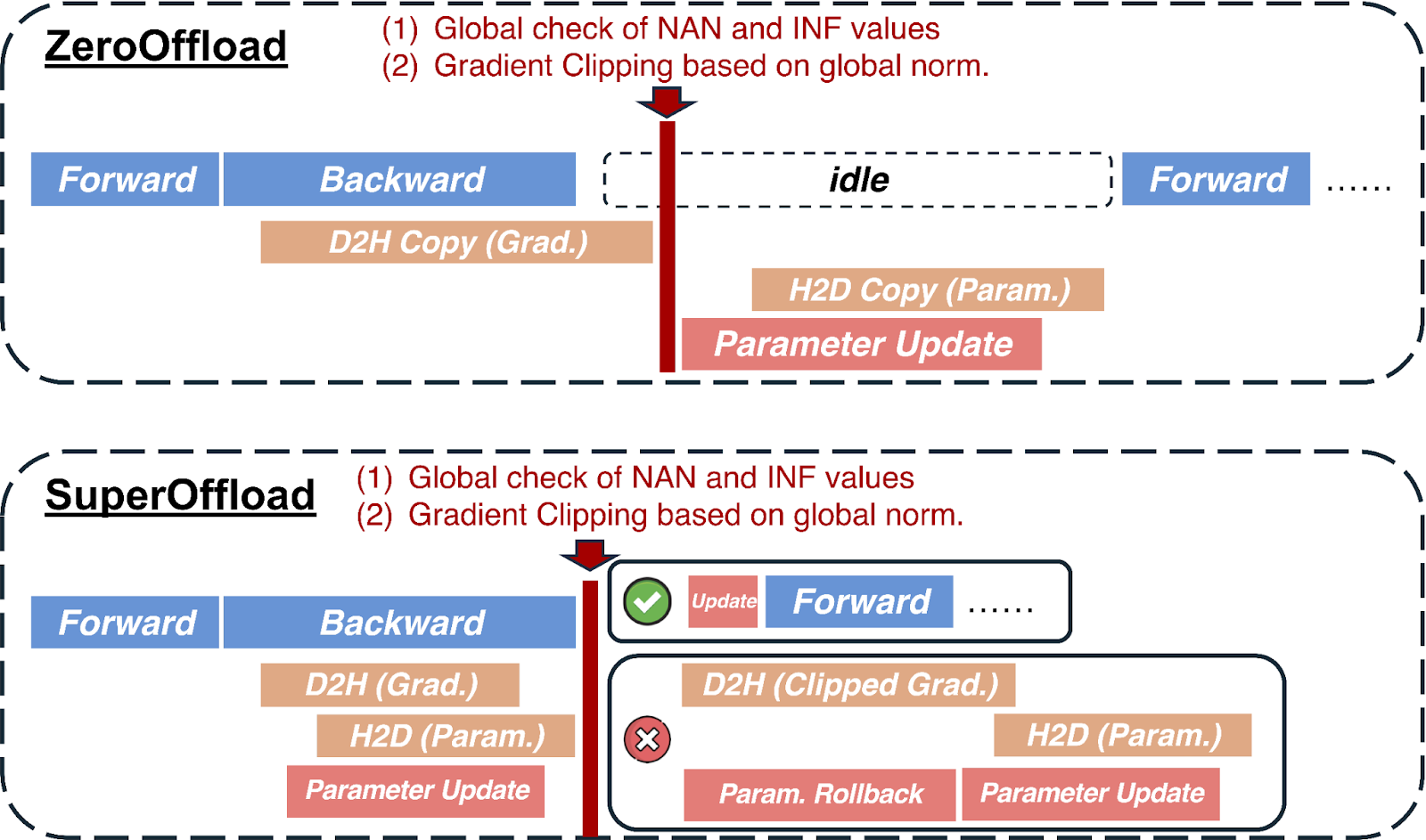
Speculation-then-Validation (STV)
Вместо синхронизации между CPU и GPU на этапе оптимизатора, STV позволяет выполнять спекулятивные вычисления оптимизатора на CPU параллельно с обратным распространением на GPU. Когда постобработка градиентов завершается, спекулятивные вычисления либо подтверждаются, либо отменяются, либо корректно переигрываются.
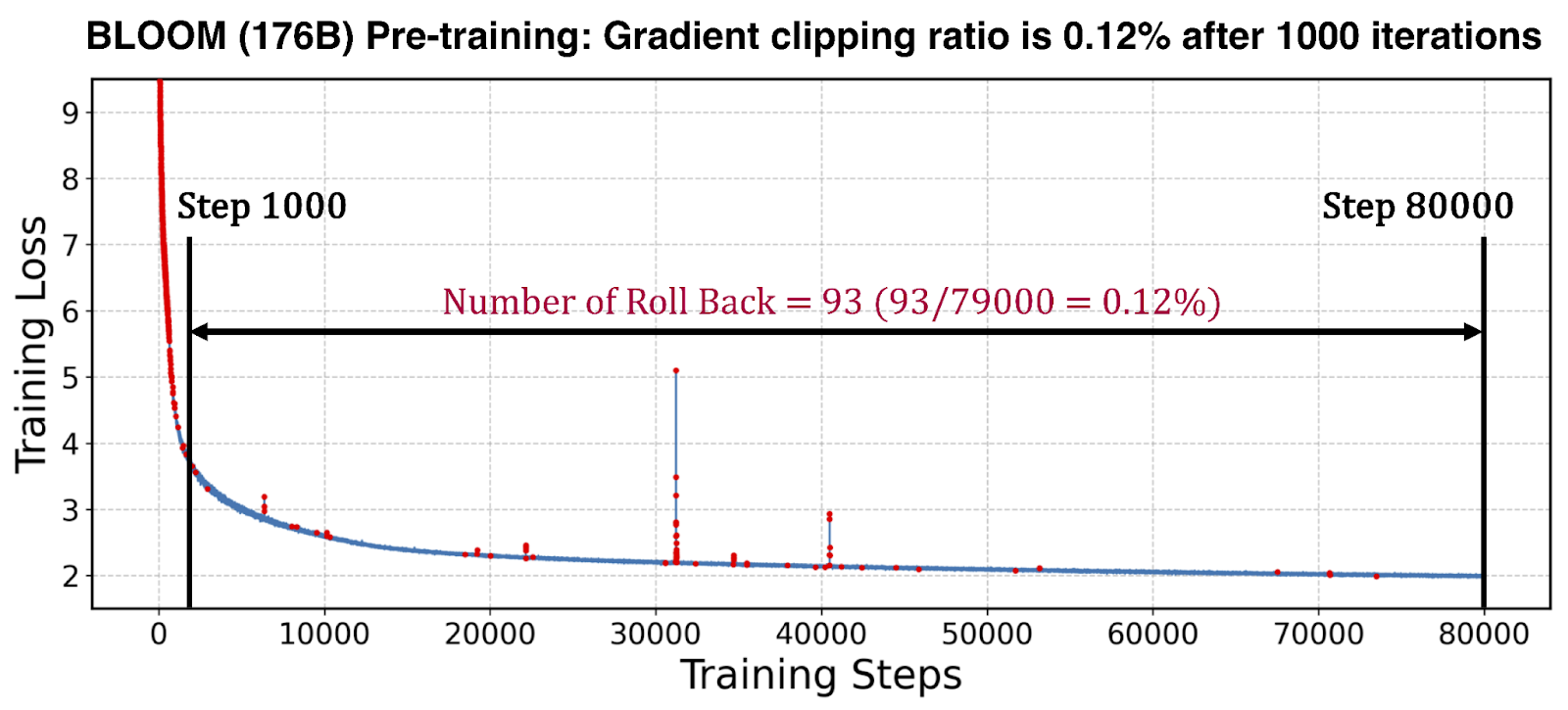
Исследования показали, что откаты из-за обрезки градиентов крайне редки после фазы разогрева, что делает накладные расходы STV пренебрежимо малыми.
Гетерогенные вычисления оптимизатора
SuperOffload распределяет вычисления оптимизатора между GPU и CPU: GPU обрабатывает градиенты, созданные на поздних этапах обратного распространения, а CPU — остальные. Это позволяет избежать простоя GPU и сокращает объем вычислений оптимизатора.
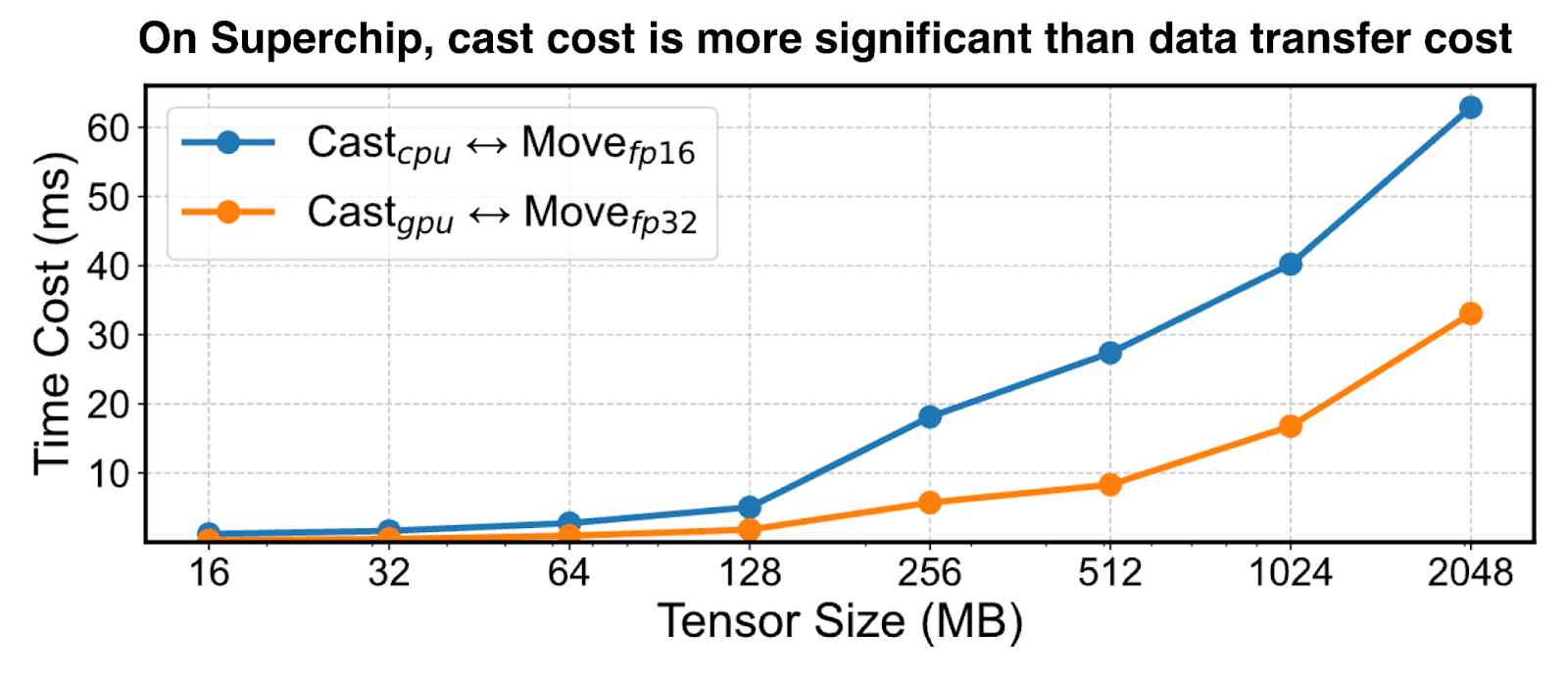
Superchip-Aware Casting
На суперчипах оптимальной стратегией оказалось приведение типов тензоров на GPU с последующей передачей в высокоточном формате, что противоречит подходам для традиционных архитектур с медленными соединениями.
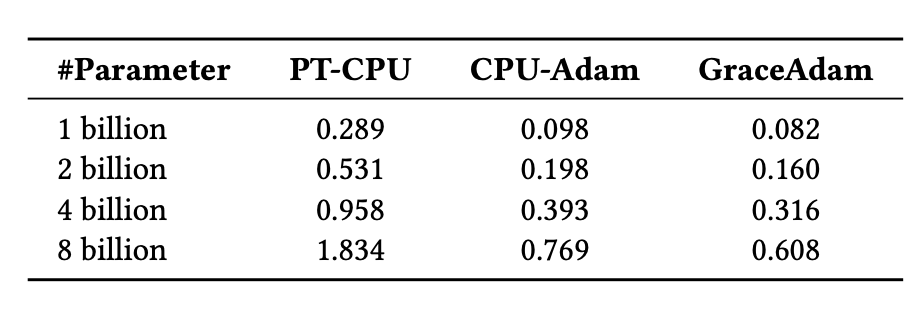
GraceAdam для процессоров Grace
Разработан специальный оптимизатор Adam для архитектуры Grace CPU, использующий возможности ARM Scalable Vector Extension (SVE) и управления иерархией памяти. GraceAdam в 3 раза быстрее PyTorch Adam и в 1.3 раза быстрее CPU-Adam.
Технически впечатляющая работа, но возникает вопрос: насколько это доступно для реальных команд? GH200 — оборудование премиум-класса, и хотя эффективность выросла, входной билет остаётся высоким. Интересно, как эти оптимизации масштабируются на более доступные конфигурации и будут ли они доступны в облачных сервисах по разумным ценам. Пока что это инструмент для избранных, но направление верное — выжимать максимум из имеющегося железа.
Практические рекомендации
Для максимальной эффективности разработчикам рекомендуется:
- Использовать привязку NUMA для сопряжения каждого GPU с непосредственно связанным CPU
- Применять MPAM (Memory System Resource Partitioning and Monitoring) для снижения интерференции между CPU и GPU
SuperOffload доступен в DeepSpeed версии 0.18.0 и выше, совместим с Hugging Face Transformers и не требует изменений в коде моделей.





Оставить комментарий