
Исследователи из Стэнфорда представили решение ThunderKittens для создания эффективных многопроцессорных AI-ядер, которые превосходят существующие решения на современном сетевом оборудовании GPU, сообщает HazyResearch.
Новая эра GPU-сетей
Современные тенденции в развитии GPU-сетей открывают захватывающие перспективы для повышения эффективности искусственного интеллекта. Появление NVSwitch четвертого поколения с поддержкой вычислений внутри сети, асинхронные сетевые передачи через Tensor Memory Accelerator и переход от масштабирования наружу к масштабированию вверх создают фундамент для новых архитектурных решений.
Ключевые наблюдения
Команда выделила несколько важных принципов для создания эффективных многопроцессорных ядер:
- Механизмы передачи данных: Существуют различные способы инициирования GPU-сетей с разной стоимостью выполнения
- Стратегии планирования: Коммуникацию и вычисления можно перекрывать на разных уровнях — host-device, меж-SM или внутри-SM
- Низкая производительность стандартных библиотек: Готовые коммуникационные библиотеки (NCCL, NVSHMEM) медленно адаптируются к новым аппаратным возможностям
- Принцип тайлов: Сетевая коммуникация на уровне тайлов не только насыщает пропускную способность сети, но и сохраняет удобные абстракции ThunderKittens
Стандартные коммуникационные библиотеки оказались на удивление медленными в адаптации к новым аппаратным функциям. Оказывается, базовые коммуникационные ядра, написанные практически с нуля (менее 10 строк кода), легко обгоняют промышленные решения — это говорит о том, что индустрия сильно недооценивает простые оптимизации в пользу сложных абстракций.
Достигнутые результаты
Обновленный ThunderKittens уже демонстрирует впечатляющие результаты, соответствуя или превосходя современные реализации в различных параллельных стратегиях.
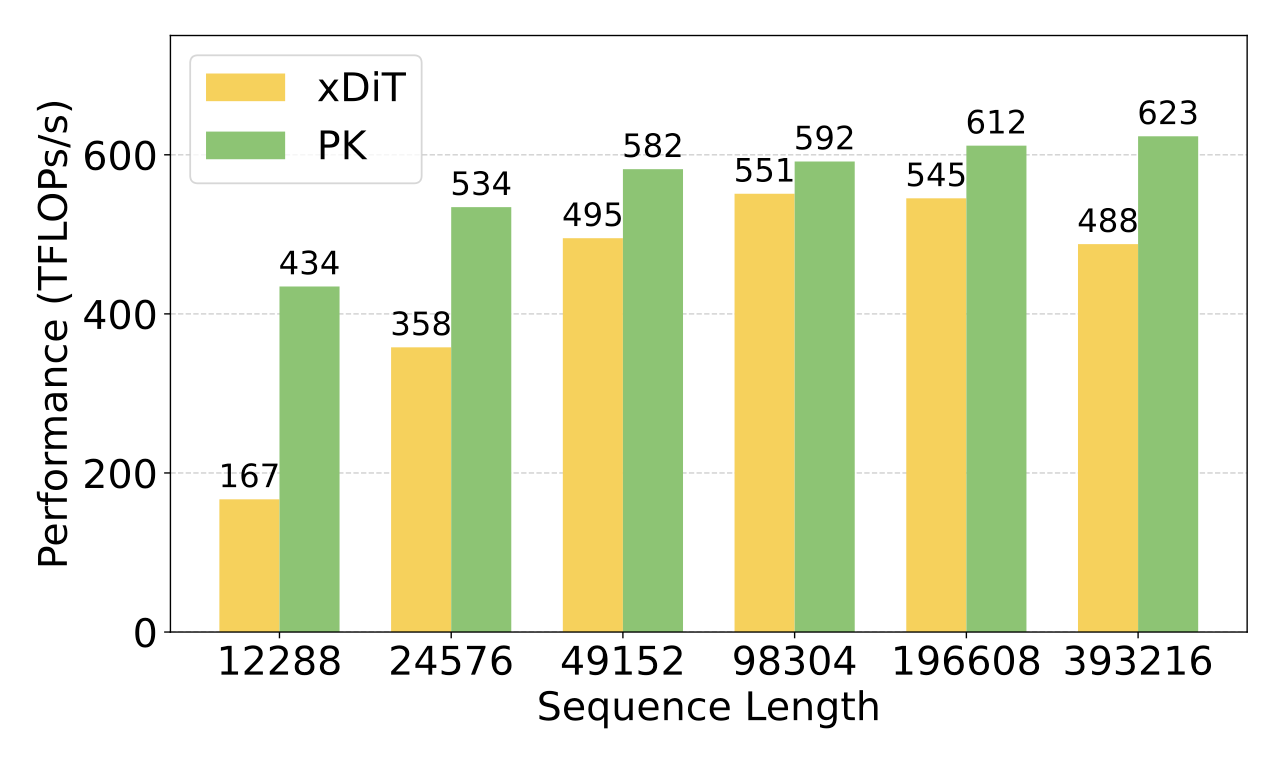
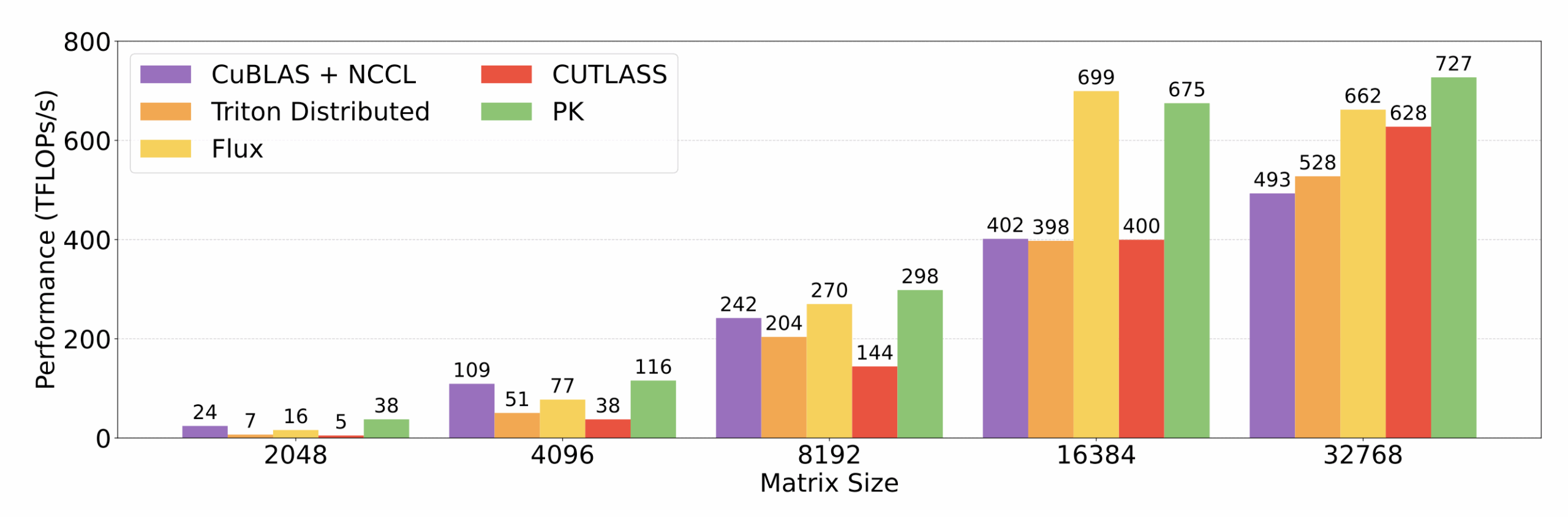
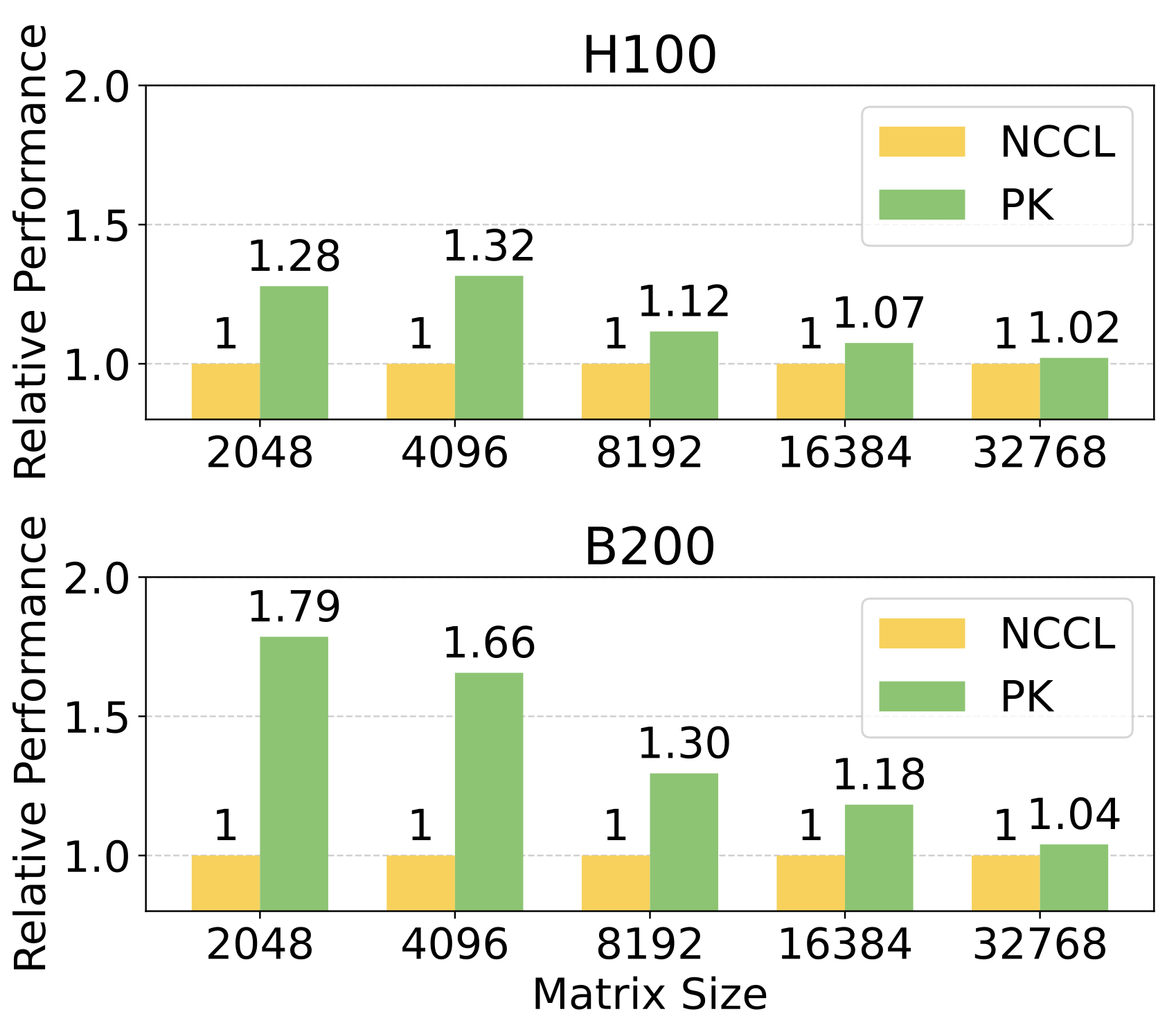
На графиках видно, что решение показывает отличную производительность BF16 all-reduce sum на 8xH100 и 8xB200, а также в операциях all-gather + GEMM и Ring Attention.
Будущие направления
Исследователи планируют добавить поддержку межузловой коммуникации, улучшить документацию и реализовать более сложные приложения, такие как балансировка нагрузки для Mixture of Experts. Текущие API и ядра уже стабильны и готовы для использования сообществом.
Интересно, что AMD также добавляет аппаратные функции, аналогичные TMA (под названием «TDM»), что указывает на общую тенденцию развития GPU-архитектур в сторону более интеллектуальных сетевых возможностей.





Оставить комментарий