
Оглавление
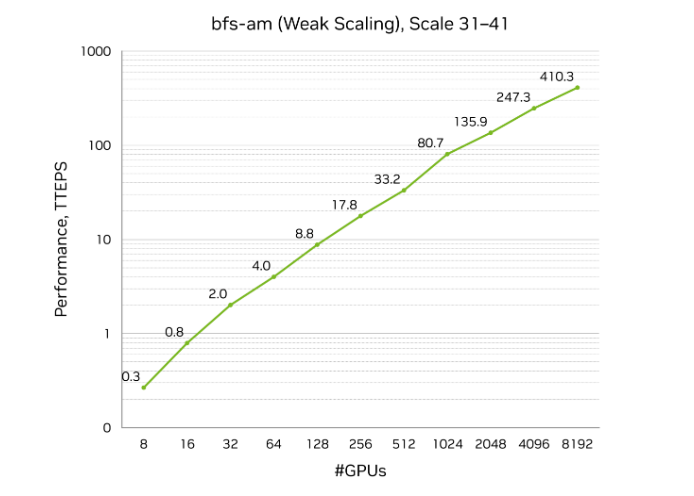
Система на базе коммерчески доступного кластера NVIDIA H100 установила новый рекорд в обработке графов масштаба триллионов ребер, в два раза превзойдя ближайших конкурентов. Результат в 410 триллионов TEPS был достигнут на кластере из 8192 графических процессоров, размещенном в дата-центре CoreWeave в Далласе.
Масштаб и значение рекорда
Тест Graph500 breadth-first search (BFS) — это отраслевой эталон, измеряющий способность системы эффективно работать с разреженными, нерегулярными структурами данных, такими как графы социальных сетей или финансовых транзакций. Кластер NVIDIA обработал граф с 2.2 триллиона вершин и 35 триллионов ребер. Для понимания масштаба: если бы каждому из 8 миллиардов жителей Земли соответствовало 150 друзей, то все эти связи можно было бы проанализировать примерно за три миллисекунды.
Ключевым достижением стала не только скорость, но и эффективность. Решение NVIDIA, занявшее первое место в списке Graph500, использовало чуть более 1000 узлов, в то время как другие решения из топ-10 потребовали около 9000 узлов. По данным NVIDIA, это обеспечило втрое лучшую производительность на доллар затрат.
Этот рекорд — не просто демонстрация грубой силы. Он сигнализирует о смене парадигмы: традиционно «неудобные» для GPU разреженные и нерегулярные задачи теперь могут масштабироваться на графических ускорителях с огромным преимуществом в эффективности. NVIDIA методично перетягивает одеяло с CPU на GPU, и Graph500 — лишь один из фронтов. Интересно наблюдать, как компания, построившая империю на AI-тренировках, теперь с таким же напором берется за классические HPC-задачи, доказывая универсальность своей архитектуры.
Технологический прорыв: от CPU к GPU
До недавнего времени обработка гигантских графов оставалась прерогативой CPU-архитектур. Основная проблема при масштабировании до триллионов ребер — узкое место в коммуникациях между узлами. Традиционный подход с постоянным перемещением данных создает заторы.
Команда NVIDIA переосмыслила этот процесс, создав полный стек решений для GPU. Вместо того чтобы использовать CPU для обработки сообщений, они разработали программный фреймворк, позволяющий выполнять active messaging напрямую между GPU. Это стало возможным благодаря технологиям InfiniBand GPUDirect Async (IBGDA) и NVSHMEM.
Новый подход позволяет:
- Исключить CPU из цепочки обработки сообщений.
- Задействовать массивный параллелизм и пропускную способность памяти GPU H100.
- Одновременно отправлять сотни тысяч потоков активных сообщений с GPU, против всего сотен потоков на CPU.
Именно это перепроектирование позволило удвоить производительность при использовании лишь доли аппаратных ресурсов конкурентов.
Последствия для высокопроизводительных вычислений
Успех NVIDIA на Graph500 имеет значение далеко за пределами одного теста. Он открывает путь к ускорению широкого спектра HPC-задач, которые оперируют разреженными структурами данных:
- Научное моделирование: гидродинамика, прогнозирование погоды.
- Анализ данных: кибербезопасность, обнаружение мошенничества, рекомендательные системы.
- Социальные сети и финтех: анализ графов взаимоотношений и транзакций.
До сих пор эти области на самых больших масштабах были привязаны к CPU. Результат NVIDIA показывает, что коммерчески доступная инфраструктура на базе GPU может обеспечить суперкомпьютерную производительность для таких рабочих нагрузок.
Источник: www.blogs.nvidia.com
Это демонстрирует, как платформа NVIDIA готова демократизировать доступ к ускорению крупнейших разреженных и нерегулярных рабочих нагрузок, дополняя свои успехи в плотных вычислениях, таких как обучение ИИ. Другими словами, железо, которое сегодня доминирует в AI-тренировках, завтра может с тем же успехом обрабатывать триллионы связей в социальных сетях или моделировать климатические системы.
Источник новости: NVIDIA Blog





Оставить комментарий