
Оглавление
Платформа NVIDIA Dynamo позволяет предприятиям масштабировать вывод сложных AI-моделей на десятки серверов, обеспечивая рекордную производительность в облачных средах. Технология уже интегрирована со всеми крупными облачными провайдерами и демонстрирует до 2-кратного ускорения обработки без дополнительных аппаратных затрат.
Революция в распределенном выводе
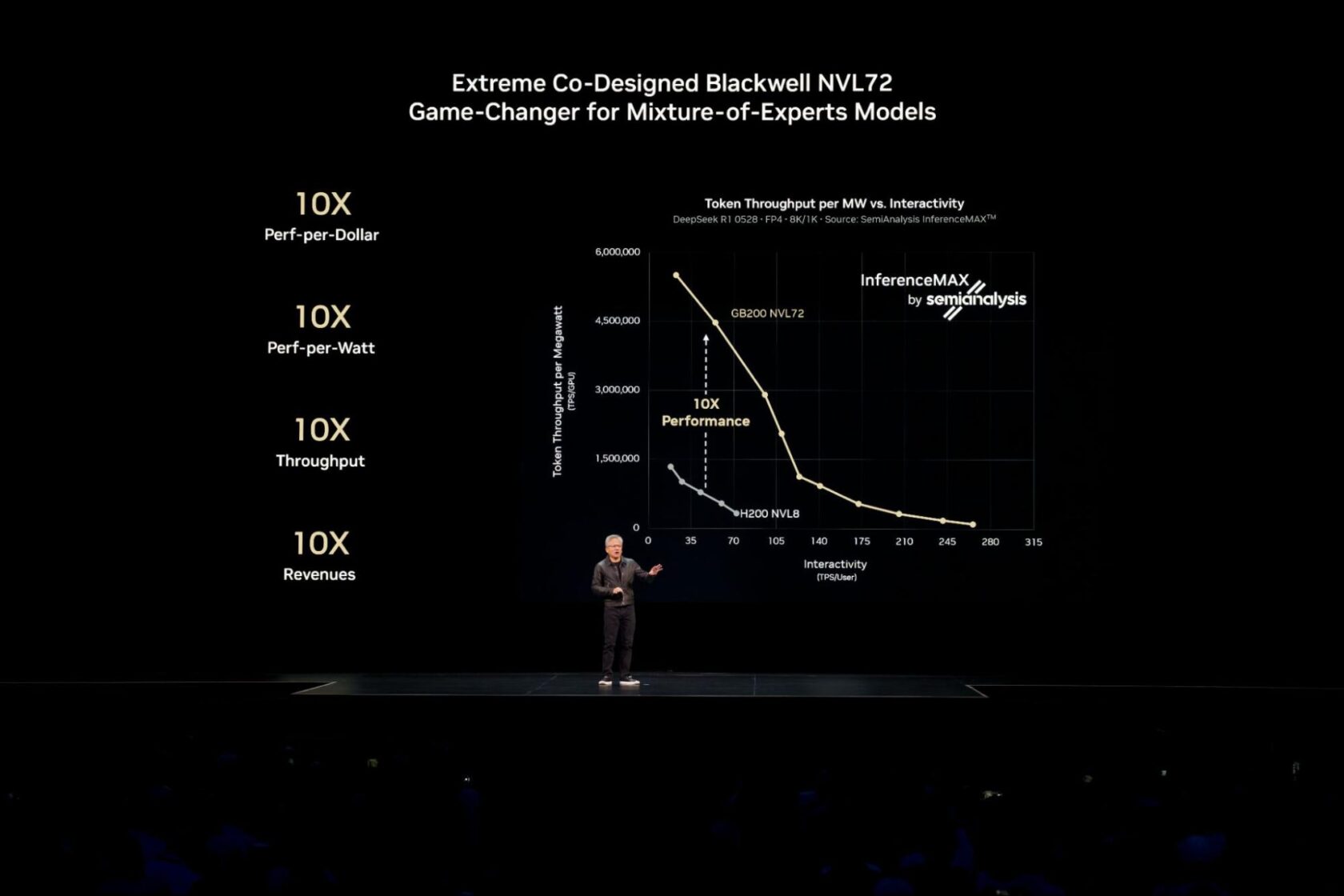
Архитектура NVIDIA Blackwell подтвердила лидерство в независимых тестах SemiAnalysis InferenceMAX, показав наивысшую производительность и эффективность при минимальной совокупной стоимости владения. Как отмечал генеральный директор NVIDIA Дженсен Хуанг на конференции GTC, Blackwell обеспечивает 10-кратный прирост производительности по сравнению с предыдущим поколением Hopper.
Для современных сложных AI-моделей, таких как масштабные mixture-of-experts (MoE) вроде DeepSeek-R1, традиционный подход с запуском на одном GPU становится узким местом. Решение — распределенный вывод, где задачи обработки входных данных (prefill) и генерации ответа (decode) разделяются между специализированными GPU.
NVIDIA мастерски превращает техническую сложность в рыночное преимущество. Пока конкуренты борются с базовой инфраструктурой, они уже решают проблемы оркестрации сотен GPU для единой модели. Правда, за такие мощности придется платить — и не только деньгами, но и зависимостью от их экосистемы.
Реальные результаты и облачная интеграция
Компания Baseten использовала NVIDIA Dynamo для ускорения вывода при генерации кода с длинным контекстом: в 2 раза быстрее и с увеличением пропускной способности на 60% без инвестиций в дополнительное оборудование. В исследовании Signal65 достигнута рекордная агрегатная пропускная способность 1,1 миллиона токенов в секунду на 72 GPU Blackwell Ultra.
Платформа Dynamo уже интегрирована с управляемыми Kubernetes-сервисами всех основных облачных провайдеров:
- Amazon Web Services ускоряет генеративный AI через Amazon EKS
- Google Cloud предоставляет рецепты оптимизации для AI Hypercomputer
- Microsoft Azure поддерживает многопользовательский вывод на Azure Kubernetes Service
- OCI обеспечивает вывод на OCI Superclusters
Упрощение оркестрации с NVIDIA Grove
API NVIDIA Grove в составе Dynamo решает ключевую проблему распределенного вывода — координацию специализированных компонентов. Разработчики могут описать всю систему одним декларативным спецификацией, например: «нужно три GPU-узла для prefill и шесть для decode, все на высокоскоростной interconnect».
Grove автоматически управляет сложной оркестрацией: масштабирует связанные компоненты, поддерживает правильные соотношения и зависимости, запускает их в нужном порядке и оптимально размещает в кластере для эффективной коммуникации.
По материалам NVIDIA Blog.





Оставить комментарий