
По мере масштабирования моделей машинного обучения специализированный аппаратно-программный стек становится не просто опциональным, а критически важным. Ironwood, последнее поколение тензорных процессоров Google, представляет собой передовое аппаратное обеспечение для продвинутых моделей вроде Gemini и Nano Banana — от масштабного обучения до высокопроизводительного инференса с низкой задержкой. В этом материале рассматриваются ключевые компоненты программного стека ИИ Google, интегрированные в Ironwood, и демонстрируется, как глубокая совместная разработка открывает новые возможности производительности, эффективности и масштабирования.
Фундамент совместной разработки
Современные базовые модели имеют триллионы параметров, требующих вычислений в ультра-больших масштабах. Мы спроектировали стек Ironwood с уровня кремния, чтобы решить эту задачу.
Основная философия стека Ironwood заключается в системном уровне совместной разработки, рассматривая весь TPU-кластер не как набор отдельных ускорителей, а как единый, целостный суперкомпьютер. Эта архитектура построена на пользовательской системе соединений, обеспечивающей массово-масштабируемый удаленный прямой доступ к памяти (RDMA), позволяя тысячам чипов обмениваться данными напрямую с высокой пропускной способностью и низкой задержкой, минуя центральный процессор. Ironwood имеет суммарно 1,77 ПБ непосредственно доступной HBM-памяти, где каждый чип содержит восемь стеков HBM3E с пиковой пропускной способностью HBM 7,4 ТБ/с и емкостью 192 ГиБ.
В отличие от универсальных параллельных процессоров, TPU представляют собой специализированные интегральные схемы (ASIC), созданные для одной цели: ускорения крупномасштабных рабочих нагрузок ИИ. Глубокая интеграция вычислений, памяти и сетевых возможностей составляет основу их производительности. На высоком уровне TPU состоит из двух частей:
- Аппаратное ядро: Ядро TPU сосредоточено вокруг плотного блока матричных операций (MXU) для матричных вычислений, дополненного мощным векторным процессором (VPU) для поэлементных операций (активации, нормализации) и SparseCores для масштабируемых поисковых операций встраивания. Эта специализированная аппаратная архитектура обеспечивает производительность Ironwood в 42,5 экзафлопс для вычислений FP8.
- Программная цель: Эта аппаратная архитектура явно таргетирована компилятором Accelerated Linear Algebra (XLA), использующим философию совместной программной разработки, которая сочетает общие преимущества оптимизации всей программы с точностью ручных кастомных ядер. Компиляторно-ориентированный подход XLA обеспечивает мощную базовую производительность путем слияния операций в оптимизированные ядра, насыщающие MXU и VPU. Этот подход обеспечивает хорошую производительность «из коробки» с широкой поддержкой фреймворков и моделей. Эта универсальная оптимизация затем дополняется кастомными ядрами (подробно описанными в разделе Pallas ниже) для достижения пиковой производительности на специфических комбинациях модель-аппаратура. Эта двойная стратегия является фундаментальным принципом совместной разработки.
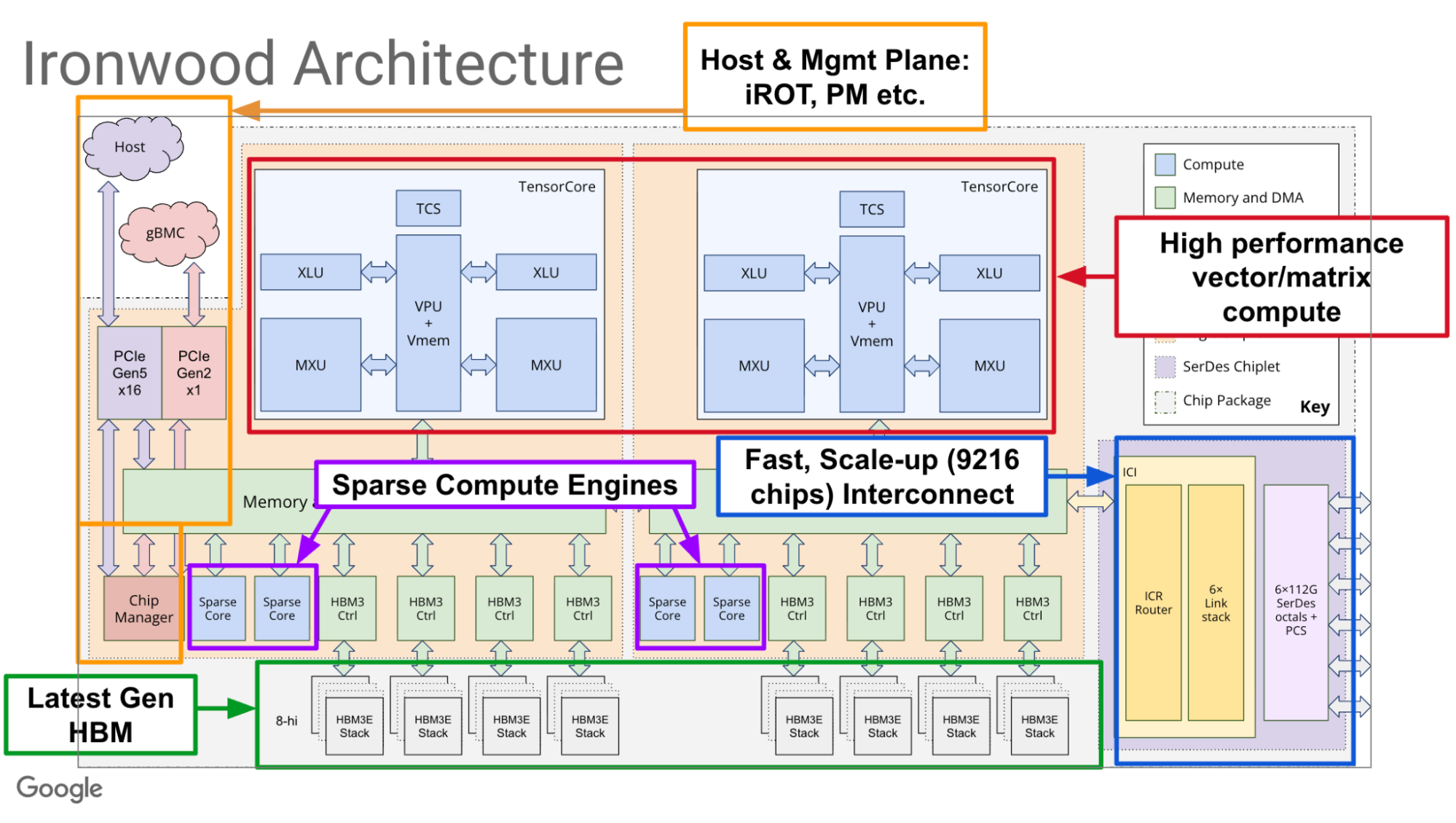
На рисунке ниже показана компоновка чипа Ironwood:
Эта специализированная разработка распространяется на соединения между TPU-чипами для массового вертикального и горизонтального масштабирования с суммарной пропускной способностью 88473,6 Тбит/с (11059,2 ТБ/с) для полного Ironwood суперкластера.
- Строительный блок: кубы и ICI. Каждый физический хост Ironwood содержит четыре TPU-чипа. Одиночная стойка таких хостов содержит 64 чипа Ironwood и формирует «куб». Внутри этого куба каждый чип соединен через множественные высокоскоростные соединения между чипами (ICI), формирующие прямую 3D-топологию тора. Это создает чрезвычайно плотную, все-со-всеми сетевую структуру, обеспечивая массовую пропускную способность и низкую задержку для распределенных операций внутри куба.
- Масштабирование с OCS: кластеры и суперкластеры. Для масштабирования за пределы одиночного куба множественные кубы соединяются через сеть оптических коммутаторов (OCS). Это динамическая, переконфигурируемая оптическая сеть, соединяющая целые кубы, позволяя системе масштабироваться от небольшого «кластера» (например, 256-чиповый Ironwood кластер с четырьмя кубами) до массивного «суперкластера» (например, 9,216-чиповая система со 144 кубами). Эта топология на основе OCS ключева для отказоустойчивости. Если куб или соединение выходит из строя, менеджер структуры OCS инструктирует OCS оптически обойти неисправный узел и установить новые, полные оптические цепи, соединяющие только здоровые кубы, подключая назначенный резерв. Эта динамическая переконфигурируемость позволяет как устойчивой работе, так и выделению эффективных «срезов» любого размера. Для крупнейших систем, достигающих сотен тысяч чипов, множественные суперкластеры могут соединяться через стандартную сеть дата-центра (DCN).
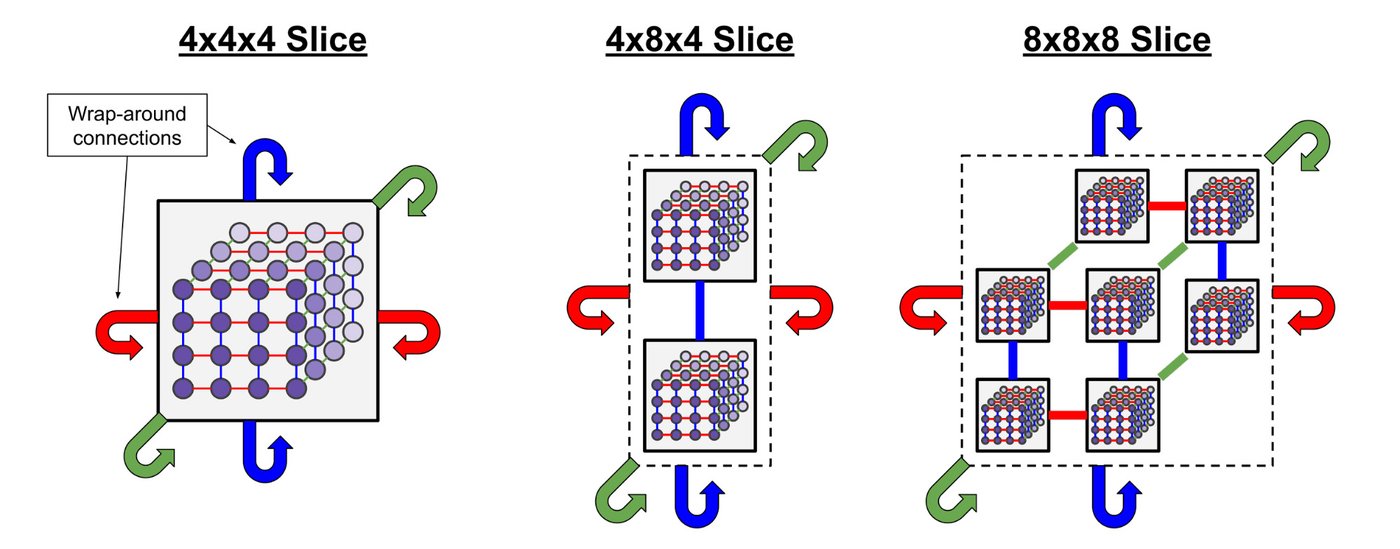
Чипы могут конфигурироваться в различные «срезы» с различными OCS-топологиями, как показано ниже.
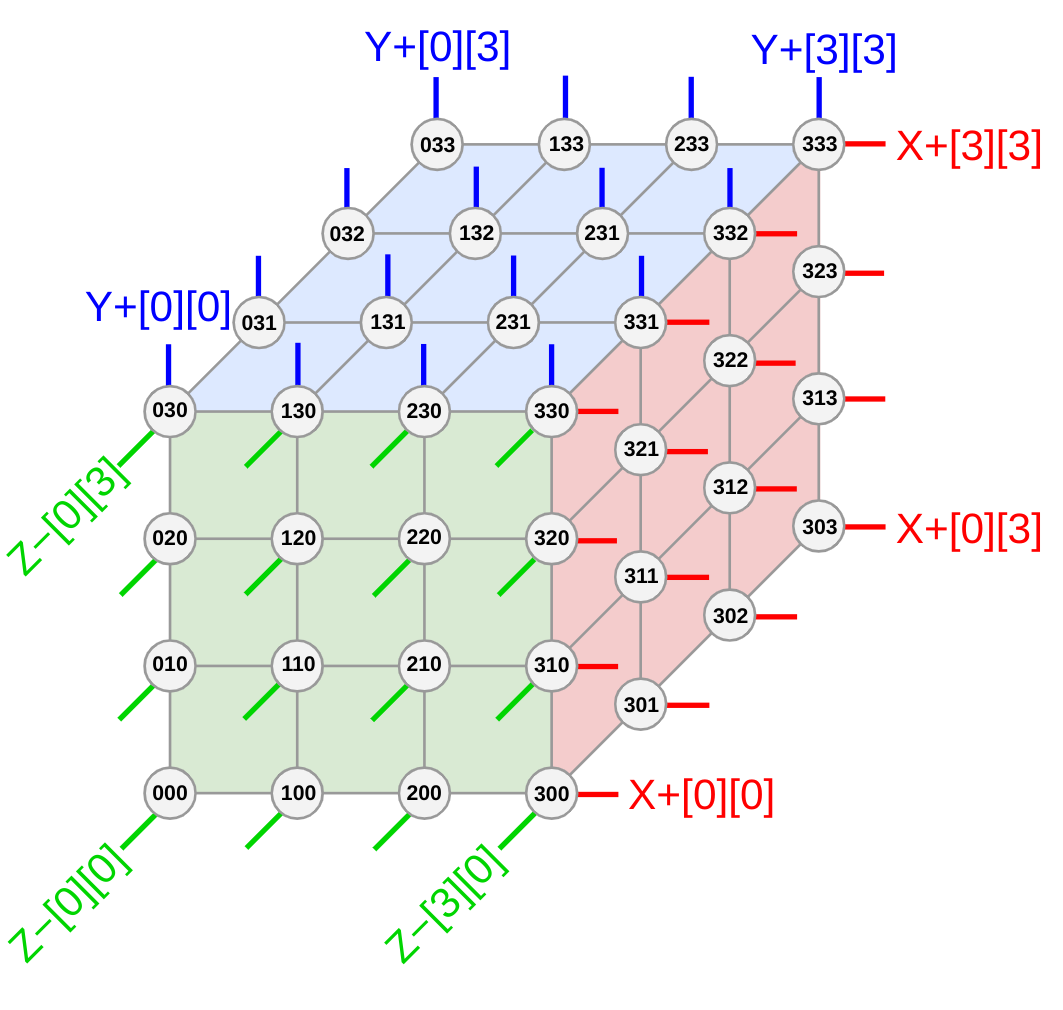
Каждый чип соединен с 6 другими чипами в 3D-торе и обеспечивает 3 различные оси для параллелизма.
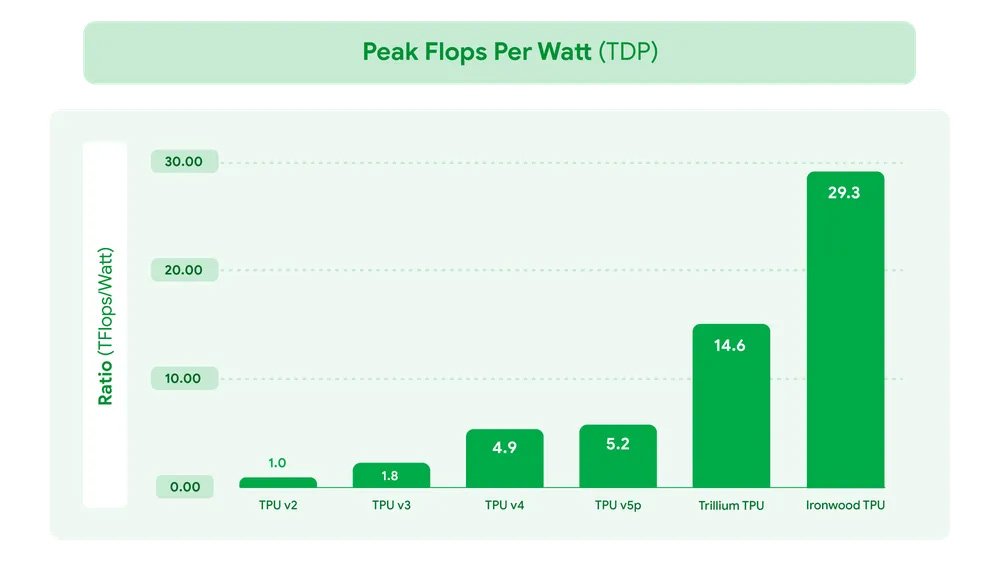
Ironwood обеспечивает эту производительность при фокусе на энергоэффективности, позволяя рабочим нагрузкам ИИ выполняться более рентабельно. Энергоэффективность Ironwood в 2 раза выше относительно Trillium, нашего предыдущего поколения TPU. Наши продвинутые решения жидкостного охлаждения и оптимизированный дизайн чипа могут надежно поддерживать до двух раз производительности стандартного воздушного охлаждения даже при непрерывных, тяжелых рабочих нагрузках ИИ. Ironwood почти в 30 раз более энергоэффективен, чем наш первый Cloud TPU 2018 года, и является нашим наиболее энергоэффективным чипом на сегодня.
Архитектура Ironwood демонстрирует эволюционный скачок в специализации аппаратного обеспечения для ИИ. В то время как конкуренты продолжают наращивать универсальные GPU, Google делает ставку на предельную специализацию — от матричных блоков до оптической коммутации. Интересно, что такая глубокая интеграция создает как преимущества в производительности, так и потенциальные проблемы совместимости для разработчиков, привыкших к более гибким решениям.
Оптимизация всего жизненного цикла ИИ
Мы используем принцип совместно разработанного аппаратно-программного стека Ironwood для доставки максимальной производительности и эффективности через каждую фазу разработки модели, со специфическими аппаратными и программными возможностями, настроенными для каждого этапа.
- Предварительное обучение: Эта фаза требует устойчивых, массово-масштабируемых вычислений. Полный 9,216-чиповый Ironwood суперкластер использует OCS и ICI структуру для работы как единый массивный параллельный процессор, достигая максимального устойчивого использования FLOPS через различные форматы данных. Запуск задачи такого масштаба также требует устойчивости, которая управляется высокоуровневыми программными фреймворками вроде MaxText, детализированного в Разделе 3.3, которые прозрачно обрабатывают отказоустойчивость и контрольные точки.
- Пост-обучение (дообучение и выравнивание): Эта стадия включает разнообразные, FLOPS-интенсивные задачи вроде контролируемого дообучения (SFT) и обучения с подкреплением (RL), все требующие быстрых итераций. RL, в частности, вводит сложные, гетерогенные паттерны вычислений. Эта стадия часто требует запуска двух различных типов задач конкурентно: высокопроизводительного, инференс-подобного сэмплинга для генерации новых данных (часто называемых ‘акторными развертками’), и вычислительно-интенсивных, обучение-подобных ‘learner’ шагов, выполняющих градиентные обновления. Высокопроизводительная сеть Ironwood с низкой задержкой и гибкое OCS-базированное срезирование идеальны для этого типа быстрого экспериментирования, эффективно управляя различными аппаратными требованиями как сэмплинга, так и градиентных обновлений. В Разделе 3.3 мы обсуждаем, как мы предоставляем оптимизированное программное обеспечение на Ironwood — включая референсные реализации и библиотеки — чтобы сделать эти сложные рабочие процессы дообучения и выравнивания легче для управления и эффективного выполнения.
- Инференс (обслуживание): В продакшене модели должны доставлять предсказания с низкой задержкой, высокой пропускной способностью и рентабельностью. Ironwood специально спроектирован для этого, с его большой встроенной памятью и вычислительной мощью, оптимизированной как для фазы «prefill» с большими батчами, так и для интенсивной к памяти пропускной способности фазы «decode» больших генеративных моделей.
Источник новости: Google Cloud Blog





Оставить комментарий