
Оглавление
Google Cloud сообщает, что их инфраструктурные решения для машинного обучения достигли стадии промышленной готовности. GKE Inference Gateway и сопутствующие инструменты теперь доступны для коммерческого использования, предлагая предприятиям готовые механизмы для развертывания и оптимизации ML-моделей в производственной среде.
Производительность инференса на новом уровне
Ключевое нововведение — балансировка нагрузки с учетом префиксов, система интеллектуальной маршрутизации запросов. Технология анализирует префиксы входящих запросов и направляет их на те же акселераторы, где уже обрабатывались аналогичные данные. Это позволяет повторно использовать кэш ключ-значение (KV cache), избегая повторных вычислений фазы предварительного заполнения.
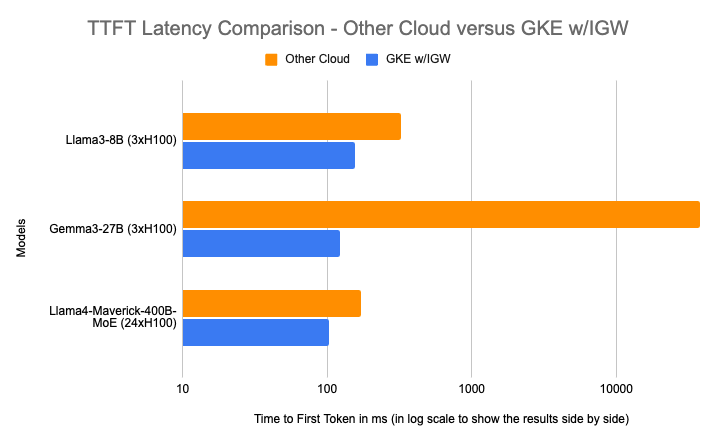
В результате время до первого токена (TTFT) сокращается на до 96% при пиковой нагрузке для нагрузок с повторяющимися префиксами. Для пользователей это означает практически мгновенные ответы в чат-ботах и других интерактивных приложениях.
Экономика вычислений: меньше железа, больше эффективности
Второй важный аспект — раздельное обслуживание, архитектура раздельного выполнения фаз предварительного заполнения и декодирования. Эти этапы имеют принципиально разные требования к ресурсам:
- Предварительное заполнение: вычислительно интенсивная, требует мощных вычислений
- Декодирование: интенсивная по памяти, зависит от скорости доступа к памяти
Раздельное масштабирование этих фаз позволяет увеличить пропускную способность на 60% по сравнению с традиционным подходом.
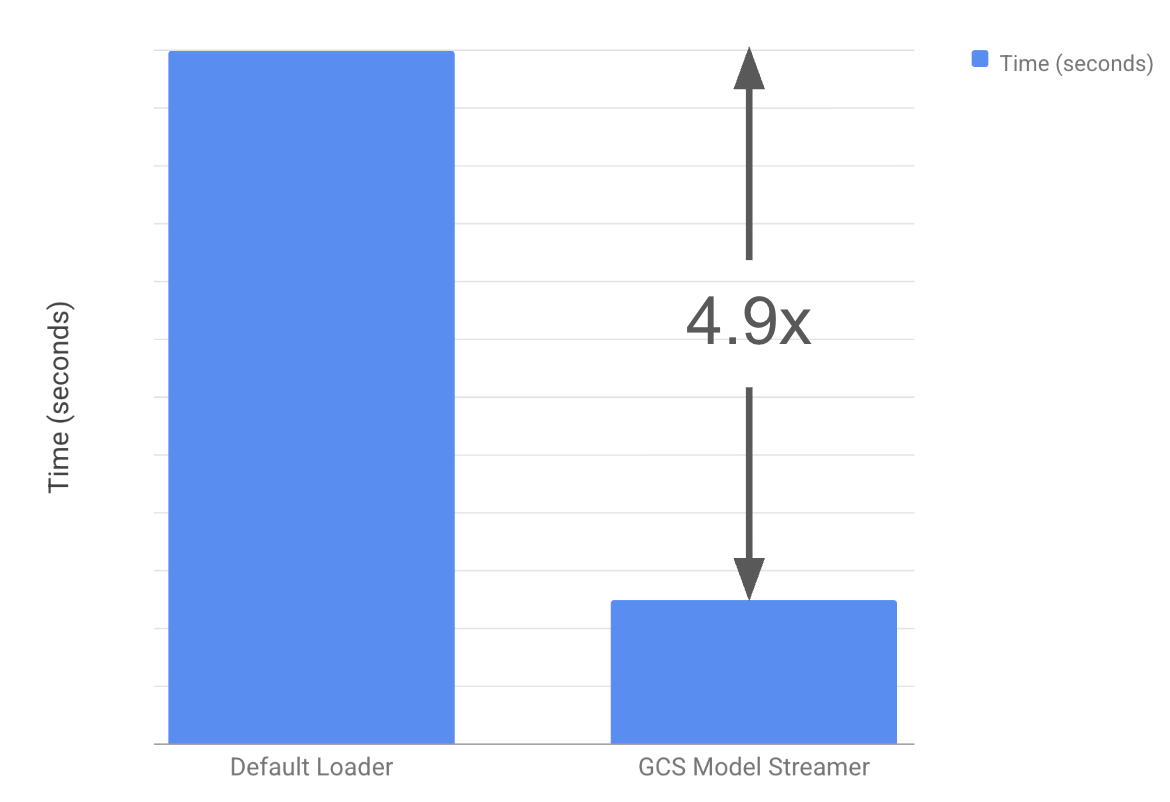
Для ускорения загрузки больших моделей (сотни гигабайт) теперь доступна интеграция с Run:ai model streamer и Google Cloud Storage. Пропускная способность до памяти акселераторов достигает 5.4 GiB/s, что сокращает время загрузки моделей в 4.9 раза.
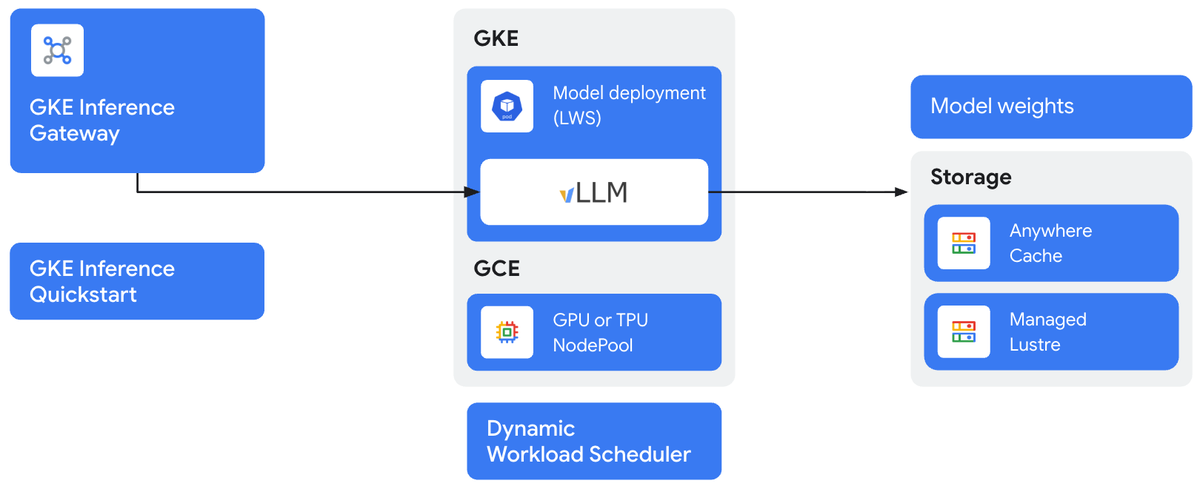
Подход, основанный на данных, к выбору инфраструктуры
GKE Inference Quickstart решает классическую проблему ML-инженеров: как выбрать оптимальную конфигурацию железа и софта под конкретную задачу. Сервис предлагает рекомендации на основе:
- Бенчмарков GPU и TPU против популярных моделей (Llama, Mixtral, Gemma)
- Более 100 тестов в неделю на различных конфигурациях
- Анализа стоимости и профилей задержек для разных сценариев
Google фактически монетизирует свой внутренний опыт эксплуатации Gemini и YouTube, предлагая тем же инструментарием воспользоваться внешним клиентам. Интересно наблюдать, как инфраструктурные решения из категории «магии» превращаются в товарные продукты с измеримыми KPI. Впрочем, заявленные 96% улучшения задержки звучат слишком оптимистично — на практике всё зависит от конкретной нагрузки и характера нагрузки.
Новые возможности GKE Inference Gateway и Quickstart доступны уже сегодня. Для компаний, развертывающих ML-модели в производственной среде, это может означать существенную экономию на инфраструктуре и улучшение пользовательского опыта.





Оставить комментарий