Оглавление
Пока большинство компаний только планируют переход на следующее поколение сетевой инфраструктуры, Google уже развертывает технологии, которые станут массовыми только к 2028 году. Как пишет The Next Platform, это необходимо для преодоления фундаментального узкого места в распределенных вычислениях для ИИ.
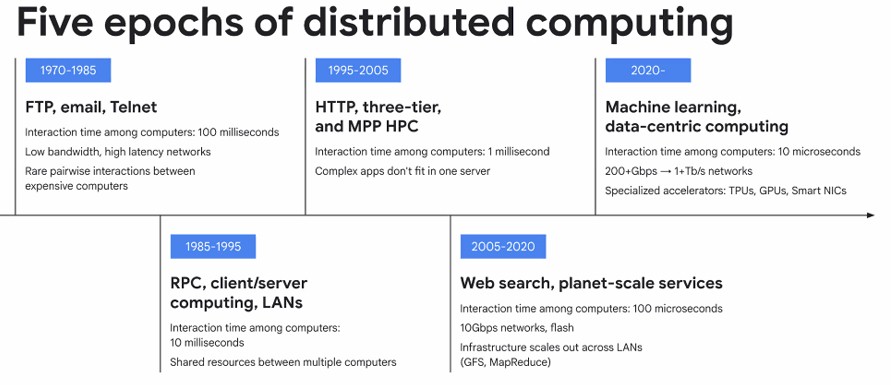
Пять эпох распределенных вычислений
Амин Вахдат, вице-президент Google по ИИ и инфраструктуре, выделяет пять отчетливых эпох в развитии распределенных вычислений:
- 1980-е: FTP/Email/Telnet — время отклика 100 мс
- 1990-е: Клиент-серверные приложения — 10 мс
- 2000-е: Веб-сервисы и облака — 1 мс
- 2010-е: Микросервисы и контейнеры — 100 мкс
- 2020-е: Машинное обучение — 10 мкс
Каждая новая эпоха уменьшала время взаимодействия между вычислительными узлами на порядок, что позволило перейти от простого обмена файлами к сложнейшим ИИ-системам.
Узкие места в эпоху ИИ
Современные GPU стоимостью $30,000–50,000 работают всего на 25–35% своей вычислительной мощности из-за ожидания данных от других ускорителей в кластере. В эпоху генеративного ИИ спрос на вычисления растет на 10X ежегодно — беспрецедентные темпы, которые не может обеспечить даже закон Мура.
«С 2000 по 2020 год мы достигли улучшения эффективности в 1000 раз при тех же затратах, — отмечает Вахдат. — Следующие 1000 раз улучшения должны быть достигнуты гораздо быстрее».
Предсказуемость ИИ-систем— ключевое преимущество. Если трафик можно предсказать, его можно оптимизировать и распланировать, что открывает путь к радикально новым сетевым архитектурам.
Миллионы XPU и необходимость capability-кластеров
Чтобы удовлетворить спрос на вычисления, ведущие игроки уже строят системы со 100,000–200,000 вычислительных узлов, а в ближайшие год-два речь пойдет о кластерах с 1 миллионом XPU. Это не capacity-кластеры для множества задач, а единые capability-системы, предназначенные для выполнения одной масштабной задачи — например, обучения гигантской языковой модели.
Анализ трафика при обучении модели Gemini показывает удивительную предсказуемность: на 30-секундных интервалах все выглядит гладко, но на 100-миллисекундных видны качели — ускорители то простаивают в ожидании данных, то поглощают их с максимальной скоростью.
Googleуже сегодня развертывает сетевые технологии, которые станут мейстримом только через 3-4 года. Это дает компании стратегическое преимущество в гонке ИИ, где скорость обучения моделей напрямую определяет конкурентные позиции.





Оставить комментарий