
Оглавление
Инженерные команды, занимающиеся машинным обучением, получают серьезное упрощение работы с облачными TPU в экосистеме Ray. Google Cloud анонсировал серию улучшений, которые делают использование тензорных процессоров в Kubernetes более естественным и менее трудоемким.
Библиотека Ray TPU для автоматизации работы с аппаратной топологией
TPU обладают уникальной архитектурой и специфическим стилем программирования SPMD (Single Programming Multiple Data). Крупные AI-задачи выполняются на срезе TPU — наборе чипов, соединенных высокоскоростной сетью interchip interconnect (ICI).
Ранее разработчикам приходилось вручную настраивать Ray для работы с этой аппаратной топологией. Неправильная конфигурация могла привести к фрагментации ресурсов между разными, несвязанными срезами, что вызывало серьезные проблемы с производительностью.
Новая библиотека ray.util.tpu абстрагирует эти аппаратные детали. Она использует функцию SlicePlacementGroup вместе с новым API label_selector для автоматического резервирования всего совместно расположенного среза TPU как единой атомарной единицы.
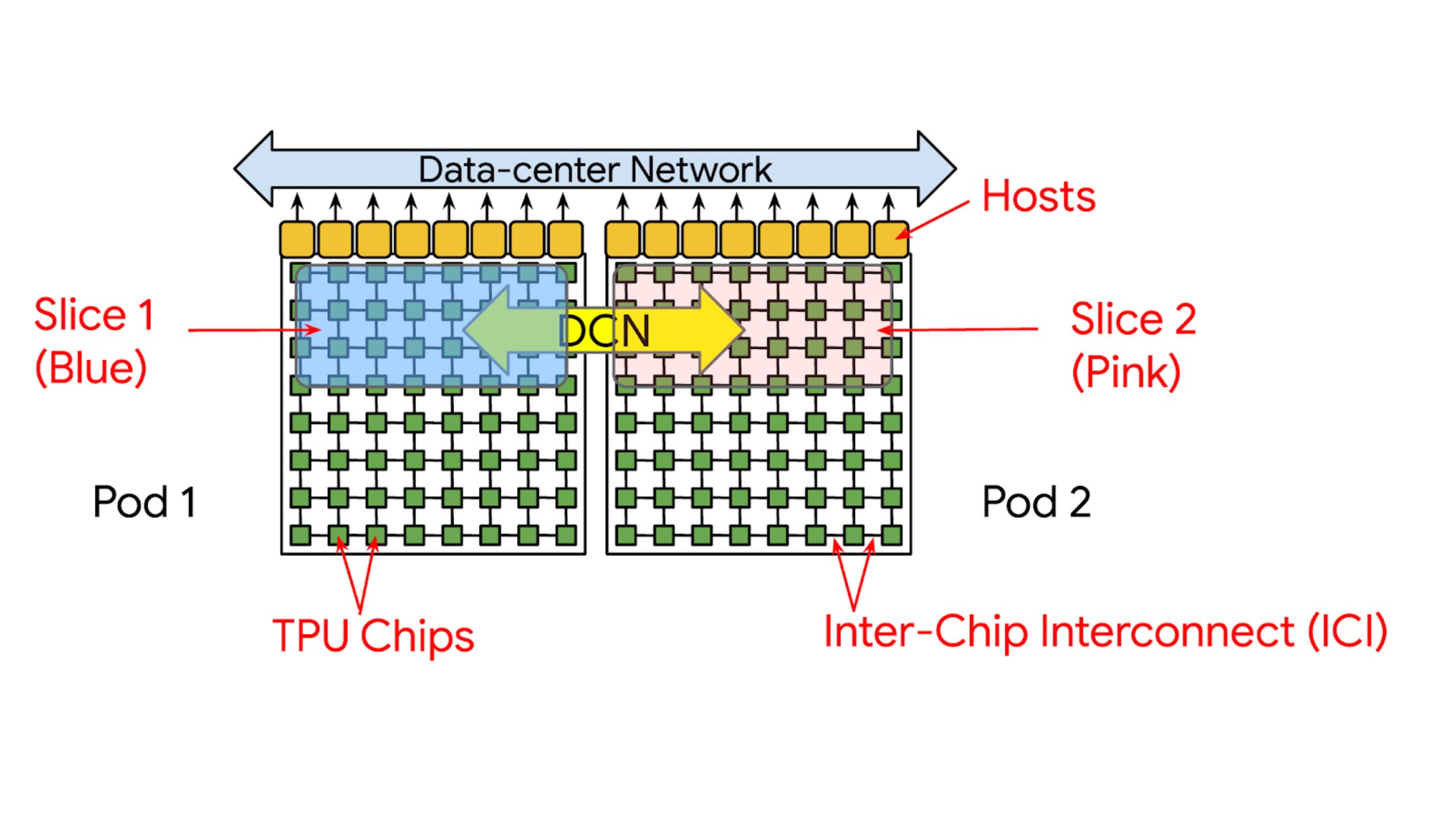
Это тот случай, когда инженерная элегантность скрывает под капотом сложнейшие проблемы распределенных систем. Автоматизация гарантий целостности среза TPU — это не просто удобство, а фундаментальное улучшение, которое предотвращает целый класс трудноотлаживаемых проблем с производительностью. Особенно впечатляет, что это открывает дорогу к настоящему мультисрезовому обучению — ранее невозможной опции из-за рисков фрагментации.
Расширенная поддержка JAX, Ray Train и Ray Serve
Разработки охватывают как обучение, так и вывод моделей. Для обучения Ray Train теперь предлагает альфа-поддержку JAX (через JaxTrainer) и PyTorch на TPU.
API JaxTrainer упрощает запуск JAX-нагрузок на мульти-хостовых TPU. Он автоматически обрабатывает сложную инициализацию распределенных хостов. Как показано в примере кода ниже, разработчику нужно только определить требования к аппаратному обеспечению в простом объекте ScalingConfig.
import jax import jax.numpy as jnp import optax import ray.train from ray.train.v2.jax import JaxTrainer from ray.train import ScalingConfig def train_func(): """Эта функция выполняется на каждом распределенном воркере.""" ... # Определяем конфигурацию аппаратного обеспечения для распределенной задачи scaling_config = ScalingConfig( num_workers=4, use_tpu=True, topology="4x4", accelerator_type="TPU-V6E", placement_strategy="SPREAD" ) # Определяем и запускаем JaxTrainer trainer = JaxTrainer( train_loop_per_worker=train_func, scaling_config=scaling_config, ) result = trainer.fit() print(f"Training finished on TPU v6e 4x4 slice")
API Ray Serve теперь поддерживают TPU, а благодаря улучшениям в vLLM TPU, разработчики могут продолжать использовать Ray на vLLM при переходе на тензорные процессоры.
API планирования на основе меток для упрощения получения ресурсов
Новый API планирования на основе меток интегрируется с пользовательскими классами вычислений GKE. Пользовательский класс вычислений — это простой способ определить именованную аппаратную конфигурацию.
Например, можно создать класс под названием cost-optimized, который указывает GKE сначала попытаться получить Spot-инстанс, затем перейти к FlexStart-инстансу Dynamic Workload Scheduler, и только в крайнем случае — к зарезервированному инстансу.

Этот же механизм label_selector также предоставляет глубокий контроль над аппаратным обеспечением TPU. При подготовке TPU-подов для среза GKE внедряет метаданные (такие как ранг воркера и топология) в каждый из них. KubeRay затем читает эти метаданные и автоматически преобразует их в специфические для Ray метки при создании узлов.
Метрики и логи TPU в одном месте
Теперь ключевые метрики производительности TPU, такие как использование TensorCore, рабочий цикл, использование High-Bandwidth Memory (HBM) и использование пропускной способности памяти, можно видеть непосредственно в Ray Dashboard. Также добавлены низкоуровневые логи libtpu.
Это значительно ускоряет отладку — теперь можно сразу проверить, вызвана ли ошибка кодом или самим аппаратным обеспечением TPU.
Вместе эти обновления представляют собой значительный шаг к тому, чтобы сделать TPU бесшовной частью экосистемы Ray. Они делают адаптацию существующих приложений Ray между GPU и TPU гораздо более простым процессом.
По материалам Google Cloud Blog





Оставить комментарий