Оглавление
Google Cloud Blog передает, что компания анонсировала новый рецепт для дезагрегированного инференса с использованием платформы NVIDIA Dynamo на своей инфраструктуре AI Hypercomputer. Решение позволяет значительно повысить эффективность выполнения LLM-моделей за счет разделения вычислительных фаз на специализированные пулы GPU.
Проблема традиционного инференса
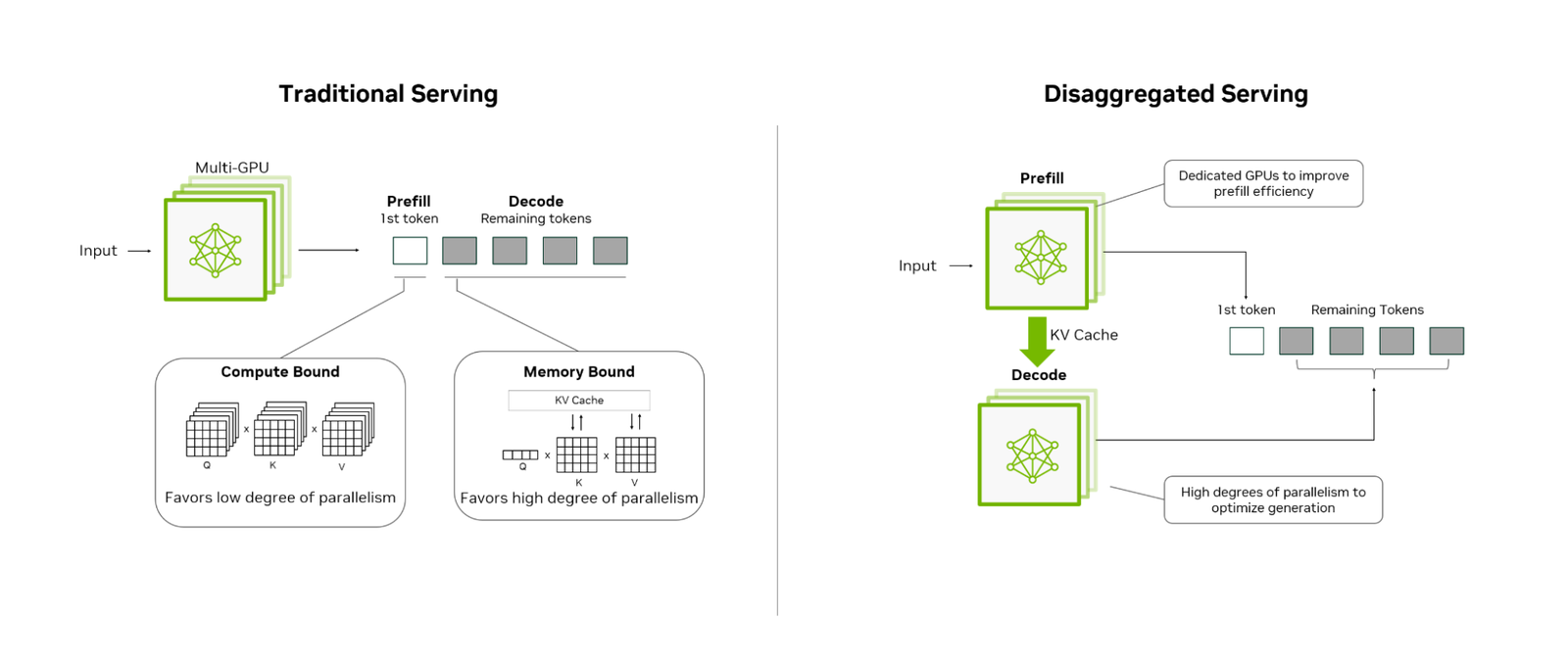
Классические GPU-архитектуры, отлично справляющиеся с обучением моделей, сталкиваются с фундаментальными ограничениями при инференсе. Многоуровневый характер генеративных запросов требует одновременной обработки вычислительно интенсивного префилла и ограниченной памятью генерации токенов на одном оборудовании, что создает конфликт ресурсов и снижает общую эффективность.
Архитектурное решение
Новый подход физически разделяет две ключевые фазы инференса:
- Префилл-фаза: обработка входного промпта, требует максимальной параллельной вычислительной мощности
- Декод-фаза: генерация ответа токен за токеном, критична к скорости доступа к памяти
Ключевые компоненты системы
Решение развертывается на инфраструктуре Google Cloud с использованием:
- Google Kubernetes Engine (GKE) для оркестрации отдельных нод-пулов
- Экземпляров A3 Ultra с GPU NVIDIA H200
- NVIDIA Dynamo как inference-сервера с интеллектуальным роутингом
- vLLM inference engine с оптимизацией PagedAttention
Дезагрегация инференса — это не просто инженерное улучшение, а фундаментальный сдвиг в архитектуре обслуживания LLM. Вместо того чтобы заставлять дорогостоящие GPU простаивать в ожидании памяти или вычислений, мы наконец-то начинаем обращаться с ними как со специализированными инструментами. Жаль только, что для использования всей этой магии нужно разбираться в Kubernetes лучше, чем средний data scientist.
Практическая реализация
Рецепт включает четкую последовательность шагов для развертывания:
- Первоначальная настройка переменных окружения и секретов
- Установка платформы Dynamo и CRD
- Деплой inference-бэкенда для конкретной модели
- Обработка inference-запросов
Поддерживаются как single-node конфигурации (4 GPU для префилла + 4 GPU для декода), так и multi-node развертывания. Текущая реализация оптимизирована для модели Llama-3.3-70B-Instruct, но в будущем планируется поддержка дополнительных GPU и inference-движков.
Преимущества подхода
Дезагрегированная архитектура позволяет:
- Масштабировать каждую фазу независимо по требованию
- Избегать блокировок между вычислительно сложными и ограниченными памятью задачами
- Достигать значительно более высокой общей пропускной способности
- Максимально утилизировать дорогостоящие GPU-ресурсы
Решение особенно актуально для продуктивных сред с высокими требованиями к задержкам и пропускной способности, где традиционные подходы уже не справляются с нагрузкой.





Оставить комментарий