
Оглавление
Как сообщает PyTorch, совместная работа AMD и команды PyTorch из Meta* позволила достичь почти идеального масштабирования при обучении гигантских моделей Mixture-of-Experts на кластере из 1024 GPU AMD Instinct MI325X. Результаты впечатляют: ускорение обучения DeepSeek-V3-671B в 2.77 раза и 96% эффективность масштабирования при переходе с 128 на 1024 графических процессора.
Что такое TorchTitan и почему это важно
TorchTitan — это готовый фреймворк от Meta* для крупномасштабного обучения языковых моделей. Его ключевые преимущества:
- Конфигурационный подход к масштабированию — настройка параллелизма через единый TOML-файл
- Поддержка разнородных архитектур — от плотных моделей вроде Llama 3 до гибридных и MoE
- Модульная конструкция — возможность замены оптимизированных ядер без изменения кода
По сути, TorchTitan предлагает единый путь от прототипирования на ноутбуке до промышленного развертывания на кластерах.
Особенности моделей Mixture-of-Experts
MoE — это альтернатива плотным трансформерам, где вместо одного MLP-блока используется пул экспертов. Маршрутизатор направляет каждый токен лишь к нескольким экспертам из общего пула.
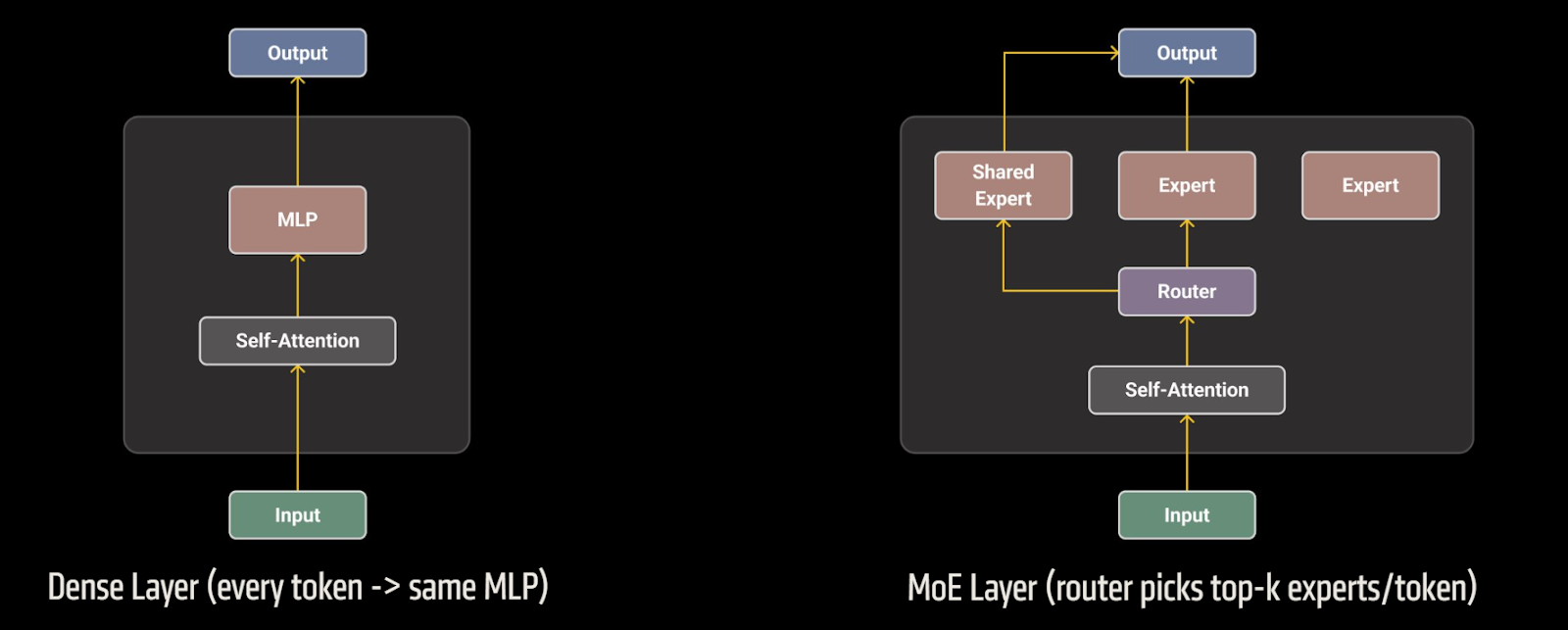
Источник: pytorch.org
Эта архитектура позволяет моделям достигать сотен миллиардов параметров при сохранении вычислительной эффективности. DeepSeek-v3 и Llama 4 демонстрируют успешное сочетание MoE и плотных слоев.
Вызовы обучения MoE-моделей
Несмотря на преимущества, распределенное обучение MoE сталкивается с серьезными проблемами:
- Низкая утилизация GPU — микроматричные операции не загружают вычислительные блоки
- Коммуникационные узкие места — All-to-All коллективные операции становятся доминирующими
- Сложность параллелизма — комбинация FSDP, Pipeline и Expert Parallelism требует точной синхронизации
- Нестабильность маршрутизации — неравномерная загрузка экспертов замедляет сходимость
Аппаратное обеспечение AMD Instinct MI325X
GPU MI325X с 256 ГБ HBM3E и пропускной способностью более 6 ТБ/с решают ключевую проблему MoE — позволяют размещать больше экспертов локально, уменьшая межсерверный трафик. Это дает тройной эффект:
- Больше экспертов на GPU без фрагментации модели
- Стабильность обучения благодаря меньшему количеству отбрасываемых токенов
- Снижение нагрузки на сеть за счет уменьшения степени Expert Parallelism
Стратегия параллелизма
Используется многомерный подход:
- Expert Parallelism (EP) — распределение экспертов между GPU
- Fully-Sharded Data Parallelism (FSDP) — шардинг параметров для экономии памяти
- Pipeline + Virtual Pipeline Parallelism — уменьшение простоев в конвейере
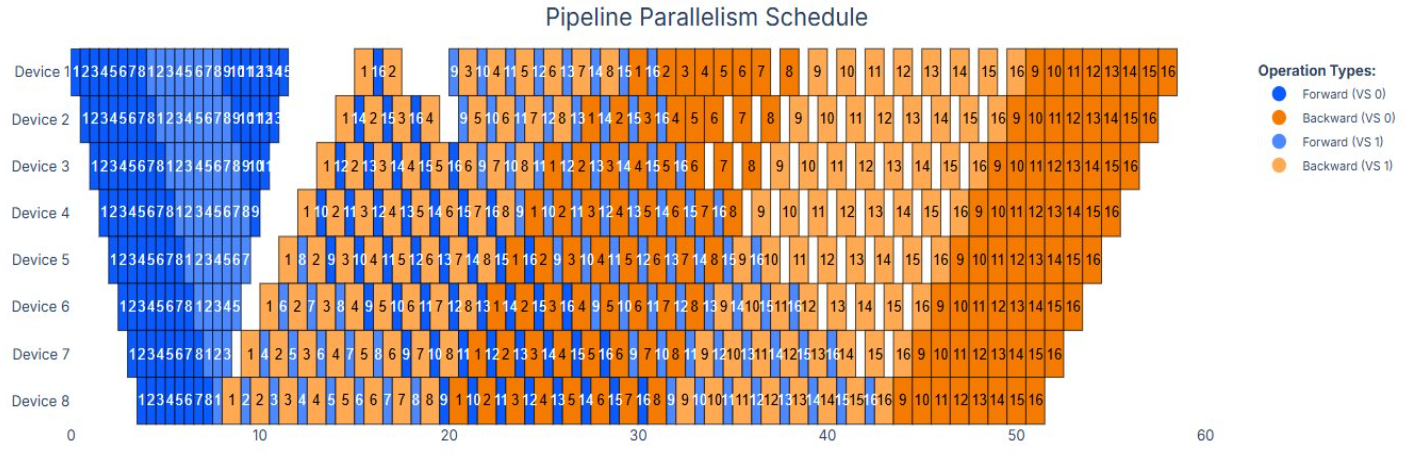
Источник: pytorch.org
Такая комбинация позволяет сбалансировать вычислительную нагрузку, использование памяти и сетевой трафик.
Primus-Turbo: библиотека оптимизации AMD
Primus-Turbo — это высокопроизводительная библиотека для обучения моделей на GPU AMD. Она предоставляет оптимизированные операции (GEMM, attention, grouped GEMM) и коммуникационные примитивы.
Достижение 96% эффективности масштабирования на тысяче GPU — это не просто красивые цифры, а свидетельство зрелости открытого стека для обучения больших моделей. Особенно впечатляет, что это сделано на полностью открытом ПО, что демонстрирует реальную альтернативу проприетарным решениям. Война фреймворков для распределенного обучения выходит на новый уровень, и это хорошо для всей индустрии.
Результаты работы показывают, что современные аппаратно-программные стеки позволяют эффективно обучать модели с сотнями миллиардов параметров без компромиссов в производительности. Открытость всего инструментария создает здоровую конкуренцию на рынке инфраструктуры для ИИ.
*Meta признана экстремистской и запрещена в РФ





Оставить комментарий