
Оглавление
Cloudflare пишет о разработке внутренней платформы Omni, которая решает ключевую проблему индустрии ИИ — неэффективное использование графических процессоров. Решение позволяет запускать больше моделей на одном GPU через интеллектуальное управление памятью и изоляцию процессов.
Архитектура платформы Omni
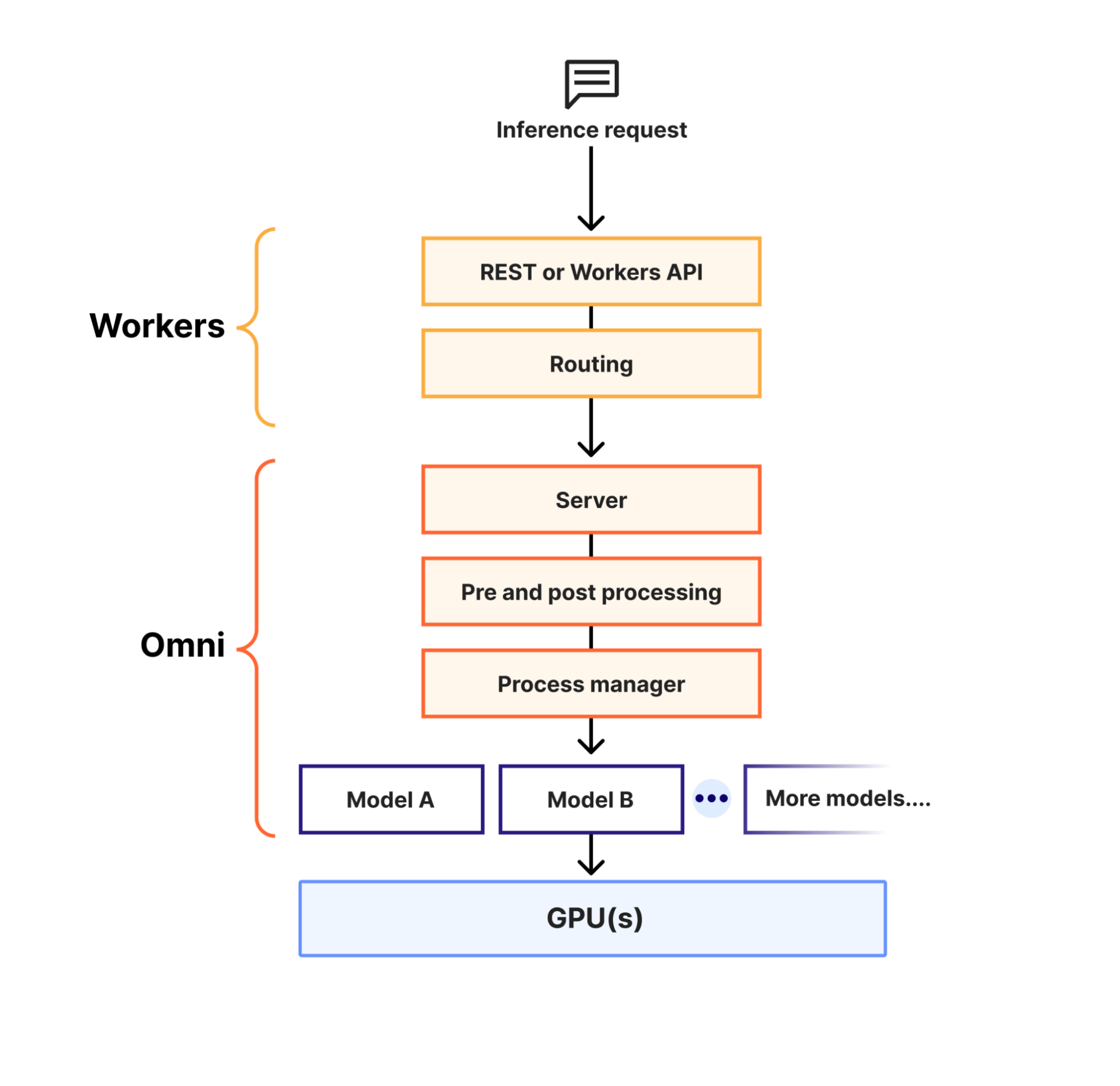
Omni представляет собой платформу для запуска и управления AI-моделями на edge-узлах Cloudflare. Система использует единую плоскость управления (планировщик), которая:
- Автоматически провизионит модели и создает новые экземпляры под нагрузкой
- Загружает веса моделей, Python-код и зависимости
- Распределяет нагрузку между несколькими GPU
- Собирает метрики для биллинга и логирования
Запросы на вывод поступают от Workers AI через уровень маршрутизации к ближайшему экземпляру Omni с доступной емкостью.
Легковесная изоляция процессов
Вместо традиционных контейнеров на модель Omni использует точечную изоляцию через:
- Процессные пространства имен и cgroups для контроля памяти
- Виртуальные окружения Python через uv
- Виртуальную файловую систему на базе FUSE для эмуляции /proc/meminfo
Решение с FUSE критично важно, поскольку Python-библиотеки типа psutil читают системную информацию из /proc/meminfo, не учитывая ограничения cgroups. Omni подменяет эти данные, предоставляя каждой модели актуальную информацию о ее лимитах памяти.
# Enter the mount (file system) namespace of a child process $ nsenter -t 8 -m $ mount ... none /proc/meminfo fuse ... $ cat /proc/meminfo MemTotal: 7340032 kB MemFree: 7316388 kB MemAvailable: 7316388 kB
Техническое и изящное решение проблемы совместимости Python с cgroups. Многие компании сталкиваются с подобными проблемами при контейнеризации AI-нагрузок, но обычно идут путем перевгрузки контейнеров. Cloudflare обладает инженерным прагматизмом.
Оптимизация использования GPU-памяти
Ключевая инновация Omni — новый подход к использованию памяти графического процессора. Система позволяет размещать на одном GPU модели, совокупно требующие больше памяти, чем физически доступно.
Например, на GPU с 10 ГБ памяти Omni может запустить 2 модели по 10 ГБ каждая. Сейчас платформа настроена на запуск 13 моделей с аллокацией около 400% GPU memory на одном процессоре, экономя 4 GPU.
Технически это реализовано через:
- Инжекцию CUDA stub-библиотеки
- Перехват вызовов cuMalloc* и cudaMalloc*
- Принудительное использование unified memory mode NVIDIA
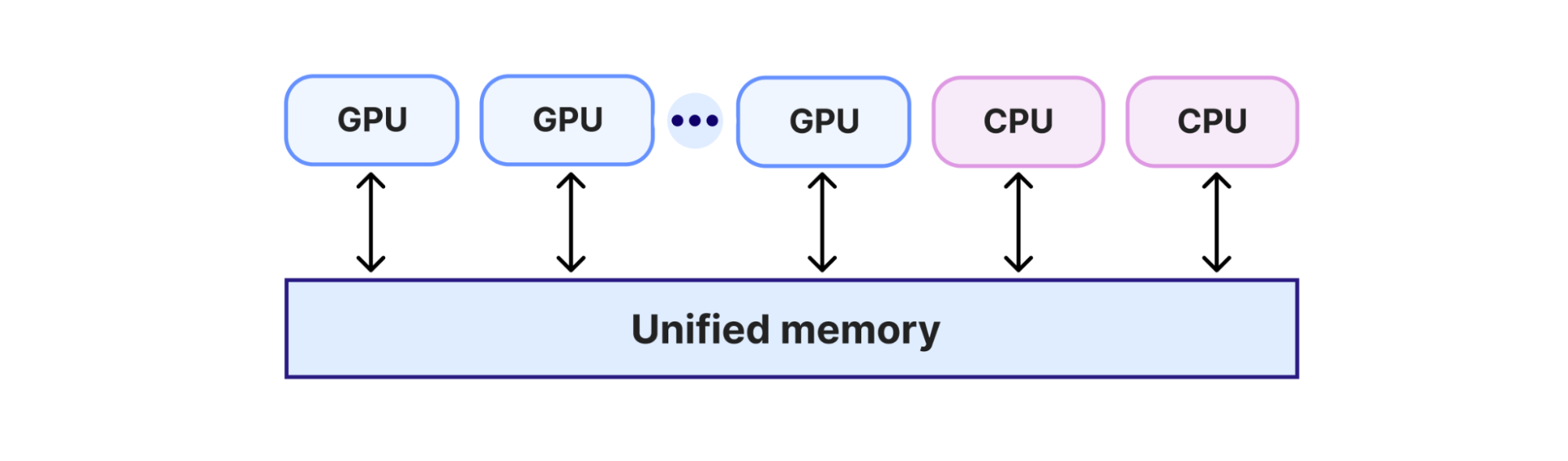
Режим единой памяти позволяет CUDA использовать единое адресное пространство для графического процессора и процессора, что очень важно для предотвращения превышения подписки.





Оставить комментарий