Оглавление
21 августа 2025 года масштабный трафик от одного клиента привел к перегрузке прямых каналов между Cloudflare и дата-центром AWS us-east-1, вызвав серьезные задержки и потерю пакетов для множества пользователей. Инцидент длился около четырех часов и затронул клиентов, чьи серверы располагались в этом регионе AWS.
Техническая подоплека инцидента
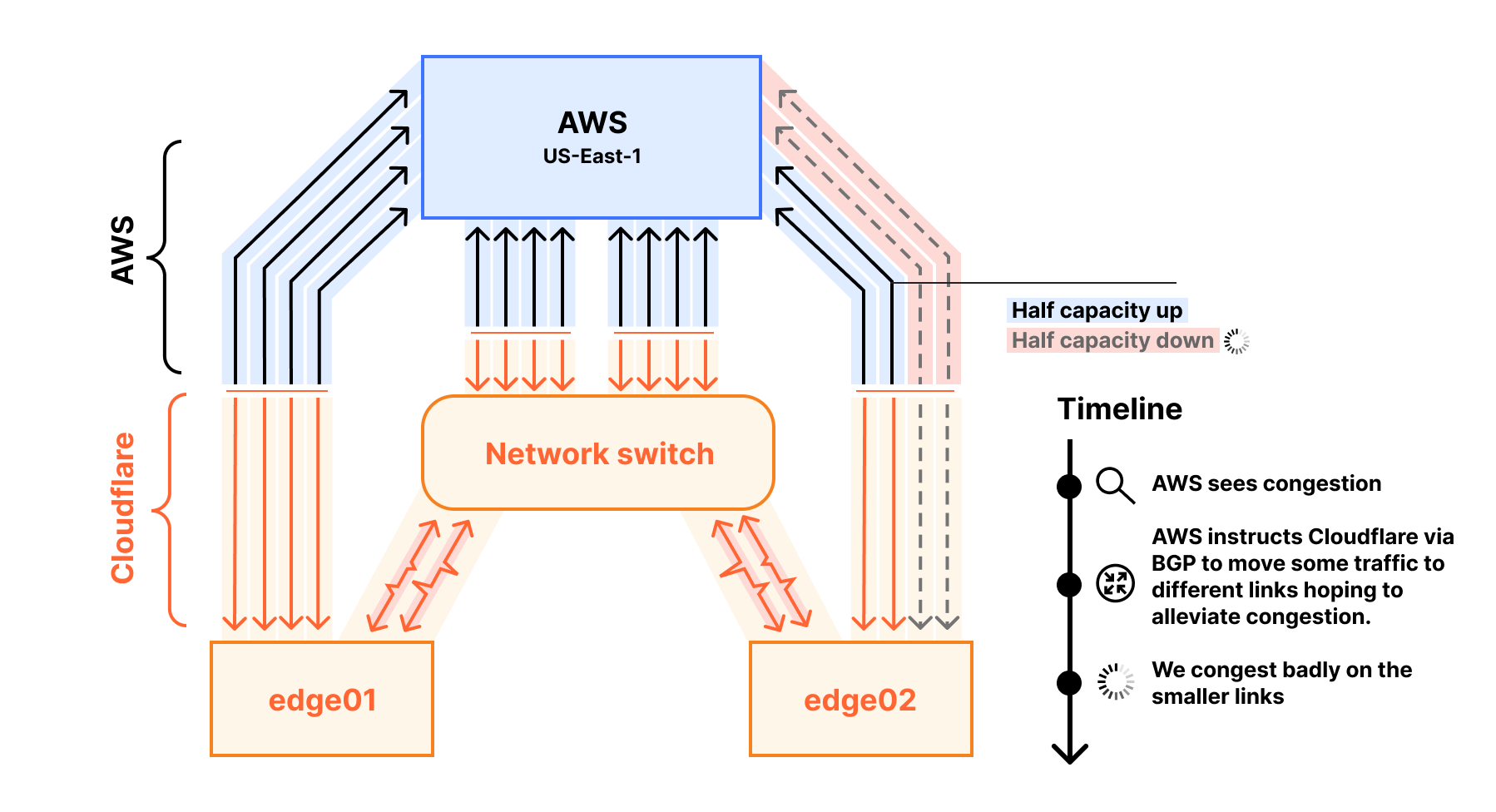
Cloudflare работает как обратный прокси, кэшируя контент и уменьшая нагрузку на origin-серверы клиентов. Когда запрашиваемый контент отсутствует в кэше, система обращается к исходному серверу, что и создает исходящий трафик с платформы.
Внутренняя сеть Cloudflare спроектирована с запасом пропускной способности, но в данном случае трафик одного клиента оказался настолько объемным, что исчерпал все доступные прямые пиринговые соединения с AWS us-east-1. Ситуацию усугубило то, что один из каналов уже работал в половинном режиме из-за предыдущего сбоя, а междатацентровые соединения (DCI) не были своевременно масштабированы.
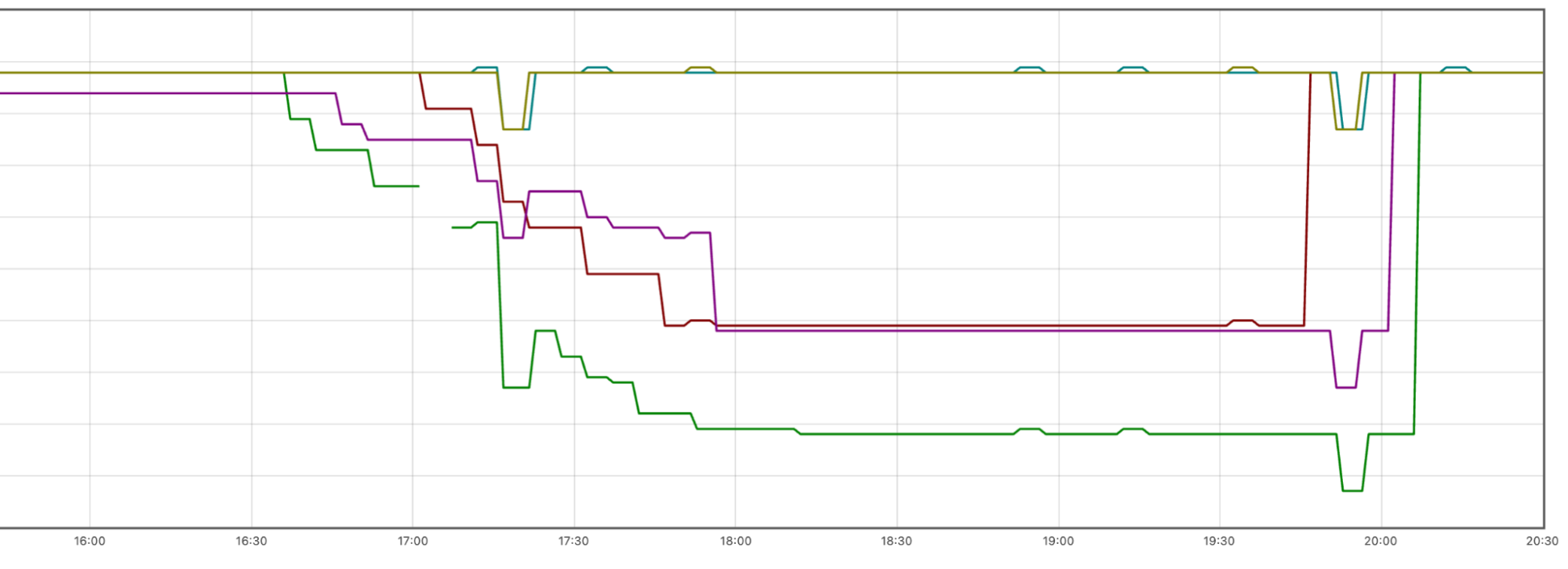
Хронология событий
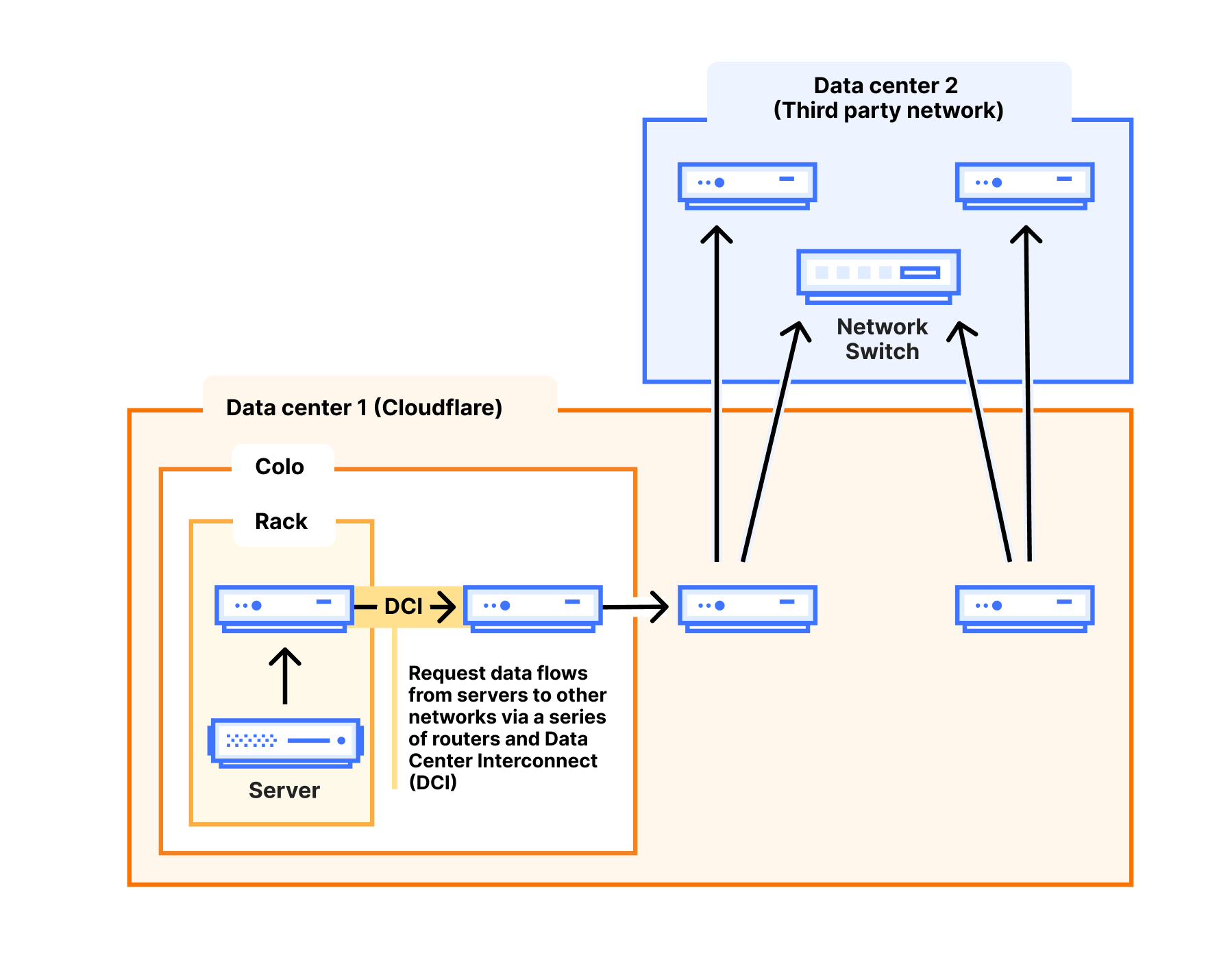
Инцидент развивался по классическому сценарию каскадного отказа:
- 16:27 UTC — начало трафиковой атаки от одного клиента
- 16:37 UTC — AWS начинает отзыв BGP-префиксов для снижения нагрузки
- 17:22 UTC — отзыв префиксов приводит к перенаправлению трафика и усугублению ситуации
- 19:27 UTC — ручное управление трафиком со стороны Cloudflare и AWS начинает давать результат
- 20:18 UTC — полное восстановление работы
Графики показывают резкий рост трафика в 16:27, совпадающий с началом проблем, и последующие попытки AWS стабилизировать ситуацию через манипуляции с BGP-анонсами:

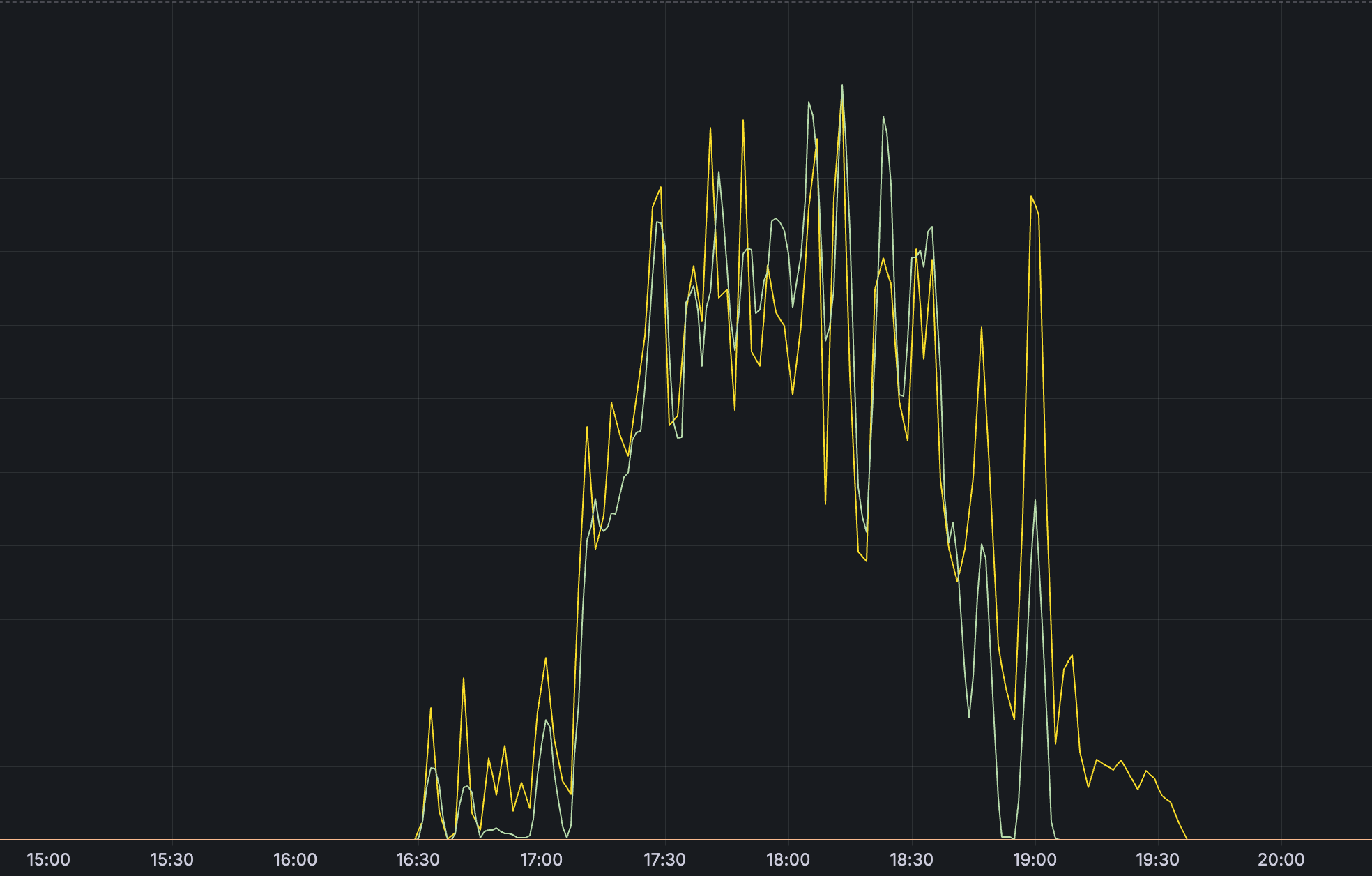
Последствия и метрики
Перегрузка сетевых очередей привела к массовому дропу пакетов, что отразилось на ключевых метриках производительности:
Этот инцидент наглядно демонстрирует фундаментальную проблему современных облачных инфраструктур — отсутствие надежной изоляции между клиентами. Когда один клиент может монополизировать общие ресурсы и повлиять на тысячи других, это говорит о архитектурных просчетах. Cloudflare предстоит серьезная работа по внедрению механизмов приоритизации и ограничения трафика на уровне сетевой инфраструктуры, а не только на уровне приложений.
Планы по предотвращению
Cloudflare анонсировала многоуровневую стратегию предотвращения подобных инцидентов:
- Разработка механизмов выборочной деприоритизации трафика проблемных клиентов
- Ускорение планов по апгрейду междатацентровых соединений
- Улучшение мониторинга и автоматического реагирования на сетевые аномалии
По материалам Cloudflare Blog.





Оставить комментарий