
Оглавление
Год назад компания Cerebras представила свой API для инференса, установив новые стандарты производительности в области искусственного интеллекта. В то время как провайдеры на основе GPU генерировали от 50 до 100 токенов в секунду, Cerebras обеспечивал от 1000 до 3000 токенов в секунду для различных моделей с открытыми весами, таких как Llama, Qwen и GPT-OSS.
Скептики тогда утверждали, что превзойти GPU поколения Hopper от NVIDIA — это одно, но настоящая проверка наступит со следующим поколением Blackwell. Теперь, в конце 2025 года, облачные провайдеры наконец-то развертывают системы GB200 Blackwell, и пришло время вернуться к вопросу: кто быстрее в AI-инференсе — NVIDIA или Cerebras?
Открытое противостояние: GPT-OSS 120B
GPT-OSS-120B от OpenAI сегодня является ведущей моделью с открытыми весами, разработанной американской компанией, широко используемой благодаря своим мощным возможностям рассуждения и программирования. Согласно тестам Artificial Analysis, большинство поставщиков сегодня запускают GPT-OSS-120B в диапазоне от 100 до 300 токенов в секунду, что отражает производительность широко распространенных GPU NVIDIA H100.
Производительность: преимущество за Cerebras

Источник: www.cerebras.ai
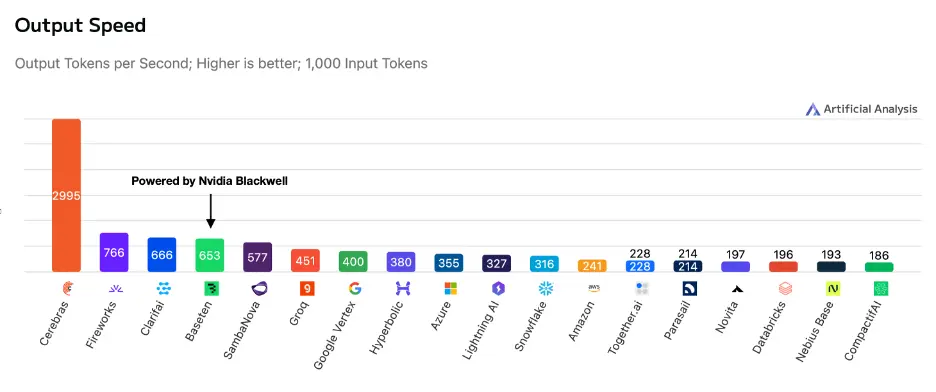
В прошлом месяце Baseten опубликовал первые результаты работы GPT-OSS-120B на новейшем GPU Blackwell от NVIDIA, достигнув 650 токенов в секунду — лучший результат, когда-либо достигнутый на GPU на тот момент. Для достижения этого рубежа Baseten запустил модель на восьми GPU GB200, соединенных через NVLink, используя Tensor Parallel 8 (TP8) для распределения модели, TensorRT-LLM и NVIDIA Dynamo для динамической оптимизации графа, а также EAGLE-3 спекулятивное декодирование для ускорения генерации токенов. Это был впечатляющий результат, демонстрирующий пиковую производительность Blackwell в готовом к производству облаке инференса.
С этим результатом Baseten не только превзошел всех других поставщиков GPU на рынке, но и обогнал такие компании, как Groq, которые полагались на скорость как на свое основное преимущество. Blackwell показал, что преимущество в 2-3 раза над GPU быстро теряется, когда NVIDIA обновляет свое оборудование ежегодно.
В заслугу Baseten следует поставить то, что они включили Cerebras в свои результаты, показав, что наше оборудование запускает модель GPT-OSS-120B со скоростью более 3000 токенов в секунду. Это стало возможным благодаря нашей wafer-scale архитектуре, которая хранит всю модель в памяти на кристалле, устраняя ограничения пропускной способности GPU. Примечательно, что Cerebras Wafer Scale Engine 3, выпущенный в 2024 году, до сих пор превосходит новейшее поколение Blackwell от NVIDIA почти в 5 раз — подчеркивая долговременное преимущество вычислительной архитектуры, специально созданной для крупномасштабного AI-инференса.
Не только быстро, но и выгодно по цене
Cerebras всегда был известен своей скоростью — но нас часто спрашивают: стоит ли он своих денег? В большинстве высокопроизводительных продуктов скорость подчиняется закону убывающей отдачи. Ferrari стоит в 10 раз больше, чем Camry, но едва ли в 3 раза быстрее. Так где же находится Cerebras на этой кривой?
Источник: www.cerebras.ai
Cerebras обеспечивает 3000 токенов в секунду по цене $0,75 за миллион токенов, в то время как Baseten обеспечивает 650 токенов в секунду по цене $0,50 за миллион токенов — соотношение цена-производительность составляет 4000 против 1300. Другими словами, Cerebras лишь немного дороже, но при этом в несколько раз быстрее — обратный пример Ferrari–Camry. Вы платите не в 10 раз больше за маргинальное улучшение; вы платите немного больше за огромный скачок в производительности.
Архитектурное преимущество wafer-scale подхода Cerebras становится особенно очевидным на больших моделях типа GPT-OSS-120B, где традиционные GPU упираются в ограничения межчиповой коммуникации. Пока NVIDIA пытается компенсировать это сложными системами типа NVLink, Cerebras просто исключает эту проблему целиком — вся модель помещается в памяти одного кристалла. Ирония в том, что Blackwell, при всех своих улучшениях, все еще борется с фундаментальными ограничениями GPU-архитектуры, в то время как Cerebras переосмыслил саму концепцию AI-ускорителя.
Cerebras — по-прежнему самый быстрый инференс в 2025 году
Nvidia Blackwell — это существенное обновление по сравнению с Hopper, улучшающее максимальную скорость GPU-инференса в 2-3 раза и обгоняющее конкурентов с небольшими чипами AI, таких как Groq. Cerebras — единственная архитектура, которая превосходит Nvidia, с подавляющим преимуществом в 5 раз в флагманской модели AI с открытыми весами от OpenAI. Мы с нетерпением ждем возможности снова обратиться к таблицам лидеров в 2026 году.
Источник новости: Cerebras





Оставить комментарий