Оглавление
В развернувшейся битве за лидерство в inference-вычислениях для больших языковых моделей компания Cerebras утверждает о решительном преимуществе своей системы CS-3 над конкурентом от Groq. Согласно внутренним тестам, wafer-scale архитектура Cerebras показывает до шести раз более высокую производительность при сравнимой стоимости.
Архитектурные различия и производительность
Обе компании решают ключевую проблему современных LLM — ограничение пропускной способности памяти. Однако подходы кардинально отличаются: Cerebras использует wafer-scale двигатель с 21+ петабайт/с пропускной способности on-chip SRAM, тогда как Groq полагается на потоковую передачу данных через множество легковесных ядер.
Независимые тесты от Artificial Analysis демонстрируют впечатляющий разрыв: модель oss-gpt-120B показывает ~3000 токенов/с на Cerebras против ~493 токенов/с на Groq. Аналогичная картина наблюдается с Llama 4 Maverick и Llama 3.3 70B — более 2500 токенов/с против 400-500 токенов/с у конкурента.
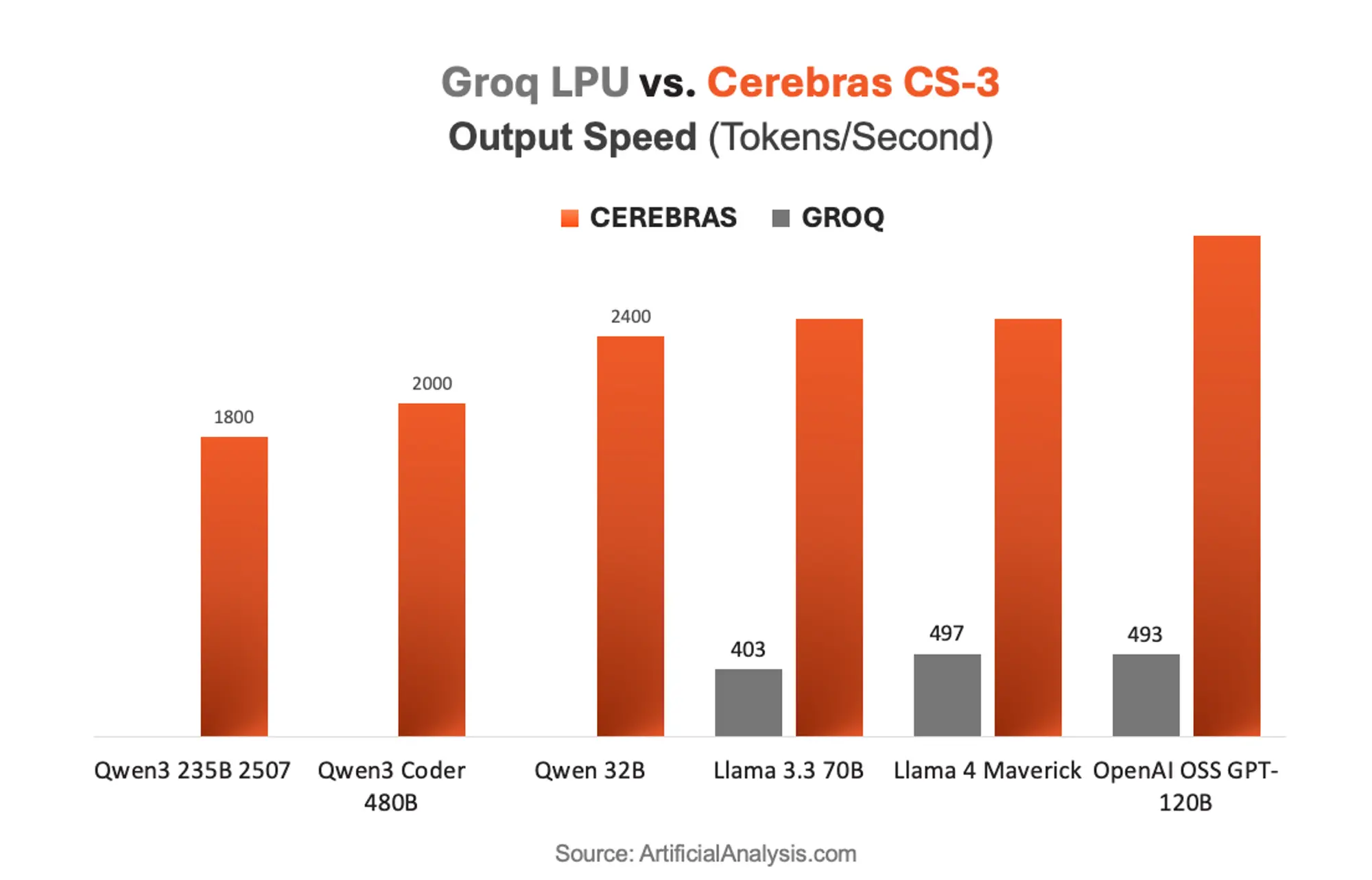
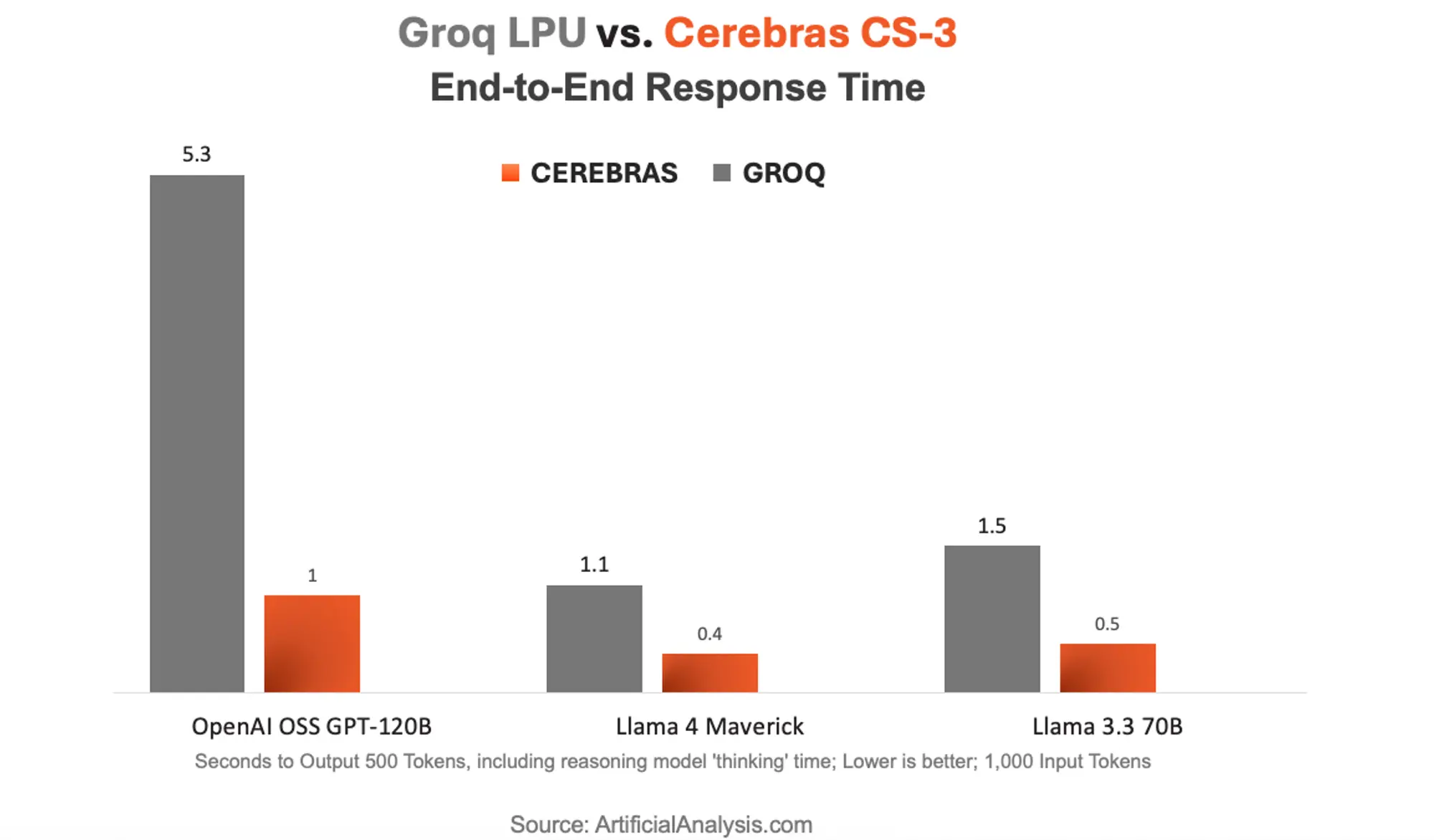
При измерении end-to-end времени ответа — от промта до получения результата — преимущество Cerebras достигает пятикратного размера. Это особенно критично для приложений реального времени, таких как conversational AI и генерация кода.
Экономическая эффективность
Ценовое преимущество Cerebras выглядит еще более убедительным при анализе соотношения цены и производительности. Система предлагает до 6-кратного преимущества по этому показателю, при этом стоимость либо сравнима, либо до 50% выше, чем у Groq.
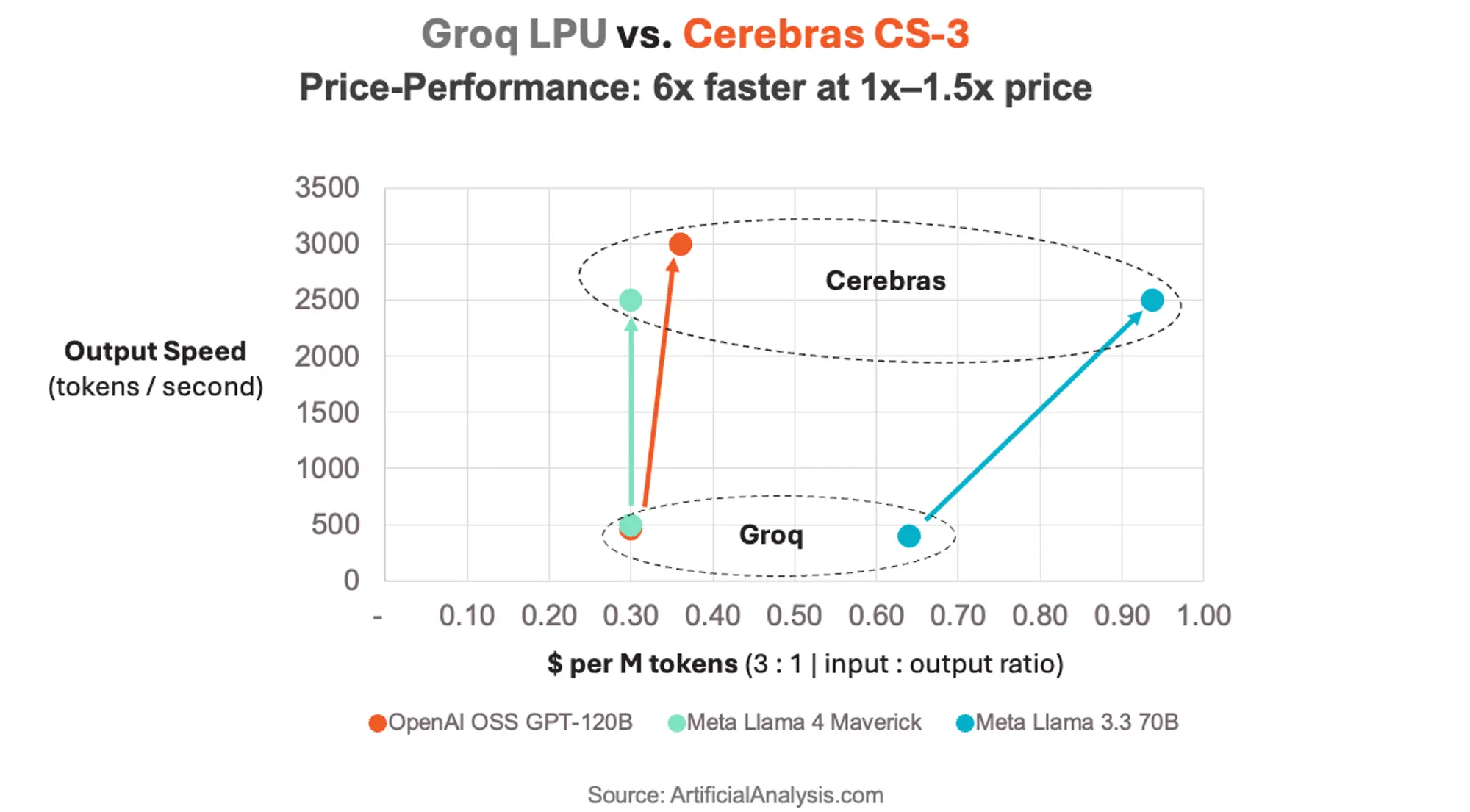
Более высокая пропускная способность на одно устройство обеспечивает лучшую совокупную эффективность затрат при масштабировании. Groq часто требует множества LPU, работающих параллельно для больших моделей, что снижает как производительность, так и экономическую эффективность.
Энергетическая эффективность и точность
При мощности ~27 кВт и ~125 PFLOPS CS-3 демонстрирует примерно трехкратное превосходство по вычислениям на ватт по сравнению с 8-GPU системой DGX. Удержание весов в on-chip SRAM минимизирует внешний трафик, снижая энергопотребление на токен.
Ключевое различие — поддержка precision: Cerebras нативно работает с 16-битной точностью, тогда как Groq оптимизирован для 8-битных моделей. Это означает, что большинство моделей на Groq жертвуют точностью ради скорости через квантование.

Технологическое превосходство wafer-scale подхода Cerebras не вызывает сомнений, но стоит помнить, что это сравнение от самого производителя. В реальных сценариях преимущество может быть менее выраженным, особенно для специализированных задач с низкой задержкой по времени, где архитектура Groq показывает себя хорошо. Однако шестикратный разрыв в производительности — это серьезный аргумент, который заставит многих архитекторов пересмотреть свои планы.
Функциональность и надежность
Cerebras поддерживает как обучение, так и inference, тогда как Groq LPU — исключительно inference-движок. Это дает Cerebras преимущество в разработке и кастомизации моделей.
Вопрос масштабирования и надежности также решен по-разному: каждый чип Groq имеет всего 230 МБ SRAM, требуя сотен чипов для 70B-параметровой модели. Это создает сложные кластеры с проприетарной сетевой инфраструктурой, увеличивающей точки отказа.
Cerebras спроектирована для бесперебойной работы корпоративного уровня — одно устройство позволяет обслуживать значительно большие модели с высокой производительностью и доступностью более 99 %.
Рыночная доступность и экосистема
CS-3 уже доступен для развертывания локально или через облачные платформы, включая Meta*, Vercel, Hugging Face и OpenRouter. Groq предлагает аналогичные опции через GroqCloud и Hugging Face, но Cerebras имеет более широкий набор опций развертывания.
В вопросах простоты использования и приватности данных системы демонстрируют паритет: обе предоставляют OpenAI-совместимые API, встроенные эндпоинты и аналогичные гарантии безопасности.
Экосистемы обеих компаний меньше, чем у NVIDIA, но быстро растут, имея примерно по 20 ключевых интеграций каждая.
По материалам Cerebras.
* Meta (признана экстремистской и запрещена в РФ)





Оставить комментарий