
Оглавление
Компания Cerebras пишет, что их система CS-3 демонстрирует беспрецедентное превосходство над флагманским решением NVIDIA. В независимых тестах wafer-scale архитектура показала 21-кратное преимущество в скорости инференса при работе с большими языковыми моделями.
Техническое превосходство архитектуры
Ключевое отличие Cerebras CS-3 — wafer-scale подход, где весь процессор размещен на одной кремниевой подложке. Это устраняет узкие места традиционных GPU-кластеров, связанные с межчиповой коммуникацией. Память и вычислительные блоки находятся на одном кристалле, что обеспечивает исключительную пропускную способность — до 21 ПБ/с против 8 ТБ/с у HBM3e памяти в Blackwell.
Результаты независимых тестирований
Согласно отчету SemiAnalysis, CS-3 обрабатывает Llama 3 70B с конфигурацией 1024/4096 токенов в 21 раз быстрее B200. В тестах Artificial Analysis на модели gpt-oss-120B Cerebras показывает 2700+ токенов/секунду против 900 у NVIDIA, а при 10 параллельных запросах — 580 против 2700+.
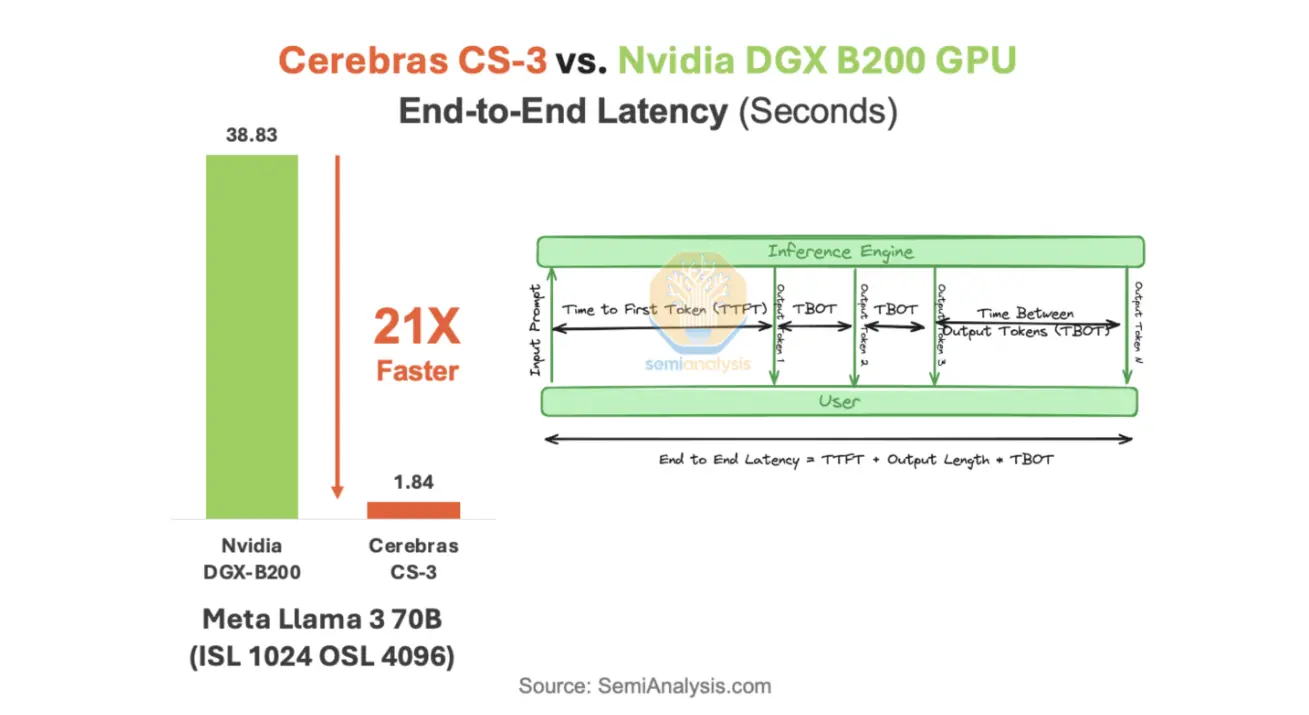
Для Llama 4 Maverick разрыв также существенен: 2500+ токенов/секунду у Cerebras против 1000 у NVIDIA. Важно отметить, что тесты Cerebras проводятся в production-среде, тогда как результаты Blackwell — в оптимизированных бенчмарк-конфигурациях.

Экономические и энергетические преимущества
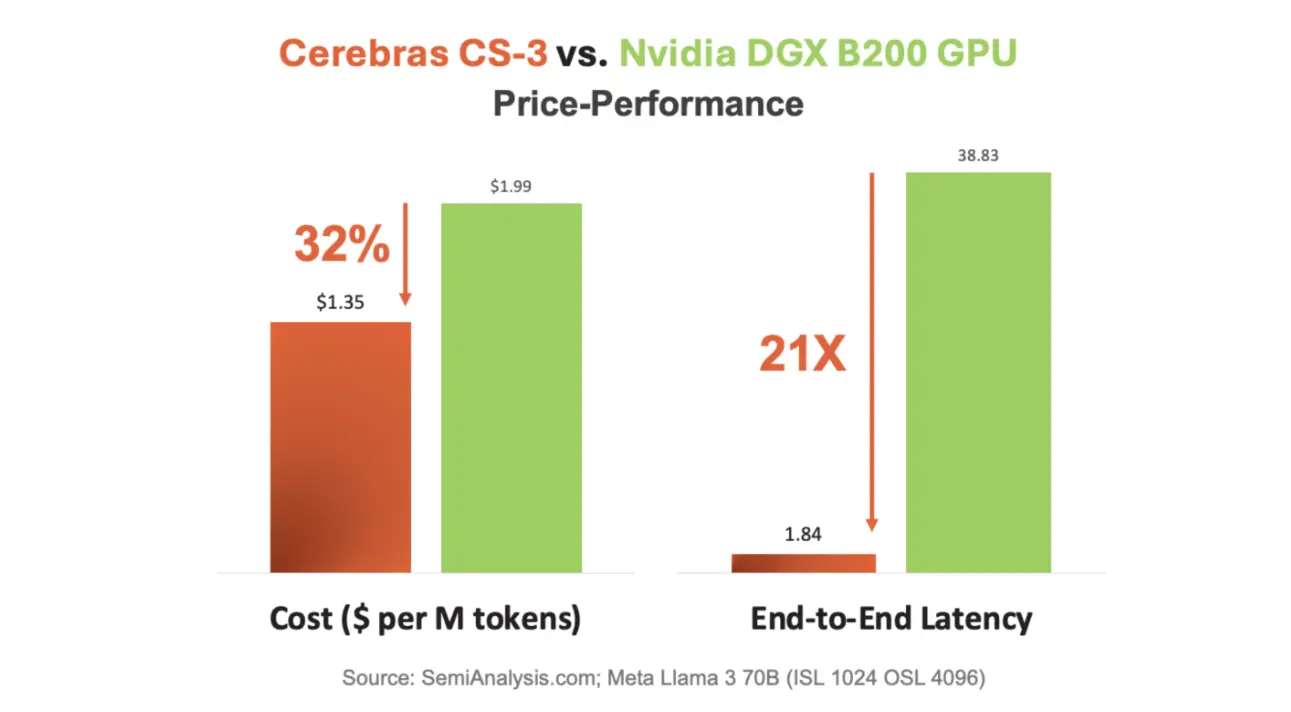
Cerebras CS-3 не только быстрее, но и экономичнее: стоимость обработки на 32% ниже, а энергопотребление — на треть меньше. Это критически важно при текущем дефиците энергомощностей для AI-инфраструктуры.
Точность и возможности для рассуждений
21-кратное превосходство в скорости открывает новые возможности для chain-of-thought обработки. Модели могут выполнять в 21 раз больше «рассуждений» за фиксированное время, что напрямую улучшает точность ответов.
Обучение и масштабирование
В обучении моделей Cerebras предлагает до 10-кратного ускорения благодаря упрощенному масштабированию. В то время как GPU-кластеры требуют сложной сетевой инфраструктуры и распределенных систем, CS-3 масштабируется как единое устройство.
Wafer-scale архитектура — это не просто инженерная экзотика, а прагматичный ответ на реальные ограничения GPU-кластеров. 21-кратное преимущество в инференсе — это тот переломный момент, когда количественное превосходство переходит в качественное: задачи, которые раньше были непрактичными (генерация кода в реальном времени, агентные приложения), становятся возможными. NVIDIA доминировала слишком долго, и появление реального конкурента — лучшая новость для рынка.
Такие компании как GlaxoSmithKline и AstraZeneca уже подтвердили значительное ускорение обучения на платформе Cerebras — с недель до дней. Это меняет сам подход к R&D в AI, позволяя исследователям экспериментировать с архитектурами и гиперпараметрами значительно быстрее.





Оставить комментарий