Оглавление
Сообщество разработчиков Hugging Face запустило масштабный образовательный проект — комплексный курс по большим языковым моделям (LLM), который структурирован по двум основным направлениям: для исследователей и инженеров.
Два пути освоения LLM
Курс предлагает два четко разделенных трека обучения:
- LLM Scientist — для тех, кто хочет создавать и улучшать сами модели, используя современные методы
- LLM Engineer — для разработчиков, которые создают приложения на основе LLM и развертывают их в рабочую среду
Редкий случай, когда качественный образовательный контент по самой горячей теме ИИ доступен бесплатно. В то время как рынок наводнен платными курсами сомнительного качества, Hugging Face предлагает структурированный путь от основ архитектуры Transformer до продвинутых техник тонкой настройки — и все это с открытыми исходниками и практическими примерами.
Интерактивное обучение с AI-ассистентом
Для повышения эффективности обучения авторы создали специального ИИ-ассистента, доступного через HuggingChat или ChatGPT. Ассистент отвечает на вопросы и тестирует знания в персонализированном формате.
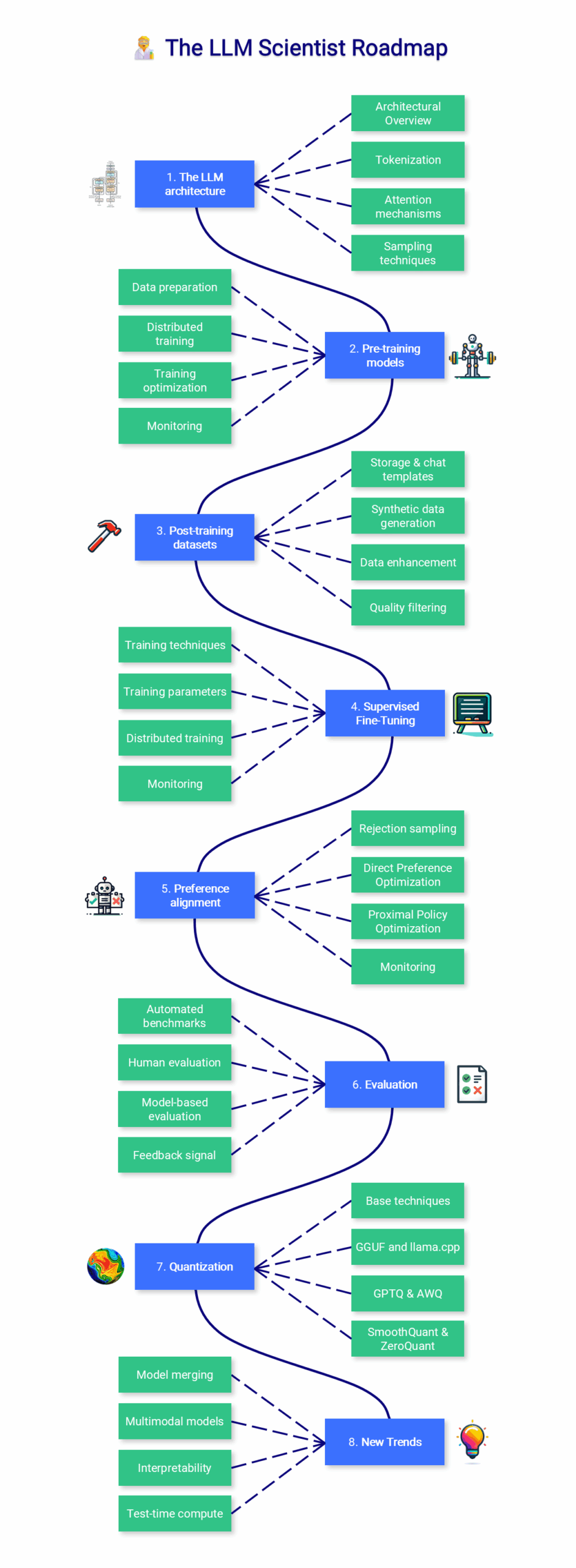
Ключевые модули курса
Архитектура LLM
Раздел охватывает фундаментальные аспекты:
- Эволюцию от encoder-decoder архитектур к decoder-only моделям типа GPT
- Принципы токенизации и их влияние на качество модели
- Механизмы внимания и их роль в обработке контекста
- Стратегии генерации текста: от жадного поиска до температурного сэмплирования
Предобучение моделей
Хотя предобучение требует значительных вычислительных ресурсов, курс дает понимание ключевых аспектов:
- Подготовка датасетов (Llama 3.1 обучалась на 15 триллионах токенов)
- Распределенное обучение с различными стратегиями параллелизации
- Оптимизация процесса обучения и мониторинг метрик
Посттренировочные датасеты
Особое внимание уделяется структурированным датасетам для тонкой настройки:
- Форматы хранения данных и шаблоны чатов (ChatML, Alpaca)
- Генерация синтетических данных с помощью моделей типа GPT-4o
- Методы улучшения качества данных: Auto-Evol, Цепочка мыслей
- Фильтрация качества с использованием reward-моделей и LLM-судей
По материалам Hugging Face





Оставить комментарий