
Оглавление
Компания Google Research представила революционную сквозную модель преобразования речи в речь, которая обеспечивает перевод в реальном времени с сохранением голоса говорящего и задержкой всего 2 секунды. Эта технология преодолевает ограничения традиционных каскадных систем и открывает новые горизонты для естественной межъязыковой коммуникации.
Проблемы традиционных систем перевода
До недавнего времени системы преобразования речи в речь использовали каскадный подход, состоящий из трех этапов:
- Распознавание речи с помощью моделей ASR
- Машинный перевод текста
- Синтез речи через TTS-системы
Несмотря на высокое качество отдельных компонентов, такая архитектура имела серьезные недостатки:
- Задержки в 4-5 секунд, что делало невозможным естественный диалог
- Накопление ошибок на каждом этапе перевода
- Отсутствие персонализации из-за использования универсальных TTS-систем
Инновационная сквозная архитектура
Новая система Google использует принципиально другой подход. Вместо последовательной цепочки обработки применяется единая модель, которая непосредственно преобразует речь из одного языка в другой.
Технологический прорыв заключается не только в скорости, но и в сохранении голосовых характеристик говорящего. Это создает иллюзию, будто человек действительно говорит на другом языке, что психологически важно для комфортного общения. Интересно, смогут ли конкуренты повторить этот результат без доступа к таким же масштабам данных Google.
Ключевые компоненты системы
Архитектура состоит из двух основных модулей:
- Потоковый энкодер: обрабатывает аудиоданные с учетом предыдущих 10 секунд входного сигнала
- Потоковый декодер: генерирует переведенную речь авторегрессивно, используя сжатое состояние энкодера
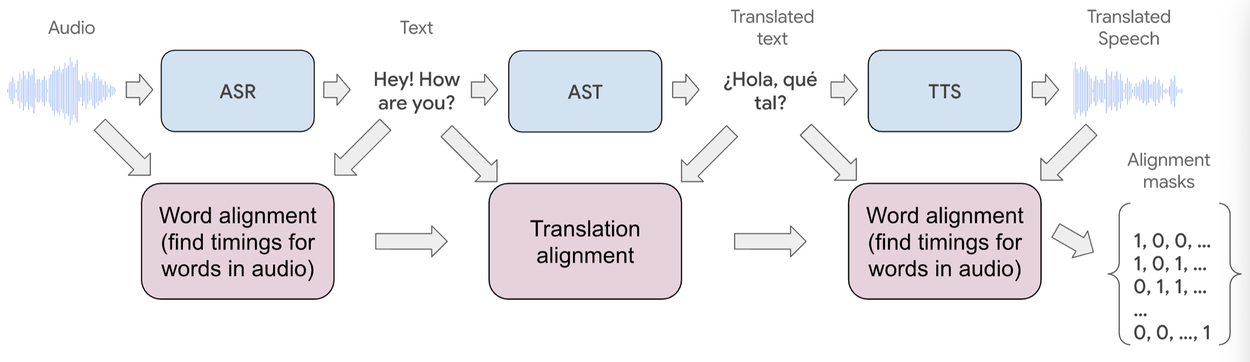
Масштабируемый пайплайн подготовки данных
Для обучения модели был разработан сложный процесс подготовки данных, обеспечивающий временную синхронизацию между исходной и переведенной речью.

Процесс включает несколько этапов:
- Сбор и очистка исходных аудиоданных
- Распознавание речи и принудительное выравнивание временных меток
- Машинный перевод текста с фильтрацией ошибок
- Синтез речи с сохранением голосовых характеристик
- Финальное выравнивание и создание масок совпадения
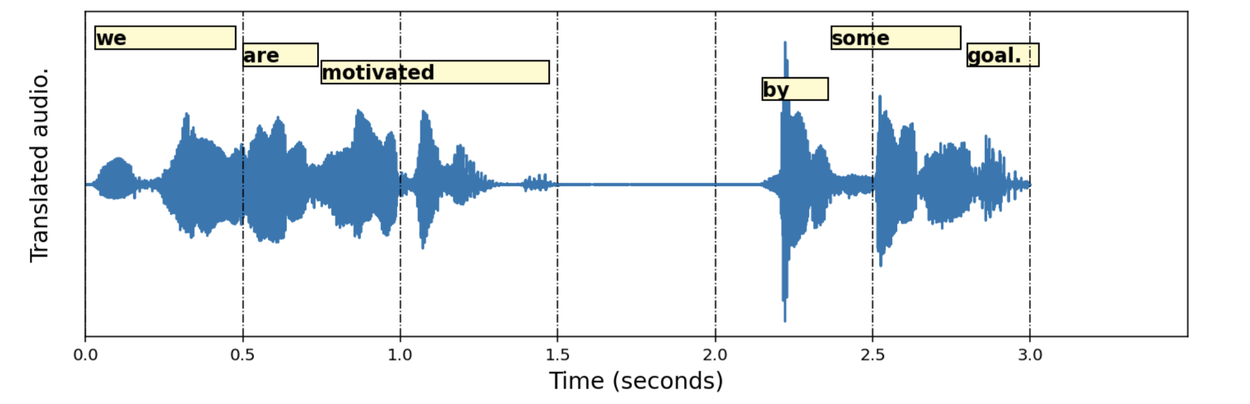
Технические особенности реализации
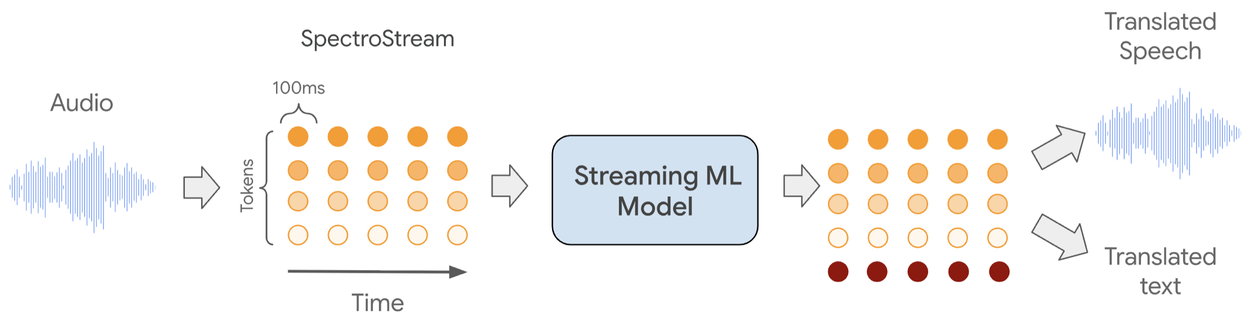
Модель представляет аудио как двумерный набор токенов с использованием технологии RVQ audio tokens. По оси X отображается время, а по оси Y — набор токенов, описывающих текущий аудиосегмент.
Количество токенов определяет качество аудио: 16 токенов достаточно для высококачественного представления 100-миллисекундного сегмента. Модель также предсказывает текстовый токен, который служит дополнительным приоритетом для генерации аудио и позволяет напрямую вычислять метрики качества перевода.
Система уже продемонстрировала свою эффективность в реальных сценариях, где важна минимальная задержка. По сообщению Google Research, технология открывает возможности для более естественного межъязыкового общения в профессиональной и личной коммуникации.





Оставить комментарий