
Оглавление
Сообщество Apache Parquet официально ратифицировало тип данных Variant — нативный формат для работы с полуструктурированными данными, который теперь поддерживается в Delta Lake, Apache Iceberg и Apache Spark. Технология шреддинга позволяет ускорить чтение таких данных в 8 раз по сравнению с обычным Variant и в 30 раз по сравнению с хранением в строковом формате.
Открытый стандарт для полуструктурированных данных
Полуструктурированные данные повсеместно используются в ИИ, логах приложений и телеметрии. Их гибкость всегда была палкой о двух концах: изменяющиеся схемы усложняли хранение и запросы. Традиционно такие данные хранили в строковом формате, что обеспечивало гибкость, но убивало производительность — движкам приходилось парсить и сканировать всю строку целиком.
Variant предлагает принципиально иной подход, храня данные в компактном бинарном формате, который одновременно гибок и эффективен для запросов. Ключевое преимущество — это открытый стандарт, не привязанный к конкретному движку или формату.
Наконец-то индустрия движется от кустарных решений к стандартизации полуструктурированных данных. Variant — это не просто очередной формат, а попытка решить фундаментальную проблему, которая десятилетиями тормозила развитие дата-инжиниринга. Интересно, что именно Databricks, а не один из традиционных вендоров баз данных, возглавила эту инициативу — возможно, потому что они ближе к реальным проблемам больших данных.
Технические детали Variant и shredding
Бинарное кодирование
В отличие от JSON-строк, требующих полного парсинга для навигации по данным, Variant использует эффективную бинарную кодировку со смещениями. Это позволяет обращаться к конкретным полям без обработки всего объекта.
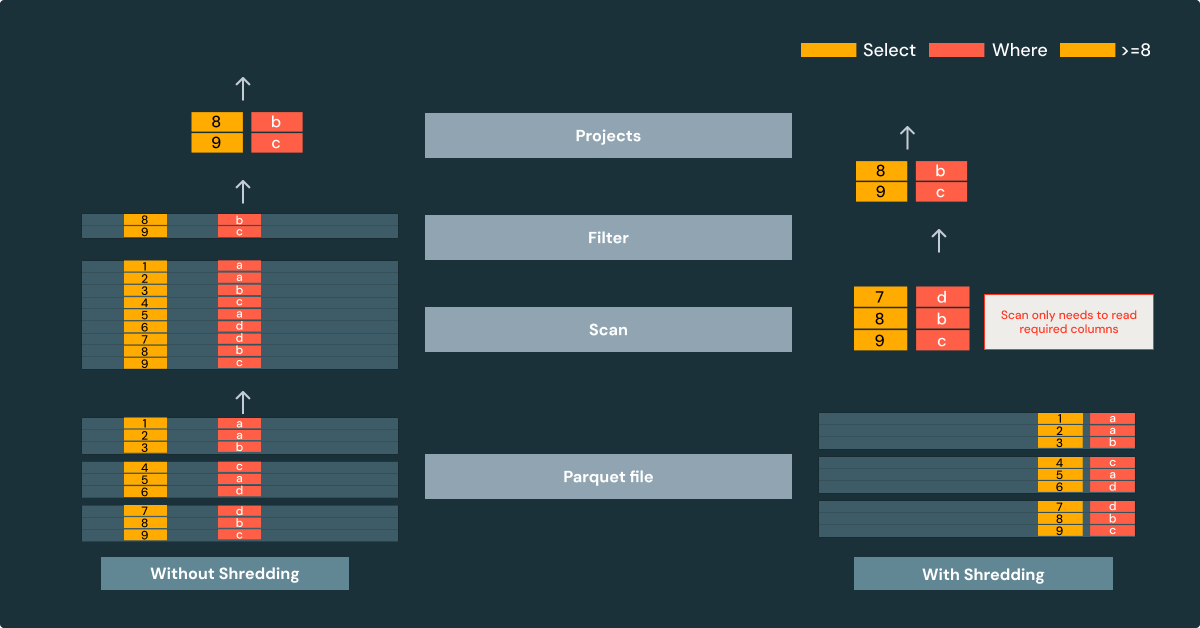
Shredding — автоматическая колоночная оптимизация
Техника shredding автоматически извлекает часто встречающиеся поля из Variant-значений и хранит их как отдельные типизированные фрагменты в той же колонке. Это дает три ключевых преимущества:
- Сокращение операций ввода-вывода: загружаются только поля, требуемые запросом
- Пропуск данных: движки используют статистику Parquet для эффективного пропуска нерелевантных row-групп
- Компрессия: колоночное хранение позволяет лучше сжимать данные
Производительность
Бенчмарки на основе TPC-DS демонстрируют впечатляющие результаты: Variant обеспечивает 8-кратное ускорение чтения по сравнению с JSON-строками, а с shredding — уже 30-кратное. Запись при этом замедляется на 20-50%, что вполне приемлемо для сценариев, где чтение преобладает над записью.

Практическое применение
Создание таблицы с Variant-колонкой предельно просто:
CREATE TABLE sales (ID INT, customer VARIANT);
Загрузка данных поддерживается через специальные функции:
INSERT INTO sales (ID, customer) VALUES (1, PARSE_JSON('{ "name": "person1", "revenue": 5 }'), (2, PARSE_JSON('{ "name": "person2", "age": 22 }'));
Shredding доступен в Databricks с DBR 17.2+ и работает без изменения кода запросов.
По материалам Databricks.





Оставить комментарий