
Оглавление
По сообщению Hugging Face, компания ServiceNow анонсировала открытый фреймворк SyGra, предназначенный для решения одной из самых болезненных проблем в машинном обучении — подготовки качественных данных для обучения языковых моделей.
Проблема данных в современном ML
Когда мы говорим о построении моделей — будь то большие языковые модели (LLM) или малые языковые модели (SLM) — первое, что нам нужно, это данные. Хотя доступно огромное количество открытых данных, они редко поступают в точном формате, необходимом для обучения или выравнивания моделей.
На практике мы часто сталкиваемся со сценариями, когда сырых данных недостаточно. Нам нужны данные, которые более структурированы, предметно-ориентированы, сложны или соответствуют поставленной задаче. Рассмотрим некоторые распространенные ситуации:
- Сложные сценарии отсутствуют — вы начинаете с простого набора данных, но модель не справляется с продвинутыми задачами рассуждений
- Преобразование базы знаний в вопрос-ответ — у вас уже есть база знаний, но она не в формате Q&A
- От SFT к DPO — вы подготовили набор данных для контролируемого тонкого обучения, но теперь хотите выровнять модель с помощью оптимизации прямых предпочтений
- Глубина вопросов — у вас есть набор данных вопросов и ответов, но вопросы поверхностные
SyGra: Единый фреймворк для всех задач данных
Именно здесь на помощь приходит SyGra — low-code/no-code фреймворк, разработанный для упрощения создания, преобразования и выравнивания наборов данных для LLM и SLM.
Вместо написания сложных скриптов и конвейеров вы можете сосредоточиться на инженерии промптов, пока SyGra берет на себя тяжелую работу.
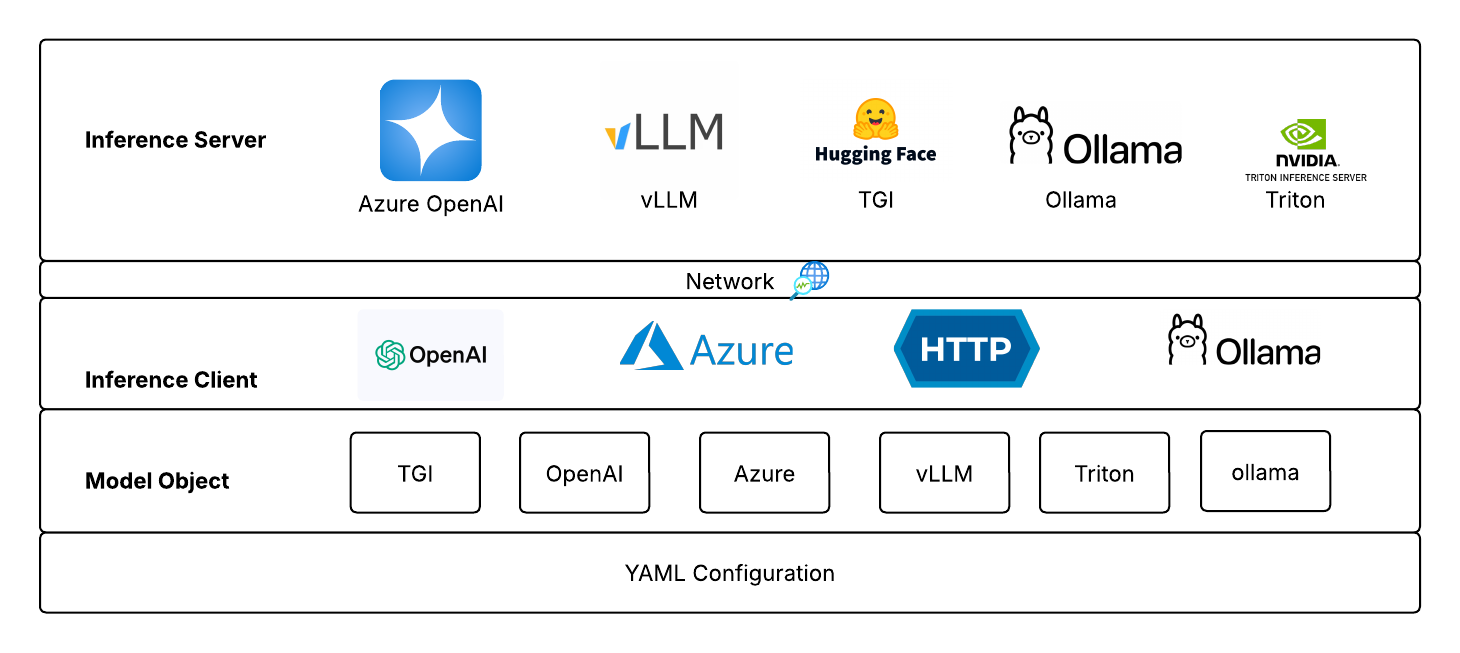
Ключевые особенности SyGra
- Библиотека Python + фреймворк: легко интегрируется в существующие ML-воркфлоу
- Поддержка нескольких бэкендов вывода: работает с vLLM, Hugging Face TGI, Triton, Ollama и другими
- Low-code/No-code: создание сложных наборов данных без серьезных инженерных усилий
- Гибкая генерация данных: от Q&A до DPO, от рассуждений до многоязычных задач
SyGra выглядит как долгожданное решение для инженеров ML, которые устали от бесконечного написания кастомных пайплайнов для каждой новой задачи. Интересно, насколько хорошо он справится с реальными production-задачами, где качество данных критически важно, а требования к задержкам жесткие. ServiceNow явно делает ставку на упрощение ML-разработки — посмотрим, станет ли SyGra таким же стандартом, как Transformers от Hugging Face.
Архитектура и возможности
Фреймворк позволяет ускорить выравнивание моделей (SFT, DPO, RAG-пайплайны), экономить инженерное время с помощью plug-and-play воркфлоу и улучшать надежность моделей в сложных и предметно-ориентированных задачах.
Пример реализации можно найти в официальной документации.
Значение для индустрии
Данные — это фундамент ИИ. Качество, разнообразие и структура ваших данных часто важнее, чем настройки архитектуры модели. Включая гибкое и масштабируемое создание наборов данных, SyGra помогает командам сократить усилия по ручной курации данных и сосредоточиться на том, что действительно важно: построении умных AI-систем.





Оставить комментарий